Trey Causey asks, Has R-help gotten meaner over time?:
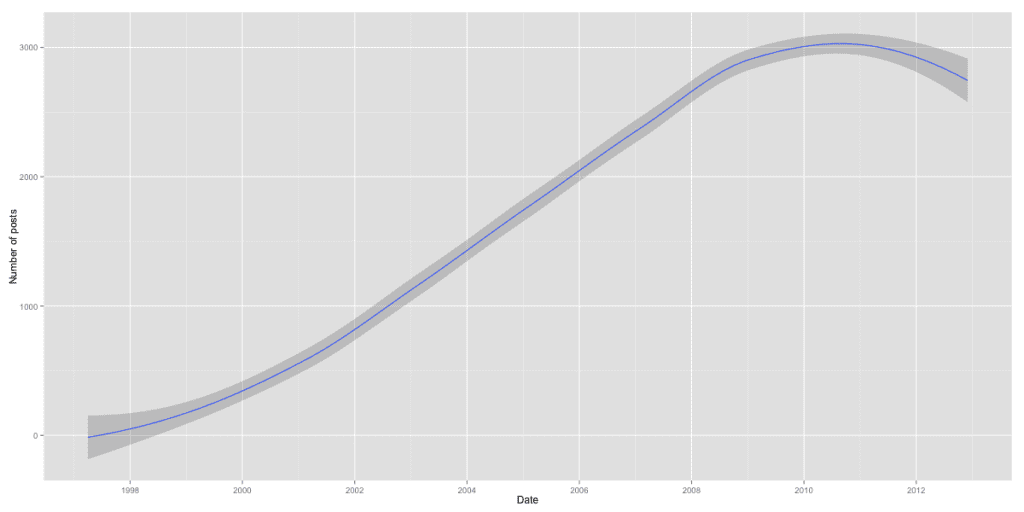
I began by using Scrapy to download all the e-mails sent to R-help between April 1997 (the earliest available archive) and December 2012. . . .
We each read 500 messages and coded them in the following categories:
-2 Negative and unhelpful
-1 Negative but helpful
0 No obviously valence or request for additional information
1 Positive or helpful
2 Not a response
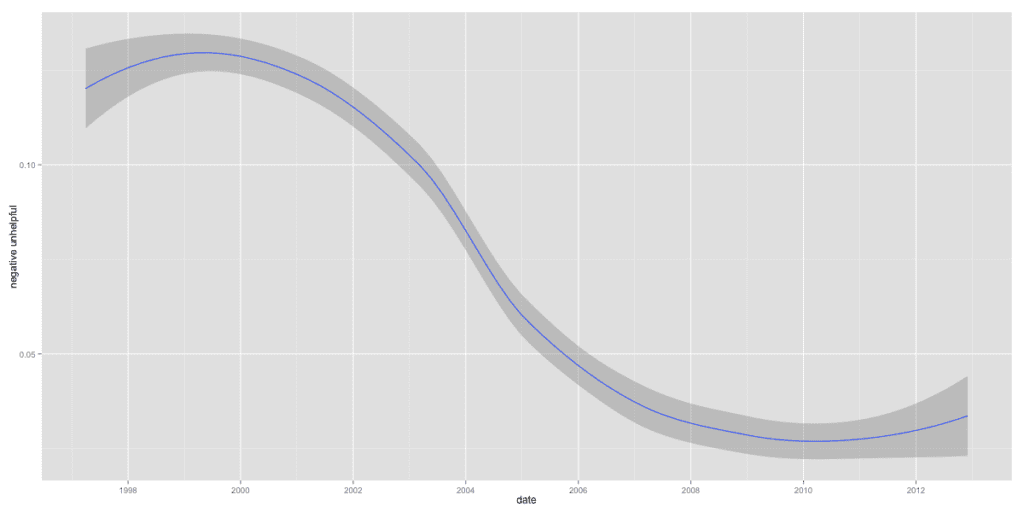
An example of a response coded -2 would be responses that do not answer the question, along with simply telling the user to RTFM, that they have violated the posting guidelines, or offer “?lm” as the only text when the question is about lm(). . . .Proportions of emails in each category in the test set were estimated on a monthly basis. Much to my surprise, R-help appears to be getting less mean over time! The proportion of “negative and unhelpful” messages has fallen steadily over time, from a high of 0.20 in October of 1997 to a low of 0.015 in January of 2011. . . .
Let’s return to the puzzle of falling meanness, somewhat stable helpfulness, and growing numbers of unanswered questions. . . . R-help is essentially a public good. Anyone can free ride by reading the archives or asking a question with minimal effort. It is up to the users to overcome the collective action problem and contribute to this public good. As the size of the group grows, it becomes harder and harder to overcome the collective action problem . . . Maintaining the quality of the public good requires individuals willing to sanction rule-breakers. This was accomplished in early days by chiding people about the content of their posts or generally being unpleasant enough to keep free-riders away. As the R user base grew, however, it became more and more costly to sanction those diluting the quality of the public good and marginal returns to sanctioning decreased. Thus, we get free-riders (question askers) leading to unanswered question and a decline in sanctioning without a concomitant increase in quality of the good.
Interesting combination of descriptive data and social-science speculation. I like it. I just have a few thoughts:
– It would make sense to check the performance of the classifier by taking a random sample of a couple hundred messages, hand-coding them, and comparing to their classifications.
– It might also make sense to break up the data into two or three periods and run the classifier separately on each, just in case other aspects of the messages are changing which could confuse the classification algorithm.
– It would make sense to compare to other lists. For example, maybe the relevant statistic is the number of mean posts, not the proportion. This would be the case, for example, if just one or two of the list participants are providing all the negative feedback. These posters have some finite amount of time they can spend on this, so when the list gets larger they represent a smaller proportion of the whole.
The Ripley paradox
Let me conclude by briefly exploring the ethical issues raised by Causey in his post. Being mean isn’t so nice, but it can be an effective way of helping the list function better, thus serving the public good. Contributors to lists can often seem snappy and downright nasty, but they’re really being altruistic. They may be a bit mean because they’re tired after answering the same questions over and over for a decade, but they’re ultimately helping people out.
The downside of these mean commenters is sometimes they seem sooooo eager to give snappy answers to stupid questions, that I fear that they go out of their way to answer the easy questions and skip out on the toughies. You might say I do the same thing on the blog, sometimes. I’ll read a serious comment and respond only with a +1 or not even that, whereas I’ll go endlessly back and forth with trolls. There’s some way in which correcting error seems so urgent, while more serious exploration can wait.
So, I appreciate the years of unpaid service that these volunteers have put into the R help list, and as far as I’m concerned, they can be as crabby as they want for as long as they want. I hope we can work out a better system so they can be even more effective and so that they don’t feel they need to waste so much of their time on the easy questions.
Many people believe that the “better system” is StackOverflow. (Which now probably gets as many R questions per day as r-help, quite possibly more.)
+1, and note that some r-help veterans are now very prolific on stackoverflow/crossvalidated.
On most good mailing lists all the RTFM’s I’ve ever seen were completely justified. So I wouldn’t necessarily associate an increasing number of RTFM’s with meanness.
This is great social network data.
Another issue you see is that the number of non-developers answering questions goes up over time if a piece of software becomes successful, because there are more experts in it who have used it enough to be able to recognize questions and diagnose problems. You also see the level of the average question go down as the software gets assigned in classes rather than being picked up by specialists.
The qualitative effects of scale would be another interesting area to study. Tiny mailing lists and communities seem very different in flavor to something massive like R.
Sites like StackOverflow are very interesting to me in the way they organize the questions into threads, allow some moderation, and include voting so you can rank answers by “helpfulness”.
It’s also great library-science and search data.
As traffic grows, so does the search problem. It makes it more likely that there is an answer to your question. But it makes it harder to find that answer among all the other answers, especially if the software changes over time. There are just more false positives in the search. And true positives with non-responsive answers, like “that’s a good question”. And if you’re on Google, this is only amplified by mirrors with an advertising business model. (Even academic papers have this problem — too many library-type organizations trying to be helpful, polluting search results.)
The best way forward is to design better tools, with more coherent designs. That makes them easier to doc and understand. But there’s the inevitable push to complexity to eke out more expressive power or efficiency or both, such as moving from coding in C to C++, or from basic Python to numpy or cython, or from R to plyr or ggplot2. Sometimes, as with ggplot2, it’s actually easier to use the new thing than the old thing, but that kind of improvement seems to be rare.
One key aspect of SO, aside form the nice interface, is their gamification strategy.
I recently read this comment from a professor to a student who came into his office asking for help:
Professor: “You’re having trouble with this problem because you don’t know anything and you’re not working very hard.”
Source: https://to.ly/mkoc
How is that for crabby? Consider this guy is actually paid to answer questions….
He’s not paid to answer questions. He’s paid to make the student learn.
+1
See
https://r-project.markmail.org/
for a nice statistics on the number of questions on R-Help. There is a marked decline after 2010 presumably caused by SO entering the market.
One of the problems of R-help is caused by the (in my opinion) bad habit of quoting everything in the reply, because some of the big shot seem to be unwilling to use a thread reader or some nabble-like interface.
In 2001, when still a youngsteR, I replied to one of Brian Ripley’s (helpful) posts. Being well-educated by the LaTeX list, where truncation is considered a must, I reduced his quote to two sentences. I got a nasty email telling me that I had not quoted him completely, followed by the usual sermon that anyway nobody values the R-core (=his) contributions. After that, I started the bad habit of “never-truncate”.
There is too much wasted bandwidth on R-help. StackOverflow has done it right by stopping this habit with brute force.
Dieter
“There’s some way in which correcting error seems so urgent, while more serious exploration can wait.”
Yeah, in other words, the “duty calls” effect: https://xkcd.com/386/ ;-)
Have to disagree with you on this one. I too “appreciate the years of unpaid service that these volunteers have put into the R help list”, but many of the nasty replies cross over the boundaries of the very posting guide they quote a lot – Ripley in particular has posted many replies with personal attacks in them (as he would say – read the posting guide)
What you see as an “easy” question is often very hard for a beginner. R is a very large, complex and daunting system to a newbie, with a programming paradigm that is unfamiliar to many. The documents are Unix style docs, which in my experience are very useful as a reference once you already understand things, but are useless otherwise. R is a “victim” of its own success. With success comes a greater volume of questions, and a greater number of questions from real newbies who are confused. But if success and adoption of what you are doing are your aims, than these requests should be encouraged, and properly guided, rather than trashed (other than of course the obvious ones trying to have their homework done for them).
And in case you think I am being totally glib, we run a number of data services making oceanographic and meteorological data available worldwide. We get a lot of requests for help and a lot of questions about the data and services (we get about 1 million data hits a day also), and many of these come close to being brain dead. We are a very small group and are stretched just to keep the data updated and the services running, and also have been a “victim” of our success. But if anyone in my group ever replied to a help email the way I have seen replies on R-help, there would be consequences
Even Hadley Wickham, in his Google Tech Talk, talks about getting flamed on R-help. I think such responses became sort of ingrained in some people who contributed a lot to R, and nobody was willing to call them on it because of who they are (sort of like not calling out famous people for harrassment at the work place). I think we can both be extremely grateful to anyone who devotes a lot of time in any form to a project like R, while at the same time insisting on a modicum of proper behavior from everyone.
My $0.02.
+1
Agree that respect is important. However I think AG’s observation is that punishing a defector is altruistic. This observation makes an important distinction. You’re not being unfair by calling out a time waster. You’re actually helping the wider community you care about. It’s interesting, too, that watch dogs are often package creators/contributors who also spend a fair amount of time helping *sincere* newbies. I don’t believe in saints, but I agree that harsh can be kind.
to be fair, a lot of the questions on r-help are of the kind that arise if you refuse to read even the intro to R-syntax, let alone manuals. I react to those by keeping my frustration to myself, but I can understand why some arent able to do that
It would be interesting to see the distribution of posts under this scheme if they were quantified by someone from another culture and/or gender.
R-help is a pretty diverse list and you have to assume that it doesn’t operates under American cultural norms.
Pingback: The Cost of Troll Feeding : Max Cho
The R-core folks need to get a clue. R, qua language, is a disaster. It growed like Topsy, with no evident design, no BDFL, no coherent syntax beyond wrapping old FORTRAN code. “They” make claims of functional, OO, and other such language semantics. R ain’t python, it ain’t even java. S3(does anyone really think these are classes)?? S4?? Environments?? <<-?? It's a platypus language that happens to be free, and serves moderately well as an alternative stat pack command language. As a programming language, it ain't even GW-BASIC. Anyone coming to R with a moderate or greater understanding of real OO or functional language will run screaming from the room, if s/he can. Google for such screams; there's a plenty.
There is a post recently on R-bloggers complaining (I think) about the mess S4 classes are. But it's not clear whether the problem is that S4 classes are *too* OO (they ain't) or not enough. The syntax, coming from java, say, is abysmal; like suturing an elephant's trunk on a squirrel. And so goes most of R. The R-core folks need to accept that they've made a really bad "programming" language which functions so-so as a command language. Since it started as S at Bell, they should have chatted up Stroustrup once or twice.
Let the flames fly.
Everything you say is completely accurate, in my opinion. But R got big fast because it filled a need, so it’s worth thinking about how that happened. I see a few factors
Non-expert-programmer user base: R is by statisticians, for statisticians. (I’d say “unsophisticated” user base, but that might be taken as an insult…)
Low-cost prototyping: low cost in both dev time and money makes for rapid uptake.
CRAN: lots of useful extensions that can be installed with no fuss. That’s not so remarkable now, I suppose, but it must have been the bomb back in the day.
You might be interested in https://www.burns-stat.com/documents/presentations/inferno-ish-R/ , which presents a lot of the history of S/S-PLUS/R from someone who lived through it … “The moral of the story is that if you want to create a beautiful language, for god’s sake don’t make it useful.” (Not that there aren’t beautiful *and* useful languages out there.)
Thanks, Ben.
I’ve programmed in a bunch of different languages, including functional and objected-oriented ones, and I think R as a language is fine. There’s stuff I would do differently, but R is definitely the best-designed of the statistical programming languages, and it’s better than Matlab. It has a orthogonal design and straightforward syntax. The main source of inconsistencies is that all the packages are written by different people, with different design senses. R’s support for array programming is excellent, much better than all but a handful of languages.
Objected-oriented programming devotees are hard to keep happy, because they always want things to work exactly like in their favorite language, and complain endlessly when they don’t. Hence the many pixels that have died in endless flame-wars over Java and multiple inheritance.
Out of curiosity, anything particular you don’t like about Matlab?
I am in a similar position to Walt, having programmed nontrivial projects in Python, Perl, C, C++, Common Lisp, Prolog, scheme, R, maxima, Matlab, sh, SQL, … and I don’t remember what else
As for Matlab, it’s biggest flaw is that essentially everything is a matrix of numbers. Sure, it has cell-arrays but I doubt the language started with them, and so overall they are under utilized. The other problem is that every named function is its own file, and there is not good support for encapsulation, though I imagine there are some secret sauces that make things better, Octave dropped that requirement right away and it’s a significant improvement, you can put a bunch of helper functions inside foo.m and so the function foo doesn’t need to be so self-contained, you can have local scope helper functions, do recursion, etc.
Finally, although Matlab has higher-order functions, and anonymous functions, they are significantly less good than R’s versions, in large part because of the special file=function construct. Implementing and using something like plyr in Matlab would be a nightmare I think.
Pingback: Emacs IPython Notebook and “ESS in the Cloud” | Measure of Justice