Statistics is, I hope, on balance a force for good, helping us understand the world better. But I think a lot of damage has been created by statistical models and methods that inappropriately combine data that come from different places.
As a colleague of mine at Berkeley commented to me—I paraphrase, as this conversation occurred many years ago—“This meta-analysis stuff is fine, in theory, but really people are just doing it because they want to run the Gibbs sampler.” Another one of my Berkeley colleagues wisely pointed out that the fifty states are not exchangeable, nor are they a sample from a larger population. So it is clearly inappropriate to apply a probability model for parameters to vary by state. From a statistical point of view, the only valid approaches are either to estimate a single model for all the states together or to estimate parameters for the states using unbiased inference (or some approximation that is asymptotically unbiased and efficient).
Unfortunately, recently I’ve been seeing more and more of this random effects modeling, or shrinkage, or whatever you want to call it, and as a statistician, I think it’s time to lay down the law. I’m especially annoyed to see this sort of thing in political science and public opinion research. Pollsters work hard to get probability samples that can be summarized using rigorous unbiased inference, and it does nobody any good to pollute this with speculative, model-based inference. I’ll leave the model building to the probabilists; when it comes to statistics, I prefer a bit more rigor. The true job of a statistician is not to say what might be true or what he wishes were true, but rather to express what the data have to say.
Here’s a recent example of a hierarchical model that got some press. (No, it didn’t make it through the rigor of a peer-reviewed journal; instead it made its way to the New York Times by way of a website that’s run by a baseball statistician. A sad case of the decline of intellectual standards in America, but that’s another story.) I’ll repeat the graph because it’s so seductive yet so misleading:
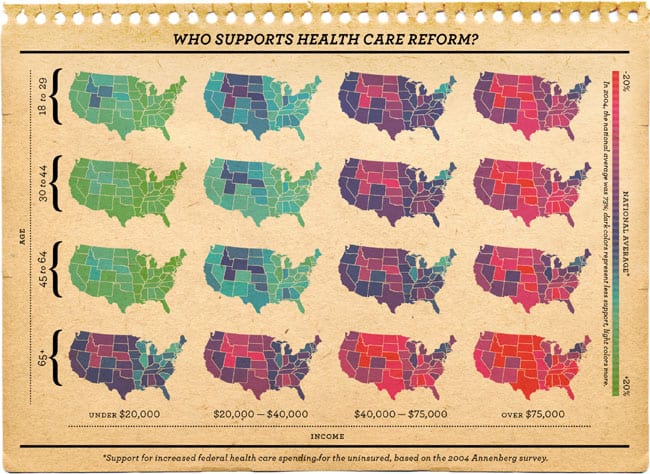
Wow—you might think—estimates for all these groups! And for all 50 states! (OK, really just 48, but you get the idea.) Pretty impressive. Very impressive, right?
Well, as the saying goes, if something looks too good to be true . . . it probably is. For example, look at that cluster of states–Idaho, Wyoming, and Utah–that stand out a bit in the upper-left map above. Interesting, huh? Maybe not. If you read the graph’s documentation (such as it is; remember, this ain’t peer-reviewed science here), you’ll see that they used vote for president as a “predictor” in their model. To put it more plainly, when they didn’t have enough data, the bozos^H^H^H^H^H^H statistical whizzes who made these maps relied on presidential vote. Idaho, Utah, and Wyoming are strongly Republican states, so . . . hey, there you have it, we “know” their positions on health care. Similarly for many of the other patterns on the graph, which shows some suspicious regularities that don’t seem so surprising once you know that the estimates are based on an octopus-like model that pulls the data this way and that to fit some preconceived bias^H^H^H^H^H statistical model. I’m not exactly saying that the people who made these snazzy maps cheated, exactly—although I’m not saying they didn’t, either!—but I do think that this sort of random-effects or partial-pooling technology can, and does, lead people to have a false sense of certainty in their analyses. Ultimately, it’s not always such a great idea to produce smooth, reasonable-seeming maps from sparse, spotty data. As a political scientist, and as a statistician, I’d prefer being more honest about what the data are saying, and let the readers form their own conclusions.
(Serious statisticians would, I believe, recognize that this information would be better presented in tabular form–for one thing, this would force the statistician to more directly confront his inferences–but that’s an argument for another date.)
Well, Mister Poststratification, you might be able to fool some of the people most of the time, but you ain’t gonna snow me.
“Partial pooling” sounds reasonable, but, ultimately, you’re smoothing toward a model. Garbage in, garbage out. I’d rather listen to the data rather than be too cute and end up hearing exactly what I wanted to hear. Sure, there’s been some comparative research, but let’s get serious for a minute. The goal of political science—of applied statistics in general—is to learn about reality, not to play some game of minimize-the-mean-squared-error.
Not to lean too strongly on my own experience, but I’ve always found that the so-called gains from hierarchical modeling come in the expected cases when you already know the answer. While the “statistically rare” errors—the places where multilevel modeling performs worse than simpler, more robust methods—always seem to occur in cases where you care about the answer.
It’s no coincidence that I’ve seen this pattern—you can demonstrate it mathematically. If theta_j is the true value (the average opinion on some survey, say) in state j and y_j is the unbiased estimate, then the “partially pooled” or Bayes estimate will be somewhere in the middle. On average, it is when the theta_j’s are the most discordant from the model that the estimates will be most strongly pooled toward the model—but those are the settings in which we’d most gain from learning from the data, and where we’d least like to be messing around with pooling. To summarize: the mathematics—Bayes’ theorem—shows that hierarchical modeling has the most dangerous effects in the very cases where the model is furthest from the truth.
That’s one reason why you shouldn’t trust evaluations based on mean squared error or other aggregate properties. Consider this article, which managed to make it through the oh-so-rigorous screening process at the American Journal of Political Science. To avoid causing embarrassment, I won’t mention the names of the authors of this article—they mean well, I’m sure—but all the cross-validation in the world, all their oh-so-earnest replication, and all their fancy graphics (woo hoo! Stata’s not good enough for those pros. Nooooo, they’re using “open source.” Oh, how countercultural of them. . . . Gimme a break. Here’s my quick principle of statistical graphics. If you can’t do it in Stata—or, for that matter, Excel—you don’t know what you’re doing anyway.) don’t overcome (a) a complete and stunning lack of statistical theory (this paper wouldn’t make in Econometrica, that’s for sure!) and, more importantly, (b) a sense, as described in my paragraph above, that what’s important in social science is not average error or mean squared error, but getting the tough cases right. And here the multilevel approach fails miserably.
A little bit of history
The pathologies of inappropriate aggregation of data are not new but go back to the foundations of the method. In 1981, the education researcher Donald Rubin published a paper, “Estimation in parallel randomized experiments,” in which he advocated a Bayesian procedure for combining information from different studies. Rubin’s example (which, unfortunately, has made its way into at least one statistics textbook) was particularly provocative—or, one might say, silly—in that each of the studies was actually a separate randomized experiment.
Here are the data from Rubin’s paper:
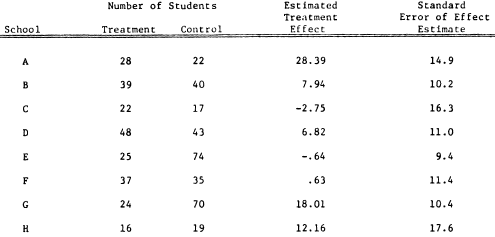
In true quantitative-social-scientist fashion, he tortures this dataset to within an inch of its life, setting aside the obvious (and, it so happens, correct) analysis in which each of the eight experiments is treated separately and instead producing a tangled set of Bayesian curves that, as far as I can tell, do little more than provide plausible deniability for the subsequent analysis. (By “plausible deniability,” I mean that the hierarchical Bayesian analysis is so complicated, such overkill—we’re talking about 5 pages of algebra where a simple t-test would do—that it’s virtually impossible to understand the mapping from data to inference. Hey, maybe that’s a feature, not a bug: an analysis that’s such a mess that nobody can hope to really understand it. No room for cheating there!)
The funny thing is that, in this particular example, there’s nothing going on at all! The standard deviation of the eight estimated treatment effects is actually smaller than the average of the standard errors of estimation. Rubin actually noticed this himself, but that didn’t stop him from turning the fabled Bayesian crank.
Not to be catty about it, but maybe it’s no coincidence that Rubin’s article appeared in the Journal of Educational Statistics rather than in a more serious journal such as the Annals of Statistics or Biometrika (or maybe JASA, but that’s a journal that’s been known to relax its standards and sometimes publish articles that do not have strong theoretical foundations). So much for the foundations of partial pooling, or hierarchical modeling, or whatever you want to call it!
On an unrelated topic
I wanted to tell you about some really cool research on evolutionary psychology that appeared in the newspaper recently, having to do with some fundamental differences between men and women. This research isn’t politically correct—far from it—but it’s potentially very important. I don’t have space to discuss this exciting work here, but maybe I can share it with you on another date.
P.S. I hate to have to say this, but . . . all the above is a joke! C’est rien qu’une blague, un poisson d’avril. (People tell me that I need to explain this, otherwise readers who find this entry through a websearch might mistakenly take it seriously.) Almost always on this blog, I’m completely sincere. But on this one day . . .
I know this is beside the point, but sometimes when I picture a multilevel model, I think of an octopus!
"Hey, maybe that's a feature, not a bug"
:-)
Um, is it April 1st?
And vice versa.
Agree – no more borrowing of weakness!
All of us – as well as all of our estimates – should stand totally on their own.
As islands on their own – never to be replicated again – or pulled together (or apart) by repulsive octopi or a nauseating meta-anal-“eye”-sis.
K
That graph is a bit bland, could do with so more colour
I for one am convinced. This Gelman guy is on to something.
K –
I agree! I sure as heck am not exchangeable. I am a model of one!
D
I was waiting for it! Actually, I did one of it myself, at my Blog, in portuguese, totally inspired by you.
My bet was that you would blog about that (r)evolutionary theory, but you devoted only a few words.
I agree: we have to nip this in the bud. Next thing, they'll be wanting to specify "prior distributions".
By the way, I think you forgot to end this sentence:
"Rubin's example (which, unfortunately, has made its way into at least one statistics textbook) was particularly provocative–or, one might say, silly–in that each of the studies."
Dave: If you don't know what day it is, you'll need more than multilevel modeling to help you!
Manoel: I can't even really read Spanish, so Portugese is definitely beyond me.
Simon: Thanks; I fixed it.
I hope this is an April Fool's, otherwise you've taken a crack to the head with a heavy blunt object recently and ought to seek medical help!
Maps are old school. These should be 3D pie charts.
Actually, the maps are 3-D. You can pick up your glasses at the Columbia University bookstore.
Maybe I shouldn't read blogs on April 1st… I'm definitely more confused then when I started reading. To recap (I think): the map analysis was real, and the nod to the politically incorrect news story was fake, but what about the part on Rubin's article, which is the part I'm most interested in? I thought I was following, but the comments lead me to believe that I missed either the point or the joke of the Rubin section…
Tim B, try this link:
https://www.stat.columbia.edu/~cook/movabletype/ar…
why rubin? yesterday I happened to read efron's 1977 paper on baseball with a similar idea. 'Stein's paradox in statistics' was published in Scientific American. Is that even less serious than Journal of Educational Statistics?
Wei:
The Efron and Morris papers are great. For that matter, Tiao and Tan did full Bayes inference for the hierarchical normal model back in 1965. What made Rubin's paper was that it was a real applied example (not merely an illustration on cool data) and that he did the full Bayes computation from beginning to end. Previous analyses had been applied or fully Bayesian, but none before, to my knowledge, had been both.