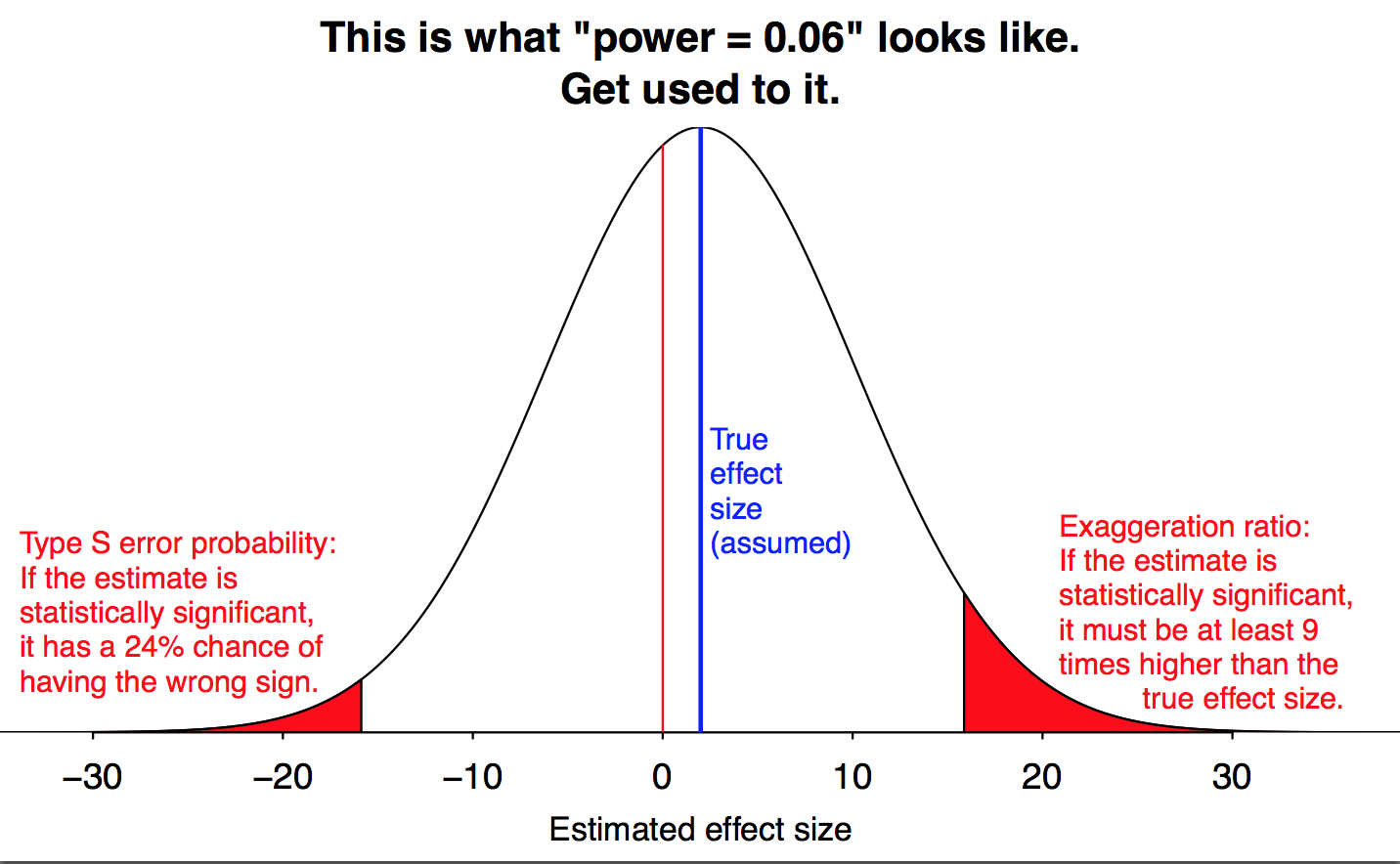
I prepared the above image for this talk. The calculations come from the second column of page 6 of this article, and the psychology study that we’re referring to is discussed here.
I prepared the above image for this talk. The calculations come from the second column of page 6 of this article, and the psychology study that we’re referring to is discussed here.
Scary indeed. Extreme, mind you, because everyone thinks they have 80% power, and usually they do have more than 6%. But yes, it is scary. Graphs like these should more frequently be part of the discussion on power and ethics where the usual emphasis is on wasting resources and exposing human subjects to unnecessary risks due to poorly thought out designs. All valid concerns, but also what about the distorting effects of low power on the scientific reporting? The sampling distribution for effect sizes here conditional on p < .05 has nothing whatsoever to do with the true distribution. Well, I guess ideally a meta-analysis (and access to file drawers) could eventually trace out the shape of the sampling distribution. That will only happen after a lot of confusion and misdirection, and many many tabloid headlines.
If we have no idea what effect to expect, so effect=0 is the null hypothesis used, what exactly can one learn from the p-value? According to that chart, if we observe a p<0.05 result with effect size of +/-20 we can't say much at all. Perhaps that is near the "true" effect size, or maybe the real one is near zero, or perhaps it's in the totally wrong direction.
If we do expect a certain effect size (or there is one of "practical significance") then shouldn't that be the null hypothesis?
Question,
I think you want to consider this graph as a thought experiment. Suppose the real effect is small, but we also have small N and high variability in the outcome. Then, if you do find some difference in means that is statistically significant, it IS an over-estimate of the true effect. I remember realizing this last year when I did a lecture on power calculations and thought: wow, that is an interesting perspective to think about, particularly in relation to these N=20 type experiments Andrew has been talking about so much.
jrc,
Right, but in real life we only have the observed effect. That chart suggests an observed effect of ~20 is consistent with very small true effect. Of course we are more likely to observe an effect of 20 if the true effect is near that value. However, if we do not know how much “filtering” has gone on then it is not really possible to distinguish between the two (small vs large effect) scenarios. It seems that under conditions where that chart is relevant to research practice, then the p-value calculated using effect=0 cannot be meaningful.
This reminds me of the following discussion:
“As I hope is clear from our example, NHST as a method depends upon a faith in the perfection of our fellow researchers that will easily fall victim to any mixture of incompetence or malice on their part. Unlike a descriptive statistic such as a mean, a p-value purports to tell us something that it cannot do without perfect information about the exact scientific methods used by every researcher in our community. An individual researcher will necessarily have this sort of perfect information about their own work, but a community will typically not. The imperfect information available to the community implies that reasoning about the community’s ideal standards for measuring evidence based on the ideal standards for a hypothetical individual will be systematically misleading.”
https://www.johnmyleswhite.com/notebook/2012/05/10/criticism-1-of-nhst-good-tools-for-individual-researchers-are-not-good-tools-for-research-communities/
Question:
You write, “in real life we only have the observed effect.” No! In real life we typically have a lot more information. That’s the point of my paper with Carlin, and indeed of the above example. The hypothesized effect size of 2 percentage points (which really is more of a hypothesized upper bound on the effect size) comes from substantive information on public opinion and voting, external to (in statistical terms, “prior to”) the observed effect from that particular study.
Andrew,
In that case, what justification is there for calculating this p-value in the first place? If you have a point prediction, why not test that (here: the hypothesis that mean(a)-mean(b)=2)? If the p-value is low we would say “our effect size was such and such, however this data does not appear consistent with the previous literature”. If the p-value is high we could say “our effect size was such and such, which is consistent with what we would expect from the literature”.
Question:
You ask, “In that case, what justification is there for calculating this p-value in the first place?” I think there is no good justification! What I’m doing here is commenting on people who do compute these p-values, as in the paper discussed in the references. My whole point is that the study in question is pointless!
Ha. Ok then. As far as I can tell, it is _always_ misguided to filter results by rejecting a strawman. Your chart seems to suggest there is some other case for which that procedure can be useful. I am interested in examples of those.
Question:
When effect size is large and bias and variance are low, I think the p-value can be a useful summary, if interpreted carefully. When effect size is low and bias and variance are high, I think the p-value can be super misleading, which was the point of my graph.
The graph doesn’t really stand alone; it’s a response to all those “Psychological Science”-style studies we’ve been talking about here for the past few years.
“When effect size is large and bias and variance are low, I think the p-value can be a useful summary, if interpreted carefully.”
Yes, I agree. Michael Lew’s paper here convinced me of that: https://arxiv.org/abs/1311.0081
It is the combination of a strawman with the concept of “statistical significance” (ie the filtering step) that seems to be a problem, not the p-value per se.
Question:
Yes, this comes up a lot. I agree that the problem is with null hypothesis significance testing, not with p-values. If you do null hypothesis significance testing in other ways (for example, using Bayes factors), the same problems arise.
This really explains part of the scale up problem, i.e. that some pilot study finds an effect size with p<.05 on a smallish sample, then the intervention is implemented at other sites and it turns out to have a much smaller effect. Usually I attribute that to less investment in the intervention, less compliance with the original protocol, inevitable compromises on the ground but really, maybe it is just an artifact of overestimation.
Pingback: Friday links: on live tweeting talks, measurement vs. theory, #myworstgrade, and more | Dynamic Ecology
Pingback: Somewhere else, part 186 | Freakonometrics
Pingback: Artist needed! - Statistical Modeling, Causal Inference, and Social Science Statistical Modeling, Causal Inference, and Social Science
Pingback: What hypothesis testing is all about. (Hint: It's not what you think.) - Statistical Modeling, Causal Inference, and Social Science Statistical Modeling, Causal Inference, and Social Science
Pingback: Type-S and Type-M errors | The Etz-Files
Pingback: Friday links: RIP Oikos Blog (?), Stephen Heard vs. an English department, and more | Dynamic Ecology
Pingback: Impact of Social Sciences – To understand the replication crisis, imagine a world in which everything was published.
Pingback: Why doesn’t personality psychology have a replication crisis? | funderstorms
Personality psychology is anything but precise and though they claim to care about effect sizes, they don’t actually care about effect sizes:
https://www.pbarrett.net/publications/Rethinking_reliability_and_validity_of_Psychological%20Measurements_Barrett_Prinsloo_2013.pdf
Though some do and they are trying to change the way in which the field approaches the problem.
Everyone else seems to be defending the intellectually indefensible.
Pingback: Thinking more seriously about the design of exploratory studies: A manifesto - Statistical Modeling, Causal Inference, and Social Science
Pingback: The "What does not kill my statistical significance makes it stronger" fallacy - Statistical Modeling, Causal Inference, and Social Science
Pingback: Again: Let’s stop talking about published research findings being true or false - Statistical Modeling, Causal Inference, and Social Science
Pingback: This Is What “Power = .006” Looks Like. | Math Thoughts
Pingback: The "80% power" lie - Statistical Modeling, Causal Inference, and Social Science
Pingback: An Upbeat Mood May Boost Your Paper's Publicity - Statistical Modeling, Causal Inference, and Social Science
Pingback: Friday links: insulting fish, how to pronounce “niche”, and more | Dynamic Ecology
Pingback: Friday links: statistical significance vs. statistical “clarity”, philosophy of science vs. cell biology, and more | Dynamic Ecology
John Tukey used to set alpha to 0.10 because if he was wrong to make a decision he would still get the direction correct half of the time by chance. Was he wrong? The graph shows that Type S error risk is not half of a two-tailed alpha. Should we be making directional decisions based on a lifelong risk of Type S errors instead of p values?
I get it now. Half of alpha is the worst case scenario.