This is one of my favorite ideas. I used it in an application but have never formally studied it or written it up as a general method.
Sensitivity analysis is when you check how inferences change when you vary fit several different models or when you vary inputs within a model. Sensitivity analysis is often recommended but is typically difficult to do, what with the hassle of carrying around all these different estimates. In Bayesian inference, sensitivity analysis is associated with varying the prior distribution, which irritates me: why not consider sensitivity to the likelihood, as that’s typically just as arbitrary as the prior while having a much larger effect on the inferences.
So we came up with static sensitivity analysis, which is a way to assess sensitivity to assumptions while fitting only one model. The idea is that Bayesian posterior simulation gives you a range of parameter values, and from these you can learn about sensitivity directly.
The published example comes from my paper with Frederic Bois and Don Maszle on the toxicokinetics of percloroethylene (PERC). One of the products of the analysis was estimation of the percent of PERC metabolized at high and low doses. We fit a multilevel model to data from six experimental subjects, so we obtained inference for the percent metabolized at each dose for each person and the distribution of these percents over the general population.
Here’s the static sensitivity analysis:
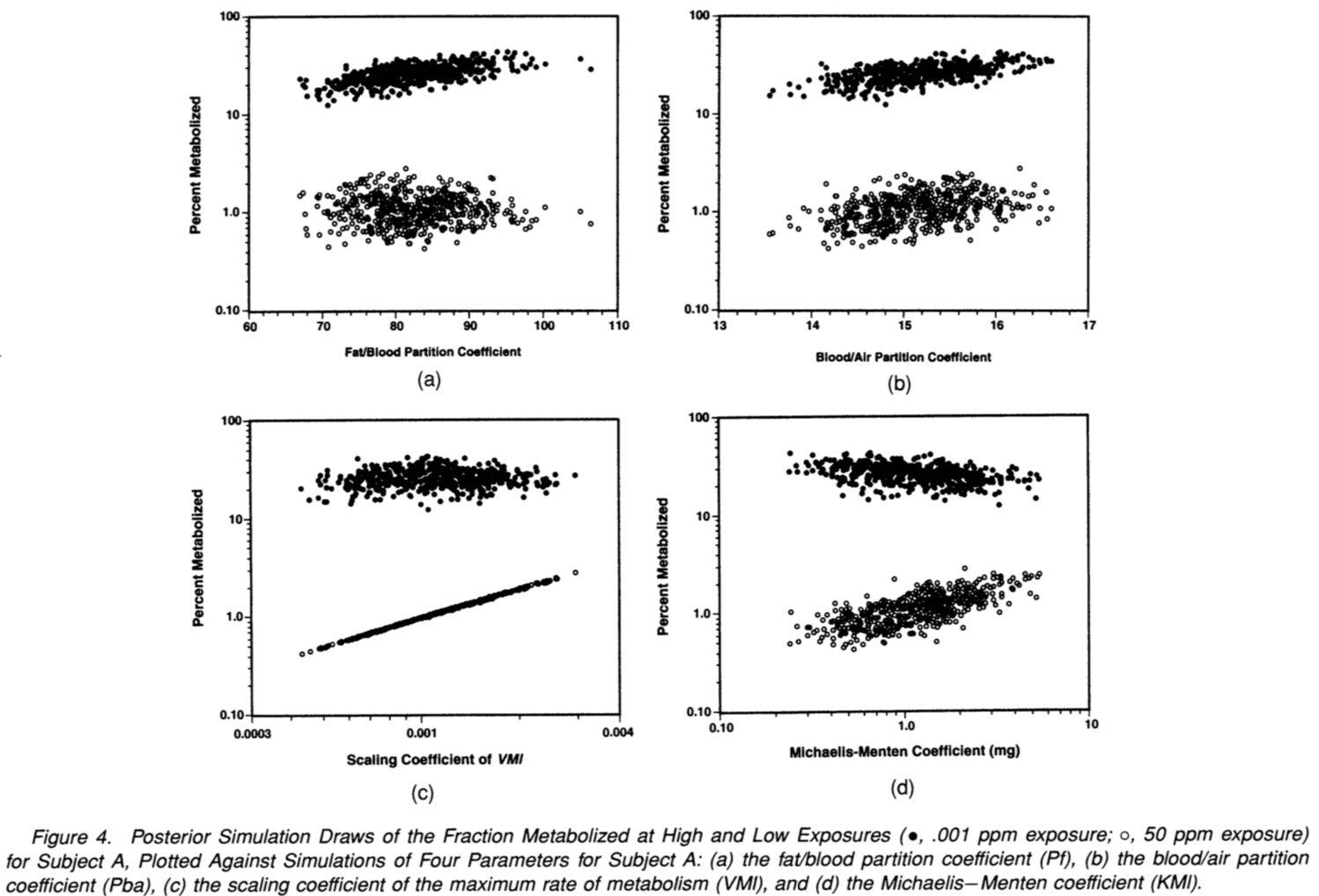
Each plot shows inferences for two quantities of interest–percent metabolized at each of the two doses–with the dots representing different draws from the fitted posterior distribution. (The percent metabolized is lower at high doses (an effect of saturation of the metabolic process in the liver), so in this case it’s possible to “cheat” and display two summaries on each plot.) The four graphs show percent metabolized as a function of four different variables in the model. All these graphs represent inference for subject A, one of the six people in the experiment. (It would be possible to look at the other five subjects, but the set of graphs here gives the general idea.)
To understand the static sensitivity analysis, consider the upper-left graph. The simulations reveal some posterior uncertainty about the percent metabolized (it is estimated to be between about 10-40% at low dose and 0.5-2% at high dose) and also on the fat-blood partition coefficient displayed on the x-axis (it is estimated to be somewhere between 65 and 110). More to the point, the fat-blood partition coefficient influences the inference for metabolism at low dose but not at high dose. This result can be directly interpreted as sensitivity to the prior distribution for this parameter: if you shift the prior to the left or right, you will shift the inferences up or down for percent metabolized at low dose, but not at high dose.
Now look at the lower-left graph. The scaling coefficient strongly influences the percent metabolized at high dose but has essentially no effect on the low-dose rate.
Suppose that as a decision-maker you are primarily interested in the effects of low-dose exposure. Then you’ll want to get good information about the fat-blood partition coefficient (if possible) but it’s not so important to get more precise on the scaling coefficient. You can go similarly through the other graphs.
I think this has potential as a general method, but I’ve never studied it or written it up as such. It’s a fun problem: it has applied importance but also links to a huge theoretical literature on sensitivity analysis.
Do I detect a small inconsistency in the nomenclature you are introducing here? "Static sensitivity analysis" as in the title, or "statistic sensitivity analysis" as per the first (italicized) use?
As typical, you are talking about something important, but I am too stupid and ignorant to do anything but guess at the meaning. Is this the concept of "shaking the ladder" in a model (Monte-Carlo method, because working with the closed form of the continuous distribution of measurement error is intractable)?
This seems pretty similar to the "Correlations" feature in the WinBugs/OpenBugs GUI.
To me, it's a pretty useful way to figure out precisely why models are wrong, even if they produce good forecasts.
David:
Yup. What makes these graphs special is:
(a) Interpretation. Rather than simply considering this as the joint posterior distribution of two random variables, were thinking of it as a display of how changes in the prior distribution of x affect inference for y.
(b) Flexibility. In my example above, "y" is not actually one of the parameters of the model but is a derived quantity representing an inference of substantive interest.
Doesn't this rely on some form of assumed orthogonality in the likelihood?
If one changes the prior for one parameter, through indirect learning we may change the inference on other parameters (or functions of other parameters, in this example). If the indirect learning was strong enough, your sensitivity analysis would be misleading, no?
Anon:
No such assumption is required. If you multiply the prior density for a single parameter by a factor, that goes straight through to the posterior density.
A related problem I have been struggling with. Say that you investigate the effect of variable x on y in ten random locations. You may fit a random slope/intercept model (whatever works best). I usually want to see how sensitive my results are to the influence of the different locations. So I do a sort of cross-validation, leave-one-out, but I leave out individual locations and not individual samples. I then look at how my posterior changes (estimate and 95% interval). Is there a common way to illustrate how my results changes if locations are dropped (im not sure if the jackknife-bias thing holds here)? Can I show the range of my coefficient estimates? What about the 95% intervals? Please let me know if there are any good papers/books out there with examples.
A while ago, I asked for examples of illustrations of how inferences vary by location (unit) and this was the only result – page 395 of Gelman and Hill.
And there is my draft on a general approach here https://statmodeling.stat.columbia.edu/2011/05/missed_friday_t/
If you find other published examples – I would be interested in knowing about them.
(Andrew may have been thinking of something else in this post.)