Reacting to my recent post on Steven Pinker’s too-broad (in my opinion) speculations on red and blue states, Dan “cultural cognition” Kahan writes:
Pinker is clearly right to note that mass political opinions on seemingly diverse issues cohere, and Andrew, I think, is way too quick to challenge this
I [Kahan] could cite to billions of interesting papers, but I’ll just show you what I mean instead. A recent CCP data collection involving a nationally representative on-line sample of 1750 subjects included a module that asked the subjects to indicate on a six-point scale “how strongly . . . you support or oppose” a collection of policies:
policy_gun Stricter gun control laws in the United States.
policy_healthcare Universal health care.
policy_taxcut Raising income taxes for persons in the highest-income tax bracket.
policy_affirmative action Affirmative action for minorities.
policy_warming Stricter carbon emission standards to reduce global warming.Positions clustered on these “diverse” items big time. The average inter-item correlation was 0.66. . . . Being able to form a scale like this with a general population sample is pretty good evidence in itself (and better than just picking two items out of GSS and seeing if they correlate) that people’s opinions on such matters cohere.
But just to make the case even stronger, let’s consider how much of the variance in liberal policy preferences can be explained by ideology. . . .
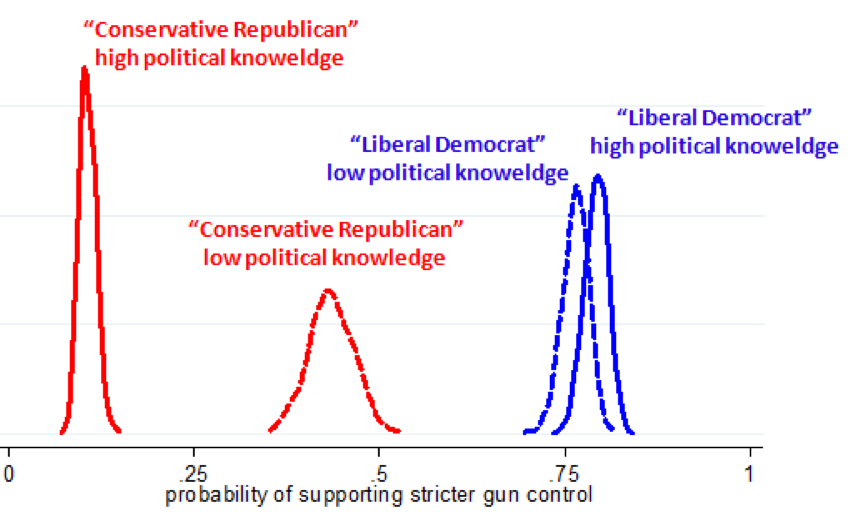
[Kahan’s graph was pretty good, but I cropped it here to make it even better, by dumping an uninformative title, an uninformative y-axis, and a pointless footnote. Cool, huh? — AG]
Pinker is clearly wrong—not just in his answer but in his style of reasoning—to connect this sort of coherence to “different conceptions of human nature” among people of opposing ideologies
Pinker, however, is indeed doing something very objectionable: he is engaged in rank story-telling.
He notes that political philosophers identify ideologies with different conceptions of “human nature,” a “conflict of visions so fundamental as to align opinions on dozens of issues.” Well, maybe political philosophers do do that. But the idea that “different conceptions of ‘human nature’ ” explains coherence and variance in mass political opinion is an empirical claim, and as far as I know there’s not any support for it.
I [Kahan] think it’s almost certainly false. . . .
Ironically, Andrew is making the sort of mistake he says Pinker made.
This last point follows from all the others. Andrew sees Pinker doing something irritating, and then treats a conjecture . . . as a general law that explains this particular instance, etc.
Wow—I love this sort of discussion! Here’s my reply:
In regard to the specifics, survey responses are noisy (presumably representing a lot of “nonattitudes” in the population). I think that many individual people feel there is a logic connecting all their political beliefs, but different people have different logics. Pinker gave an example of gay marriage and the military budget. There is a wide range of views on these two topics and the correlation is low, because these two issues can be placed in many different conceptual frameworks. What you have shown is that in your survey with those questions you get high correlations. GSS and NES show low correlations. I think it would be fair to say that some aspects of political attitudes can be predicted from other attitudes. In general, attitudes on different issues are more highly correlated with partisanship than with each other. I guess it would be ok to compromise and say that the correlations are moderate. I perhaps was overreacting to Pinker’s statement because I’m sensitive to this issue, of people not realizing the diversity of opinions among Americans, especially among those Americans who are not highly politically involved.
Regarding Kahan’s last point, where do I say anything about “a general law”? Here’s what I wrote:
Psychology is a universal science of human nature, whereas political science is centered on the study of particular historical events and trends. Perhaps it is unsurprising, then, that when a psychologist looks at politics, he presents ideas that are thought-provoking but are too general to quite work.
I think the first sentence is unobjectionable. I really do think psychology is more universal than political science. Sure, there are some aspects of political science that are universal, but my own work, for example, on Democrats and Republicans is unapologetically both time- and space-bound in a way that psychology certainly tries not to be.
My second sentence above is phased very carefully. I don’t think that “perhaps it is unsurprising” is anything like claiming “a general law”! But Kahan has a good point that I was oversimplifying a bit by downplaying the predictability of attitudes across issue domains.
Pinker cites Fischer’s “Albion’s Seed” framework of four kinds of WASPs — from north to south across the country: 1. New England post-Puritans, 2 Pennsylvanians, 3. Scots-Irish, and 4. English Southerners. That can be pretty helpful in thinking about Electoral College politics. If the GOP is ever going to win back the Presidency, they have to expand outward from tiers 3 and 4. The most likely route is to take Florida and do better in Tier 2: Pennsylvania, Ohio, and some other midwestern states that aren’t too New Englandish.
“Perhaps it is unsurprising, then, that when a psychologist looks at politics, he presents ideas that are thought-provoking but are too general to quite work.”
That seems extremely fair and insightful.
Similarly, my notion that the heart of the red-blue divide is in population density — the Dirt Gap — is continually validated by events, such as the current brouhaha over guns. City dwellers typically favor gun control because they enjoy relatively quick police response times, worry about hitting an innocent bystander if trying to defend themselves with a gun, don’t hunt or know anybody who does, and want the government to disarm urban street gangs. Country dwellers are rightfully concerned about defending themselves from home invasions (a major plague in the countryside of disarmed England), have plenty of room to shoot, are likely to know and admire hunters, and don’t worry about urban street gangs.
But, Republicans have been slow to adopt platform planks that deal with the central importance of population density. As you say, this insight might be too general to quite work as practical politics.
Living “in the countryside of disarmed England” I’ll be on the lookout for the evidence of that plague.
https://www.telegraph.co.uk/comment/personal-view/3613417/An-Englishmans-home-is-his-dungeon.html
There’s a _lot_ more crime in the more bucolic parts of England than in America. I recall a business lunch about six miles outside of Oxford where the only subject of discussion was my English colleague’s tales of having their cars stolen.
Wow—what a disgusting article! Perhaps Nancy Lanza, like Mark Steyn, thought that having three guns in her house would insulate her from the “underclass” and would allow her to “protect her family.”
“I perhaps was overreacting to Pinker’s statement because I’m sensitive to this issue, of people not realizing the diversity of opinions among Americans, especially among those Americans who are not highly politically involved.”
Right. There’s more Team Red and Team Blue thinking among people who enjoy reading opinion journalism than among people who don’t. For example, somebody who likes to read conservative journalism about, say, taxes might also support fracking because the Koch Brothers help fund his favorite writers on taxes, and those writers go to lunch with people who are paid to write in favor of fracking, so they plug fracking as well.
In contrast, somebody who never reads the op-eds but who is, say, generally conservative by nature might oppose fracking because he heard from his sister-in-law that her cousin’s drinking water has tasted weird ever since fracking started. He’s not less aware that being unskeptical about fracking is part of belonging to Team Red, so he’s more open to anecdotal data about the dangers of fracking. That’s not necessarily a bad thing.
All of the policies in the study Kahan cites are high profile ones that are in the news and well-known to be associated with a particular party. Anyone could tell you what the Democrat or GOP position on these policies is, so lots of people will simply have adopted those positions.
The graph that you cleaned up … can you (or anyone) explain? In particular, what is the message of
the showing bell curve distributions rather than an estimate. It’s surely not a modeled distribution – over the population of liberals – of the probability that that individual supports gun control. (Because: #1, why would an indidviduals support be probabilistic,
and, #2, it’s clearly absurd that there would be such unequivocal multi-sigma separation between two political
groups on any such subject).
On the other hand is it – my best guess – the distribution of outcomes from the monte carlo simulation?
But that’s pretty distracting and confusing; it merely give us some indication that, yes, he has run enough samples. If that is
the right conclusion simply a far better cleanup would be to discard the little bell curve shapes.
After all, his intro to the graph is: “let’s consider much of the variance in liberal policy preferences can be explained by ideology” and many primed to think about variance questions will assume the distributional spread shown here is relevant. (I would have jumped to that conclusion myself, except the variances are so small and the separation so good that it’s sort of obvious that’s not what it’s saying).
Bottom line: I do not think I understand the message of the displayed distributions (the width, not the center) here. My best guess of their meaning, which I am rather doubtful I am right about, has them as at best irrelevant and at worst actively misleading.
And the answer is “item response theory” (e.g., Simon Jackman). It’s Bayesian! Seriously, we tend to see a single underlying dimension when there are constraints on the expression of political belief. For example, polarization in the media and political discussion tends to turn us all into caricatures of political cartoons. When the general public begins to recite talking points, we can read the press releases and stop interviewing citizens. Not being a political scientist, I have always found discussions about the origins and life span of political attitudes to be an interesting topic. It seems to be a much more complicated process than that explained by political pundits. Psychology deals with a similar issue under the heading of personality. Anyone who has read Walter Michel knows the role of the situation in constraining behavior. In fact, it is difficult to read much contemporary psychological work without encountering situational and contextual constraints on the expression of feeling, thoughts, and action. Kahan makes a good point: coherence (probably yes in the current environment) and resulting from different conceptions of human nature (probably not).
IRT has a pretty long history, and most of it doesn’t include Bayesian modeling…
The Bayesian reference was might to be humorous. It’s Gelman’s blog (remember Bayesian Data Analysis, I believe a pulled a muscle trying to get through that book). You might have noted the use of the modifier “seriously” at the beginning of the next sentence. Of course, one can estimate the parameters of an item response model using maximum likelihood. However, go to Google and type “Bayesian item response theory.” Be prepared to be amazed at all the references dating back more than 10 years. There is even a textbook by Springer, Bayesian Item Response Modeling. Political science has been using Bayesian estimation of item response models for some time, which is why I referenced Jackman. That damn Bayes is everywhere parameters are hard to estimate or believed to be random.
Two cents of a non-expert:
I believe that people are, in general, much to quick to identify cause-and-effect in why humans formulate specific opinions.
Take the example of the healthcare mandate: It went from a popular concept among Republicans to being the most obvious sign that Obama is going to create a socialist tyranny. It went from a key element of a Republican governor’s political agenda to the rallying cry of a presidential candidate whose first action would be to overturn it (amazingly enough, the seam person).
Doesn’t seem to me that “concepts of human nature” is explanatory. Nor dirt. Nor Puritan heritage (or lack thereof). Perhaps they’re any of them might be moderators or mediators, but none of them change diametrically might opinions on a given same topic.
I would suggest (running the risk of being too quick to identify cause-and-effect) that to the extent that anything is causal, group identification is explanatory, and that group identification is a factor that trumps other variables and it is something that can change one’s position on issues through an essentially random process – in the same way that stock valuation can be altered by a (to some degree at least) random wandering of group belief/orientation. Consider how SCOTUS justices shift positions on issues such as states’ rights – with elaborate reasoning to rationalize contradictory views.
Often, I think that protecting one’s sense of self is the underlying causality behind political or other reasoning. You stake out positions essentially to believe that you are “right” or “moral” – and those orientations get their root in social orientation of your family/culture of origin (or in some cases, for some reason, a sense of self is grounded in the rejection of that orientation). But even protecting one’s need to be “right” or “moral” can be shifted dramatically under the pressure of group identification. What was I was “right” about or “moral” about today (view on the healthcare mandate, view on states’ rights) can become “wrong” or “immoral” tomorrow (view on the healthcare mandate, view on states’ rights) – depending on what I think will protect my group identification.
The figure is indeed nice, but what does the distributions represent? The uncertailnty in estimated probabilities,( or the posterior dist), or distribution of the probability within the group as a function of other covariates?
(if it is uncertainty, the the with is basically a measure of sqrt(group size), so the group “conservative republicans with little political knowledge” is the smallest of the four groups. That seems strange.)
OK, I went to the references blog post, and there I can see the plot title that Andrew removed: “Kernel density estimate”, so it seems to be my second mentioned possibility. But what are the other covariates? The blog only mentions one covariate!
bxg & kjetil: the answers to your questions are spelled out below. Regression table is here https://www.culturalcognition.net/display/ShowImage?imageUrl=/storage/liberal_policy_regress.bmp?__SQUARESPACE_CACHEVERSION=1356017662794 (For general discussion, including of the graphic presentation strategy, see 1. King, G., Tomz, M. & Wittenberg., J. Making the Most of Statistical Analyses: Improving Interpretation and Presentation. Am. J. Pol. Sci 44, 347-361 (2000).
“Regressing Liberal_policy on Conserv_repub, I discovered that the percentage of variance explained (R2) was 0.60. That’s high, as any competent psychologist or political scientist would tell you, and as I’m sure Andrew would agree!
“Now Andrew noted that the degree of coherence in political preferences tends to be conditional on other characteristics, such as wealth, education, and political interest. Typically, political scientists use a “political knowledge” measure to assess how coherence in ideological positions vary.
“I had a measure of that (a 9-item civics-test sort of thing) in the data set too. So I added it and a cross-product interaction term to my regression model. It bumped up the R2 – variance explained – by 4%, an increment that was statistically significant.
“Seems small, but how practically important is that? …
“Well, to help us figure that out, I ran a Monte Carlo simulation to generate the predicted probability that a typical ‘Liberal Democrat’ (-1 SD on Conserv_Repub) and a typical ‘Conservative Republican’ (+1 SD) would support “stricter gun control laws” (seems topical; this is pre-Newtown, so it would be interesting to collect some data now to follow up), conditional on being “low” (-1 SD) or “high” (+1 SD) in political knowledge.I had a measure of that (a 9-item civics-test sort of thing) in the data set too. So I added it and a cross-product interaction term to my regression model. It bumped up the R2 – variance explained – by 4%, an increment that was statistically significant.
“Seems small, but how practically important is that? A commenter on Andrew’s blog noted that I tend to criticize fixating on R2 as an effect-size measure; my point, which is one that good social scientists—political scientists and psychologists! Andrew too!–have been making for decades is that R2 is not a good measure of the practical significance of an effect size, a matter that has to be determined by use of judgment with relation to the phenomenon at issue.
“Well, to help us figure that out, I ran a Monte Carlo simulation to generate the predicted probability that a typical “Liberal Democrat” (-1 SD on Conserv_Repub) and a typical “Conservative Republican” (+1 SD) would support “stricter gun control laws” (seems topical; this is pre-Newtown, so it would be interesting to collect some data now to follow up), conditional on being “low” (-1 SD) or “high” (+1 SD) in political knowledge.
“Seems (a) like variance in political knowledge (whatever its contribution to R2) can matter a lot – the probability that a high–political-knowledge Republican will oppose gun control is a lot lower than that for a low–political-knowledge one—but (b) there is still plenty of disagreement even among low–political-knowledge subjects.”
bxg & kjetil — ooops, was bit careless there. The model on which the simulation is based was regression of those predictors — ideology, political knowledge & cross-product interaction — on the “support for gun control” item. table is *here*: https://www.culturalcognition.net/storage/gun_control_support_probabililty.bmp
also, my attempt to link King’s article on monte carlo & graphic presentation of regression results didn’t work. Just go here: https://gking.harvard.edu/files/making_0.pdf
Or read Gelman & Hill, pp. 141-42
dmk38: I appreciate your willingness to explain further.
I’ve read your source, and King’s article, and I still don’t quite get it. Sorry, my failing I am sure.
In your graph my eyes are drawn to the distribution _width_ around each point (especially since you tell us the whole point is something about variation) and I just don’t know how to interpret this very prominent aspect of the graphs – i.e. the widths specifically – as something interesting and relevant.
I now appreciate that the _centers_ of the distributions (at least, three of the four)
are compellingly distinct and hope I have some idea of what that means. But what does the width convey? What am I supposed to learn by seeing vividly that conservative-replican/low knowledge plot is so much more dispersed than the others? Is it that this is a more varied group of people? Or is it because they a smaller group (are they)? Or is just an artifact due to sqrt(p(1-p)) being larger for p nearer .5? Or something else entirely? I get (e.g. from your King citation) that it’s desirable to display measures of uncertainty for any estimate – but I also get (from there if not elsewhere) that there are a variety of types of uncertainty that one might distinguish and present, so it’s usually fair to ask what uncertainty specifically is on display. (And also, c.f. King, a good answer should require “little specialist knowledge to understand” – apparently a previous commenter saw the words “kernel density estimate” and all became clear to him – but I don’t have that background). Forgive me I am being dense if this is clear to all others.
If I could, perhaps a more concrete question along these lines… If you increased the number of iterations of your monte carlo simulaition greatly, would the width of the distributions in the graph shrink further or stay as they are?
Pingback: More Pinker Pinker Pinker « Statistical Modeling, Causal Inference, and Social Science
bxg, sure, happy to explain (perhaps in more detail than is necessary, but I’d rather err in that direction; somebody might complain that we should “get a room”—and in fact, I’m happy to continue this discussion at my blog, where readers will on average know much less about statistics than ones here).
a. To begin, the graphic represents the impact of political affiliation/ideology on support for gun control conditional on political knowledge. It illustrates — consistent with something that is well established in political science — that partisan division increases with political knowledge. You can see that, actually, in the regression model — https://www.culturalcognition.net/storage/gun_control_support_probabililty.bmp — on which the graphic is based. But what do you *really* see? How to interpret the practical importance of the logit coefficients (King’s point is that this is not clear even to someone who undertands how to read the regression output, much less someone who doesn’t)? Conveying that information (to everyone who can benefit form it) is the point of the graphic presentation.
c. I used the Monte Carlo strategy recommended by King (in fact, I used his Clarify program). The density plots reflect the distribution of predicted probabilities for combinations of predictors of support for gun control. I ran an MC simulation that generated 1000 versions of the regression model paramters. For each of those models, I predicted probabilities for predictor values (including the cross-product interactions) that reflect (a) “Conservative Republican” (+1 SD on the composite ideology/party id scale) with “high political knowledge” (+1 SD on the political knowledge measure); (b) “Conservative Republican” with “low political knowledge” (-1 SD on PK measure); (c) “Liberal Democrat” (-1 SD on ideology/party scale) with “high political knowledtge”; and (d) “Liberal Democrat” with “low political knowledge.” In effect, then, I had 1,000 predicted probabilities for each of those “types.” The “mean” predicted probability for each is reflected in the peak of the indicated density plot. You can see the *precision* of that prediction by looking at how spread out the estimates are; essentially, the higher the standard errors for the parameter estimates and the more “extreme” the predictor values, the more noise will be injected into the estimates. Obviously, the substantial overlap between the plots for high & low knowledge Liberal Democrats means that the probability that those two “types” would have different probabilities is relatively low (I’ll come back to this). But it is really obvious that there’s virtually no chance (i) that high & low knowledge Conserv Repubs are equally likely to support gun control, or (ii) that any sort of Conserv Repub is as likely to do so as any sort of Lib Dem. (iii) Also clear just how *substantial* the partisan divide is based on ideology/party alone.
d. I simulated 1,000 versions of the model. That’s pretty standard. The goal is to “fill out” the entire range of the probability distribution for the prediction that is associated with the selected predictor values. Probably even less than 1,000 would be enough. Once you have enough, adding more doesn’t accomplish anything; the mean & standard deviation (essentially) associated with the density estimate will be the same. In other words, the width or spread *won’t* change — you’ll just have an even more densely packed array of predicted probabilities inside of it (more sardines crammed into the same size kernel-density can). *Maybe* the distribution plots will look a little “smoother”–you sometimes can get some tiny little divots in the density plot but they are in fact meaningeless (at least in a regression model specified in the way this one was).
e. You can’t directly tell *anything* from this graphic about the frequency of these combinations of characteristics in the sample. Predicted probabilities for smaller groups or for ones (particularly ones who have extreme predictor values) are likely to be more dispersed — because essentially that will inflate the standard error associated with the predictions. But a steeply peaked value could be a result of really high parameter estimates, too (of course, those will have lower standard errors, so the point is related). I’d say, in fact, that one downside associated with Monte Carlo simulations — or really with any other method of generating estimated or predicted values with a regression — is that the modeler might pick unrealistic or meaningless predictor values to try to dramatize variance. The check on that is to make the modeler specify not only what the predictor values are but why they make sense. By the same token, you can *protect yourself* from being misled by being sure you know what predictor values were selected & by being satisfied they are reasonable ones for testing the relevant hypotheses, etc.
f. On why “low knowledge” matters *more* for conservative repoublican & liberal democrat — I’m not 100% sure! My guess is that if you looked at the sigmoid function (this is a logit mode), the point at which it transitions up to “support” from “oppose” is located closer to the Conservative Republican end of the scale. Being “low political knowledge” has the effect of pulling Conservative Republicans and Liberal Democrats toward the middle; but if the transition point from “oppose” to “support” is in fact *closer* to the Conservative Republican end of the scale, the number of (simulated) “low knowledge” Conservative Republicans who will be pulled up & over the threshold will be lower than the number of (simulated) “low knowledge Liberal Democrats” who will be sucked down the slope to “oppose.” But in any case, there’s *nothing* in the specification of the model that would otherwise capture an asymmetry in the impact of political knowledge on ideolgical congruence in positions, even if there really is one. One would have to use some sort of polynomial regression for that, I think!
Bxg—meant to include this too (I’m sick! Actually this important though for your question “what kind of uncertainty”):
c’. I could have used a different graphic presentation strategy. Essentially, I could have plotted the mean for each set of 1,000 predicted probabilities as a “point estimate” & constructed confidence-interval error bars at the 2.5 & 97.5 percentile values in the relevant distribution. I don’t think that is so awful, and it certainly is better than the nake regression output. But I think King (and Andrew) would say that the confidence interval is arbitrary—-nothing magic about the space between 2.5 & 97.5 percentiles; why not show more? Confidence intervals also obscure the information on how more or less likely predicted probabilities within the 0.95 confidence interval actually are. So use the density distribution & let the reader decide for him- or herself what to do with all the information it conveys about the relative probability of predicted probabilities. . .. Yet I suspect *if* I had done that, you wouldn’t have been confused about what I was doing?