Aki points us to this discussion from Rolf Zwaan:
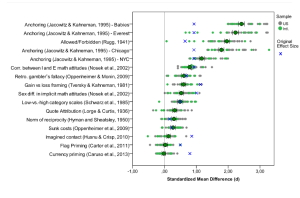
The first massive replication project in psychology has just reached completion (several others are to follow). . . . What can we learn from the ManyLabs project? The results here show the effect sizes for the replication efforts (in green and grey) as well as the original studies (in blue). The 99% confidence intervals are for the meta-analysis of the effect size (the green dots); the studies are ordered by effect size.
Let’s first consider what we canNOT learn from these data. Of the 13 replication attempts (when the first four are taken together), 11 succeeded and 2 did not (in fact, at some point ManyLabs suggests that a third one, Imagined Contact also doesn’t really replicate). We cannot learn from this that the vast majority of psychological findings will replicate . . .
But even if we had an accurate estimate of the percentage of findings that replicate, how useful would that be? Rather than trying to arrive at a more precise estimate, it might be more informative to follow up the ManyLabs projects with projects that focus on a specific research area or topic . . . So what DO we learn from the ManyLabs project? We learn that for some experiments, the replications actually yield much larger effects that the original studies, a highly intriguing findings that warrants further analysis.
We also learn that the two social priming studies in the sample, dangling at the bottom of the list in the figure, were resoundingly nonreplicated. . . . It is striking how far the effects sizes of the original studies (indicated by an x) are away from the rest of the experiments. . . .
Most importantly, we learn that several labs working together yield data that have an enormous evidentiary power. At the same time, it is clear that such large-scale replication projects will have diminishing returns . . . rather than using the ManyLabs approach retrospectively, we can also use it prospectively: to test novel hypotheses. . . .
P.S. It’s also worth reading this long and detailed discussion from Tal Yarkoni.
Pingback: Science and It's Logic
One technical point I haven’t seen discussed but I’m wondering about: how come the effect sizes for the original studies mostly fall within a relatively narrow range? Much narrower than the range of effect sizes from the ManyLabs replication, but centered on about the same grand mean. Is that just happenstance? Is there some obvious explanation I’m missing?
What is replication? If the intent of research is not just to reject null hypotheses, but to measure the size of the effects then it looks like 9 of the 16 original experiments were quite at odds with the replications.
The discrepancies in the top four experiments look just as striking as the bottom two priming experiments, so it seems wrong to focus on whether the meta-analysis confidence interval includes zero to declare that the top four were successfully replicated and the bottom two were not.
Back in the day, when the speed of light was measured instead of defined, if I measured 300,000 km per second and you measured 250,000 km per second, I would not call your experiment a successful replication of mine merely because you hadn’t measured the speed to be zero.
PAUL E. MEEHL
THEORY-TESTING IN PSYCHOLOGY AND PHYSICS: A METHODOLOGICAL PARADOX
Philosophy of Science, 1967, Vol. 34, 103–115.
https://mres.gmu.edu/pmwiki/uploads/Main/Meehl1967.pdf
Sorry, here is the abstract to pique interest:
Abstract:
“Because physical theories typically predict numerical values, an improvement in experimental precision reduces the tolerance range and hence increases corroborability. In most psychological research, improved power of a statistical design leads to a prior probability approaching ½ of finding a significant difference in the theoretically predicted direction. Hence the corroboration yielded by “success” is very weak, and becomes weaker with increased precision. “Statistical significance” plays a logical role in psychology precisely the reverse of its role in physics. This problem is worsened by certain unhealthy tendencies prevalent among psychologists, such as a premium placed on experimental “cuteness” and a free reliance upon ad hoc explanations to avoid refutation.”
Experimental ‘cuteness’. LOL Yes the qualitative side, in psychology, is already weak. ‘And weakened with increased precision’
I downloaded the spreadsheet with a lot of detailed data (from https://osf.io/rn4ue/files/). There’s a lot of interesting things in there that aren’t apparent at first sight. The four anchoring experiments were all given the same original effect size, since the replicating project couldn’t separate them using the original paper. So you can’t use that information to compare replication of the individual studies with the originals. And then the replications of those four experiments came out way higher than the originals. But then, they didn’t really perform the same experiment when they replicated these ones. So set them aside for now.
Then another one gave results way higher than the original – way out of line, as can be seen in several ways. That makes it seem like this replication also was essentially a different experiment. So I set it aside, too.
As for the rest, looking at the mean scores for both the condition and control branches across all the replicating labs, there is a rather large variation from lab to lab, but for a given lab, if the condition branch mean is, let’s say, quite high then so is the control branch mean. For some of the experiments the correlation is very high. It’s as if the labs all used different rulers to measure a length. Differences in lengths may be correct but the absolute lengths themselves are biased. This is interesting, since the absolute values of the means are clearly not random samples around a single cross-lab population.
Put another way, much of the individual spread you see in the replicated results – like that nice graph in the post above – are not caused by statistical fluctuations but by some real difference in the labs’ procedures. This starts to give you some sense of how much any one paper from one lab can be quite far off, despite a statistical analysis that might seem otherwise, and for no obvious reason.
Looking across all the reported results (less the ones I omitted as discussed above), the effect sizes and standard deviations are considerably larger for the originals than for the replications. Judging by the CDFs, both original and replication effect sizes seem reasonably normal. The replication variances (of the effect sizes) is considerably smaller than for the original studies, but not by a factor sqrt(N), only a factor 1/1.4 approximately. Presumably, then, we are seeing additional variance introduced by the biases I talked about above.
Fitting a linear least squares line to the data, there is a relationship between original and replicated values, but not a slope of 1 as one would like. The slope is about 0.4 instead.
So there is a lot in this data if you want to look harder at it.
Tom: Thanks and I agree the lots to learn is in the details – and that takes time I don’t want to spend right now.
(This would make a great resource for a grad course or seminar on meta-analysis or multi-source analysis if those exist anywhere.)
Some quick points:
It was planned and co-ordinated so replications in the multi-sources here (other than original study) are an upper limit – many of the usual insurmountable problems with “found published studies” are being avoided.
Why are they using effect size measures – did they not co-ordinate to use the same outcome measure?! (weird)
> there is a rather large variation from lab to lab, but for a given lab, if the condition branch mean
That is as expected (e.g. noted in L’Abbe, Detsky & O’Rourke https://www.ncbi.nlm.nih.gov/pubmed/3300460 )
The glimmer of hope in meta-analysis or multi-source is that some thing is common not all things. Usually a measure of treatment effect (e.g meanTreat – meanCont or meanTreat /meanCont) is hoped to be common or common in distribution (random effect). Replication is the should be common in some sense – so was it question.
I would be interested in how the group SDs differ as its only when they don’t differ that effect sizes are readily interpretable.
1. I think what is brilliant about this is how it disarms the “you can’t publish a critical study or non-replication”. For sure, you can if you have this sort of expansion of scope/numbers.
Someone before talking about how to take on a study, by first broadening. For instance, say a chemical makes mice die. Well I test rats. It doesn’t make rats die. Then I go back and test mice. They don’t die either. I’m convinced that journals will accept this much faster than a retest of mice. It’s worth doing even just to make people comfortable. Somehow feels different than a pure he said, she said. And like failing to replicate out of scope almost gives an excuse to take on the earlier study. You shouldn’t need it, but we are social animals…
2. I think this is positive for replicatrion advocates. It doesn’t matter that many studies replicated. I think 11 of 13 is pretty low for fundamental papers (not obscure ones). In physics or chemistry, all fundamental effect papers will replicate (or 99%+). What matters more is the above point and also that it shows so many people working together and replicating together. Very upbeat and helpful in taking on the replication-avoider crew in life science and psychology. [I don’t think anyone in crystallography for instance would deny the norm of recalculating a structure and exposing a mistaken structure…)
Nony, Did 11 of 13 really replicate? Or is this just redefining “replication” to mean “significant effect in the same direction”. This is a much weaker definition of replication than has been used historically. See Jonathan Gilligan’s post above and Paul Meehl’s discussion of this problem 40 years ago. The quality of evidence as well as replication have been diluted when it is based on disproving an implausible null hypothesis.
What to do instead? Measure carefully and describe in as much detail as possible until you have a theory capable of precise predictions. If people insist on statistically testing these weak directional or correlational hypotheses, fine that doesn’t really matter. However it is preventing them from describing their results properly which is necessary for someone to come up with strong theories. These fields are simply in the exploratory stage right now, there is no theory worth confirming/rejecting, and the data should be treated consistent with this state.
@K? O’Rourke: “I would be interested in how the group SDs differ as its only when they don’t differ that effect sizes are readily interpretable.”
From the spreadsheet, the control and effect groups generally had fairly equal variances. The authors did both weighted and unweighted analyses, and that didn’t make much difference either.
Just got this in from JEP:G, a very well-respected psych journal.
Call for Replication Studies Papers
The Journal of Experimental Psychology: General is inviting replication studies submissions. The Journal values replications and may publish them when the work clearly contributes to its mission. This includes contributions with interdisciplinary appeal that address theoretical debate and/or integration, beyond addressing the reliability of effects.
The Journal preference is for replication plans to be submitted to the Journal before data collection begins. A proposal should provide a strong motivation for the study in the context of the relevant literature, details of the design, sample size, and planned analyses. The editorial team may encourage a replication project, based on external guidance. Final manuscripts will be evaluated through further external review. Submit through the Manuscript Submission Portal (https://www.apa.org/pubs/journals/xge) and please note that the submission is a proposal for replication. Replication articles will be published online only and will be listed in the Table of Contents in the print journal.
Questions can be addressed to the Editor, Isabel Gauthier ([email protected]) or to the Editorial Associate, Jennifer Richler, ([email protected]).
Editorial Office
Pingback: The backfire effect: numerous failures to replicate | 出る釘は打たれる