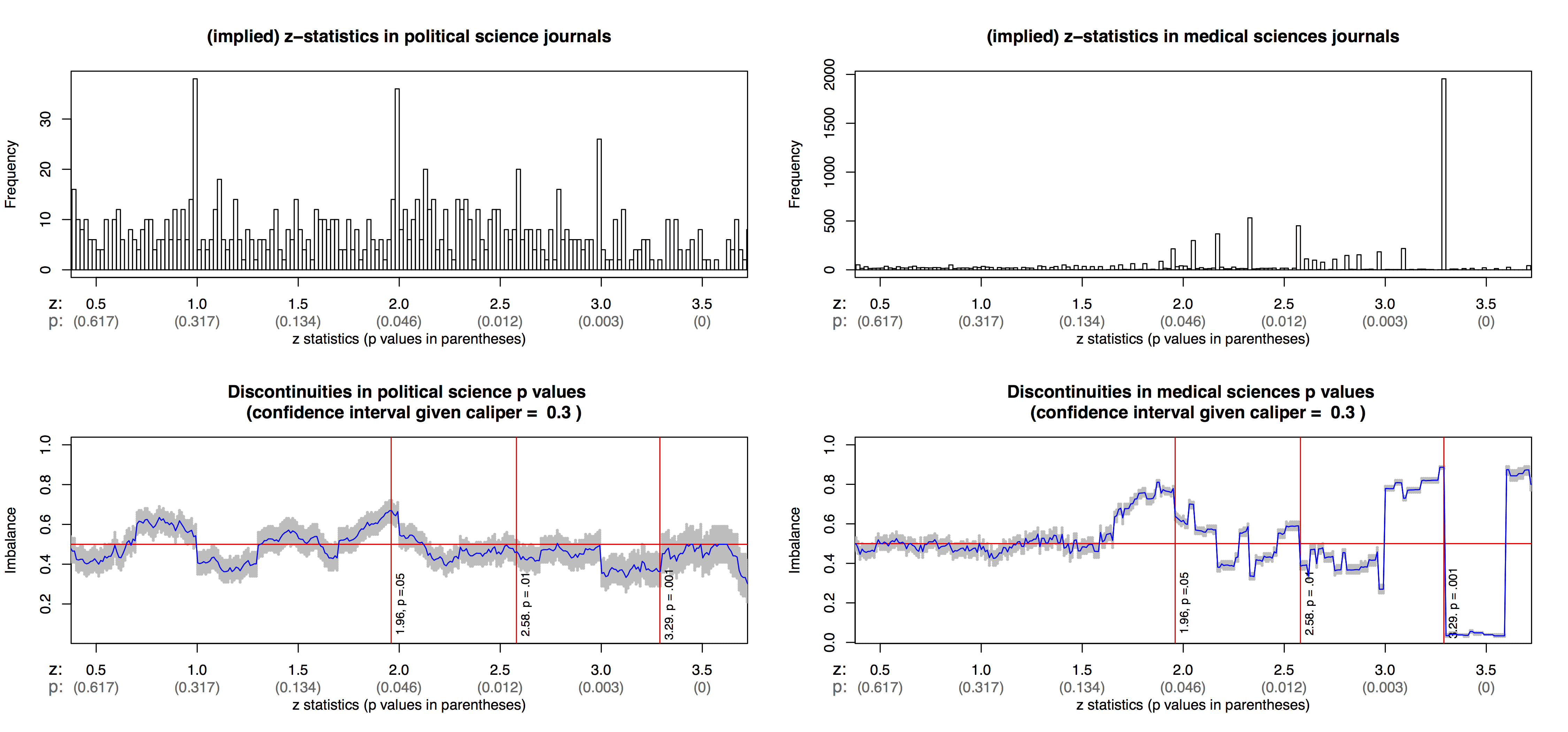
Macartan writes:
There is a lot of worry about publication and analysis bias in social science research. It seems results are much more likely to be published if they are statistically significant than if not which can lead to very misleading inferences. There is some hope that this problem can be partly addressed through analytic transparency. Say researchers said what analysis they were going to do before they do them? Then that removes researcher degrees of freedom to analyze data in ways that might lead to too many significant results. It makes it hard to select some analyses that seem interesting while forgetting others that seem less interesting.
That’s an argument for “research registration.” It is a good argument but there is no evidence that registration really works. We might be able to find some evidence though. Medical journals started requiring registration in 2005. Did that affect the sorts of results that got published in these journals? We plan to find out.
See here for our strategy, which (because there are many equally good ones you might try) we are registering before we implement.
Before we do though, we would love to learn from social science and medical researchers what they expect to see in the data and what they will conclude when we find whatever we find. The puzzle form is here. Send in your guesses about the effects of registration in order to win a prize and extraordinary prestige.
And here’s what it says at the link:
We want to figure out whether the introduction of registration requirements affected the types of statistics published in medical journals. We have the data but we have not looked at it yet. To avoid doing the kind of data fishing that many hope registration will prevent we are registering our analysis plan before we start. See details here https://www.columbia.edu/~mh2245/p/
One innovation of this project is that we want to figure out what we learn about registration relative to current beliefs. What do you expect we will find? Has there been an effect or not?
Here you can give us your best guess for:
(i) the difference in the share of p values just below 0.05 before and after 2005 and
(ii) the difference in the share of all p values below 0.001 before and after 2005.And for the more intrepid we ask that you also provide a full specification of your *prior* (current) beliefs as well as an indication of your belief about the appropriate classical test.
When Macartan sent me the above graphs, I wrote that it appears that the histogram for poli sci papers has spikes just below 1, 2, and 3. And, what are the spikes just below 1 and 3 all about, anyway? There’s something going on here that I don’t understand at all.
To which Macartan replied:
I have been pretty worried about the poli sci spikes at 1, 2 and 3 and they make me wonder about whether the evidence for too much just over 1.96 is largely, or at least in part, an integer spike.
We looked into a set of the 2 spikes and they look like they are coming from rounding; with bs and ses given two two decimal places and z scores imputed from these. eg b = 0.02, se = 0.01 gives z at exactly 2; b = 0.02, se=0.02 gives exactly z=1. Not great.
The medical data spikes at the p numbers, .06, .05, .04, .03, .02, .01, .002, .001, not the z’s since they report the p’s directly.
Ahh, that makes sense. And the apparent peak below the integers could be an artifact of the plotting program, that it takes 2.0 and puts it in the [1.95,2.0] bin rather than the [2.0,2.05] bin, etc.
On thing that bothers me about the “spike just above 1.96” thing is that I feel it puts the focus on the wrong place. After all, suppose that there was no selection around 1.96 but otherwise people did the same thing with garden of forking paths etc. We’d still have all these problems!
Andrew:
About the garden of forking paths, is there any similar empirical test / data derived analysis you would suggest?
Suppose we want to test the speculation that people are indeed doing the same thing with the garden of forking paths. What’s a data based finding to bolster this. Or conversely to weaken this hypothesis.
In other words: In the “garden of forking paths” critique a falsifiable hypothesis?
Rahul:
The garden of forking paths is not a hypothesis. It is a response to a claim coming from outside.
It goes like this: Researcher A gathers data and makes a strong claim that is implausible on general scientific grounds. But, that researcher says that he or she has strong evidence for the claim because a certain p-value is statistically significant.
The “garden of forking paths” critique is merely the response that the reported p-value is, implicitly, a claim that researcher A would have performed the exact same data processing and analysis choices had the data been different.
Typically there is zero evidence that the researcher would have performed the exact same data processing and analysis choices had the data been different. The only evidence will be a claim by the researcher that he or she did only the reported analyses, for the data that were actually observed. The fact that people keep giving this response, is a sign to me that people do not understand the assumptions underlying p-values.
So research framed in terms of classical statistics, such as p-values, needs to play by the associated rules – and in particular the processing should not be contingent on the observed actually observed. Hence: preregistration. Correct?
But in the end, might this entire direction do more harm than good? If someone gathers a rich data set, don’t we want them to be able to look for and report interesting findings – even entirely unexpected ones. Yes, we need tools to make this “safe”, and those tools will not include p-values (at least, not applied naively.) Is a world in which p-values remain the gold standard of research success, only yet further entrenched and constrained by consistently applied pre-registration policies, really the best for scientific progress?
Bxg:
People can do whatever they want. I’ve never preregistered a study in my life. Scientific progress is good too. But I don’t think much scientific progress will occur via “power = .06” studies. The problem is that people take “p less than .05” as an indication of scientific discovery or truth. The “garden of forking paths” critique is relevant because, without this critique, you have people insisting that the statistics show that they’ve made discoveries. When someone does a “power = .06” study, I do not recommend preregistered replication; what I recommend is that the measurement process be improved. If people want to make scientific progress, they should be using reliable and valid measurements. All the methodological and statistical rigor in the world won’t help if you’re measuring the wrong thing and in a noisy way.
“The “garden of forking paths” critique is merely the response that the reported p-value is, implicitly, a claim that researcher A would have performed the exact same data processing and analysis choices had the data been different.”
So the objective/frequentist theory rests on the assumption that the researchers state of mind wouldn’t change if we lived in a universe that yields different data than the one we currently live in?
What if there are two researchers working on a project and one of them would analyze the data the same no matter what, and one wouldn’t? Is the p-value valid then?
“The “garden of forking paths” critique is merely the response that the reported p-value is, implicitly, a claim that researcher A would have performed the exact same data processing and analysis choices had the data been different.”
What if on the day the researcher did the analysis they wouldn’t have analyzed it different for different data, but a year later they changed their mind and now would analyze different data differently? Note their analysis of the data actually seen hasn’t changed at all.
Does the p-value go from being valid to invalid?
If so here’s another reform for statistics: track the psychological state of researchers, and whenever they change on their minds on how they’d would have analyzed un-seen data their original work is thrown out.
+1 for the psychological state suggestion. :)
Anonymous:
The concern is about intentions not regrets – what would have been done in the process of generating and bringing forward something as evidence. Such a process can never be _objective_ (i.e. not depend on the individuals involved) nor can that past process to be modified afterwards (barring time travel).
So if they would’ve analyzed data that doesn’t exist differently before, then the p-value is bad. If they would’ve analyzed the data doesn’t exist differently after but not before, then the p-value is good. Got it. Makes sense.
According to their Analysis section, Humphreys et al. are going to do a regression discontinuity with time as the forcing variable (although they don’t describe it in those terms). RDs in time can be great – see Anderson’s recent paper on traffic and the LA transit strike – but you really need data to be observed at a finer time scale than a year in order to get compelling results. In order to buy that they are estimating the true effect size we have to believe that nothing else changed during 2005 besides pre-registration. That assumption is much easier to defend if we can see a jump happening on a specific day, as opposed to over the course of an entire year.
You don’t have to call it an RD or use sophisticated RD methods in order for this to be true – the point is that you can’t make the data tell you more than it actually shows, and if they only have year of publication then it’s tough to know exactly what is going on.
A few thoughts on why else an RD or single-difference type method might not work great:
I would imagine that referees and editors used to using “p<.05" as (at least one of multiple) criteria for acceptance might not immediately decide "oh, pre-registration, so, I'll agree to accept anything that is well-powered.". In that case, the RD* wouldn't show anything (even with really dense observations around the policy timing**) – what would happen is that different kinds of articles would get accepted to the registration-only journals, but the distribution of p-values/z-scores in those journals would not change much. If power calcs are still built for p=.05, and researchers really do know something about effect sizes, then you'd still expect some heaping right around there, and some serious hollowness to the left. The distribution would perhaps would be a bit less spiky right at the cut-off, but there would still be nothing to the left of it.
I also notice that the authors list a few journals that agreed to the standards, and limit their analysis to those journals. I'd say there is probably useful information in the other journals too, as a kind of control group that should not be (or be differently) affected by pre-registration. Now of course, you could imagine that the Lancet now only publishes articles that are BOTH pre-registered AND statistically significant, and the pre-registered studies that find no significant effect***, or the non pre-registered studies, now shift to other journals and "contaminate the control group". But this is a general equilibrium effect that might be really interesting: nothing changes in the whole literature, it is just a re-organization of what gets published where, with pre-registered and significant studies going to the high-end registration-only journals, and the rest being re-distributed among lower-tier journals. It is not clear to me that a single-difference in time estimate will really capture this effect at all.
I think a great place to look might be at the "registered reports" which journals agree to publish beforehand based on the topic, experimental design, and analysis plan. Those should have fundamentally different distributions of p-values. Another way (which might not be feasible/measurable in any real sense) would be to look at what kinds of studies (how interesting, how important, what topics) get published in the registration-only journals before/after the policy: it could be that they are now publishing less interesting (in topic at least) work, because some of the interesting, pre-registered studies "failed" to find significance****.
* I really dislike "RD in time". It is just an instantaneous first-difference. An "event study", where one has "treatment" that hits at different points in calendar time and thus can non-parametrically absorb time effects is a much more convincing method in most cases, though not really possible here.
** I agree with Jason that that is a really important point here.
*** just don't say they "didn't work".
**** for real, it isn't that they "didn't work", nothing "failed" here, but somehow that language is getting really common, and I am currently aggravated about it for some reason, so I'm venting.