Commenter BorisG asked why I made my pretty maps using pre-election polls rather than exit polls. I responded in the comments but then I did a search and noticed that Kos had a longer discussion of this point on his blog. So I thought maybe it would help to discuss this all further here.
To start with, I appreciate the careful scrutiny. One of my pet peeves is people assuming a number or graph is correct, just because it has been asserted. BorisG and Kos and others are doing a useful service by subjecting my maps to criticism.
Several issues are involved:
– Data availability;
– Problems with pre-election polls;
– Problems with election polls;
– Differences between raw data and my best model-assisted estimates;
– Thresholding at 50%;
– Small sample sizes in some states.
I’ll discuss each of these issues in turn.
Data availability. The exit polls became available on election night at CNN.com and I used them extensively when I stayed up all night in Chicago crunching numbers. But I didn’t–and still don’t–have raw election poll numbers. I’ve asked and asked but with no success yet.
Meanwhile, there were lots of pre-election polls, but only a few weeks ago was I able to get any raw data from them, when, at my request, the people at Pew graciously posted their data on their website. So I used what was available.
Kos wrote, “Pew didn’t break down those categories by race — Gelman filled in the blanks with statistical sleight of hand.” This isn’t correct. Pew actually gave me raw data, a total of approximately 30,000 respondents.
Problems with pre-election polls. As Kos and others have noted, pre-election polls have problems, most notably that they are surveying people months before the election and that these people did not necessarily vote. On the upside, as Nate and others have found, pre-election polls match actual elections very well on a state-by-state basis–Nate’s pre-election poll aggregations were within 1% of the election outcome in 22 states and with 3% in 39 out of 50 states–so they’re not as bad as you might think.
Problems with exit polls. Exit polls have the advantage of reaching people right after they voted, but they have lots of other problems. In 2008 and in earlier years as well, exit polls had huge nonresponse biases. I’m still willing to use exit polls–you gotta use what you got–but we’re deluding ourselves if we think they’re a gold standard.
Disagreements between pre-election and exit polls. In Red State, Blue State we replicated many of our 2000 and 2004 analyses with Annenberg pre-election polls and Voter News Service exit polls. We generally found similar but of course not identical results. When studying separate income categories in small states, you really do run into sample size issues.
Beyond this, there can be systematic differences. Consider this graph that I posted awhile ago of the overall pattern of income and voting in 2008, separately looking at Pew and exit polls:
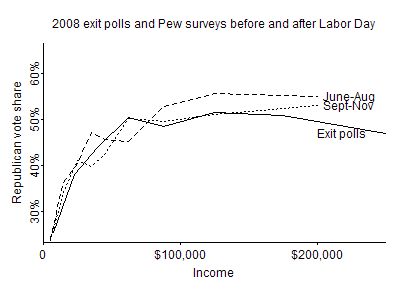
The two sources of data disagree on the very important question of whether the richest voters went for Obama or McCain. (The highest income category from the Pew surveys is “$150,000+”, so we can’t do a direct comparison at the top.) There’s no easy answer here and no easy resolution; there really just is a difference in what these polls say. And, no, I don’t necessarily believe the exit polls just because they are surveying actual voters. Again, exit polls have problems too.
Non-Hispanic whites. As I wrote in my explanation, in my maps of whites I included those survey respondents who described themselves as white and not Hispanic, because I think this most closely captures what commentators are talking about when they talk about “white voters.” I admit, though, that my graphs were simply labeled “Whites only,” which might have misled people into thinking that I was including Hispanic whites as well.
Differences between raw data and my best model-assisted estimates. Because of sample size, you can’t necessarily trust the raw data in any given state.
Consider Kos’s example of Colorado. Here are the raw data from the Pew exit poll for the five income categories:
Obama 26 28 67 51 15
McCain 2 36 45 56 16
This gives McCain 46% of the vote in the state which actually comes out about right. Things actually come out slightly differently when you include the survey weights. In any case, let’s now break it up by ethnicity
white:
Obama 9 25 51 41 12
McCain 2 32 43 50 15
black:
Obama 4 0 5 2 0
McCain 0 0 0 0 0
Hispanic:
Obama 12 3 2 3 3
McCain 0 0 2 5 0
Asian:
Obama 0 0 0 2 0
McCain 0 0 0 0 1
Other/decline to state:
Obama 1 0 9 3 0
McCain 0 4 0 1 0
Here are my estimates of the share of McCain’s share of the vote in each of the five income categories in Colorado:
0.35 0.43 0.48 0.53 0.57
And here are my estimates just for non-Hispanic whites in Colorado:
0.48 0.51 0.54 0.56 0.58
Because of the small sample size, I couldn’t just take the raw numbers. But I’m wiling to believe there are problems with the model, and I’m amenable to working to improve it.
Thresholding at 50%. In New Hampshire, for example, I estimate McCain as getting 50.2% of the two-party vote among whites in the lowest income category, 50.3% of the next income category, then 50.1%, 50.0%, and 49.8%. I agree that the sharp color change of the map can make things look more dramatic than they really are. I was giving my best estimates, recognizing that some states are essentially tied.
Small sample sizes in some states. Kos is right–there’s something wrong with my New Hamphire numbers. McCain only won 45% of the vote in New Hampshire, and the state is nearly 100% white, so clearly I am mistaken in giving him 50% of the vote in each income category. My guess as to what is happening here is that, with such a small sample size in the state, the model shifted the estimates over to what was happening in other states. This wasn’t a problem in my map of all voters, because i adjusted the total to the actual vote, but for the map of just whites it was a problem because my model didn’t “know” that New Hampshire was nearly all white. In the fuller model currently being fit by Yair, this problem will be solved, because we’ll be averaging over population categories within each state.
In the meantime, though, yeah, I should’ve realized New Hampshire had a problem.
More generally, in the smaller states which have smaller sample sizes (160 for New Hampshire), estimates from polls are always going to be more speculative. In most of my analyses I’m interested in national patterns and more aggregate comparisons among states, as, for example, here:
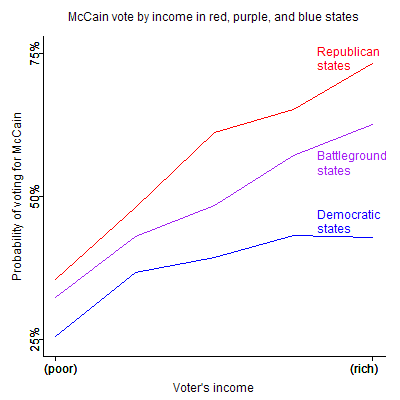
If you’re Kos and are interested in electoral strategies in individual states, then I’d say that my analyses and maps are a guide to national patterns and might be useful in suggesting more detailed state-by-state analyses using richer datasets. Exit polls are no panacea but are certainly a place to start here, and I plan to analyze them once I can get my hands on them.
Thank you for your thorough response. You raise many valid points, but I suppose my beef is that in absence of more reliable information, such as the raw numbers from multiple exit polls, it seems to me that making this analysis is so prone to errors that it is still… well… useless. Even if you had raw data from *multiple* pre-election polls, that would be at least better. But relying on the data from only one polling outfit, and one that didn't do statistically as well as several others in predicting the actual vote margins, just seems like a recipe for creating a false impression, and therefore a false narrative. The Maine example shows the hazards of this. I would think it would be better to say nothing at all until more data became available rather than make potentially misleading conclusions.
You point out: "On the upside, as Nate and others have found, pre-election polls match actual elections very well on a state-by-state basis–Nate's pre-election poll aggregations were within 1% of the election outcome in 22 states and with 3% in 39 out of 50 states–so they're not as bad as you might think."
I think the key word in that is "aggregations." The accuracy of Nate's statistical analysis is based precisely on the fact that it's aggregate. Had he relied only on Pew… well, he wouldn't be nearly as famous today. ;)
Cheers.
Andrew,
I have a request. Since you have access to the Pew data and the ability to analyze it, I'd be very interested in seeing your analysis of voting by age and race. Based on some analysis published by Pew, which is confirmed by the national exit polls, Obama did the same or slightly worse than Kerry among white, non-Hispanic voters aged 45 and up (or as I would prefer it, born 1963 or earlier). This group represents over 40% of the electorate. If they didn't participate in the 6 point increase the Dems had overall, that seems pretty significant to me.
Andrew, arguing with partisan hacks is just a waste of your time. They'll believe what they want to believe, regardless of the evidence.
Boris: A big problem here is my lack of a gray ("purple") area for the proportions that are near 50%, implying too much certainty in my estimates.
William: I'll take a look. Also, the Pew data are publicly available, so you could take that look too.
Smaug: I know what you're saying, and I agree that it's a good idea to ignore comments such as this one. On the other hand, Kos was right about New Hampshire and my map was wrong there, so he had a point!
Well, the reason I included the phrase "and the ability to analyze it" is because my ability to manipulate the data is somewhat limited. My only statistics course was 25 years ago. Although I'm quite comfortable with programming, the spss file format Pew uses is rather inconvenient for me.
Mr. Gelman if you don't have the raw exit poll data yet to do the regression analysis, then why not wait for it and do a thorough and more reliable analysis rather than one filled with errors?
You are not in the breaking new business. Are you? Then what was the hurry.
Steve:
1. For one thing, when I posted the graphs, people noticed problems, which I can fix in the next iteration.
2. Exit polls have a lot of problems and I wouldn't trust them all by themselves either.
3. I don't think my analysis was "filled with errors." As I discussed above, I could've been clearer in indicating that the numbers were estimates and, as such, imperfect, especially in deterining the "colors" of states that were close to 50/50. I've been working with this sort of data long enough that I forgot that it might be important to make this point to others.
http://www.geocities.com/electionmodel/Confirmati…
In analyzing historical election data, an ongoing pattern of statistical anomalies leads to two conclusions: the recorded vote does not reflect the True Vote and the pattern always favors the Republicans. This brief summary of recurring anomalies since the 2000 Selection is powerful evidence that the 2000 and 2004 elections were stolen and that landslides were denied in the 2006 midterms and 2008 presidential elections.
The analysis does not include millions of potential Democrats who were disenfranchised and never even got to vote.
Uncounted Votes
There are millions of uncounted votes in every election. The majority (70-80%) are Democratic.
Late Votes
The Democratic late vote exceeded the Election Day share by 7% in each of the last three presidential elections.
Undecided voters
Historically, undecided voters break (60-90%) for the challenger.
Pre-election polls in general do not allocate undecided voters.
The undecided vote was strongly Democratic in the last three elections.
New Voters
According to the 1988-2004 National Exit Polls, the Democrats won new voters by an average 14% margin.
Pre-election Polls
Registered voter (RV) polls include all registered new voters; likely-voter (LV) polls are a subset of RV polls and exclude many newly registered.
In general, only LV polls are posted during the final two weeks before the election.
LV polls are a subset of the total (RV) sample and have consistently understated the Democratic vote.
The RV samples are more accurate, especially when there is a heavy turnout of new voters – as in 2004, 2006 and 2008.
The Census reported that 88.5% of registered voters turned out on 2004.
The average projected turnout of 5 final pre-election RV/LV polls was 82.8%.
A regression analysis of Kerry’s vote share vs. registered voter turnout indicated he had a 52.6% share (assuming a 75% UVA).
Assuming the two-party vote, Kerry had a 51.3% share.
There was a strong 0.89 correlation ratio between Kerry’s LV poll share and LV/RV turnout.
In other words, the pre-election polls underestimated voter turnout by 6%. Newly registered Democrats came out in force.
In 2008, Obama won new voters by approximately 71-27%; in 2004, Kerry won new voters by approximately 57-41%.
Final National Exit Poll
The Final NEP is always forced to match the recorded vote count.
In 2004, the returning Bush/Gore 43/37% voter mix was impossible.
In 2006, the returning 49/43% Bush/Kerry voter mix was implausible.
In 2008, the returning 46/37% Bush/Kerry voter mix was impossible.
2000
Gore won by 51.0-50.46m (48.38-47.87%).
The Census reported 110.8 million votes cast, but just 105.4m were recorded.
The Final 2000 NEP was forced to match the recorded vote.
Approximately 4 million of the 5.4 million uncounted votes were for Gore.
Therefore he won the True Vote by 55-52m.
The election was stolen.
2004
Bush won the recorded vote by 62.0-59.0m (50.73-48.27%)
Kerry won the unadjusted state exit polls by 52-47%.
He led the preliminary NEP (12:22am, 13047 respondents) by 51-48%.
He led despite the implausible NEP 41/39% returning Bush/Gore voter mix.
The Final NEP (13660 sample) was forced to match the 50.7-48.3% Bush recorded margin.
To force the match in the Final NEP:
a) Bush shares of returning and new voters were increased,
b) The returning Bush/Gore voter mix was changed to an impossible 43/37%.
The mix indicates an impossible 52.6m (43% of 122.3) returning Bush 2000 voters.
Bush only had 50.46 million recorded votes in 2000.
Approximately 2.5m died and 2.5m did not vote in 2004.
So there were at most 45.5 million returning Bush voters.
The Final overstated the number of returning Bush voters by 7 million.
Kerry won the True Vote by 8-10 million.
The election was stolen.
2006 Midterms
Democrats won all 120 pre-election Generic polls.
The final trend line projection showed a 56.43-41.57% Democratic landslide.
At 7pm, the NEP indicated a 55-43% landslide.
The returning Bush/Kerry voter mix was 47/45%.
The Final was forced to match the 52-46% recorded vote.
To force the match:
a) the Bush share of returning and new voters were increased,
b) the returning voter mix was changed to an impossible 49/43%.
The Democratic margin was cut in half.
The landslide was denied.
2008
Obama won the recorded vote by 69.4-59.9m (52.9-45.6%)
Obama led the final pre-election registered voter polls by 52-39%.
The Final 2008 NEP was forced to match the recorded vote.
The Final indicated that an impossible 5.2 million (4% of 131.37m) were returning third-party voters.
There were only 1.2 million third-party voters in 2004.
To force the match, the Final indicated an impossible 46/37% Bush/Kerry returning voter mix.
The Final indicated there were 60.4 million (46% of 131.37m) returning Bush voters.
Bush only had 62.0 million votes in 2004 (assuming no fraud).
Approximately 3 million died and another 3 million did not vote in 2008.
The mix overstated the number of returning Bush voters by 4 million – assuming zero fraud in 2004.
It overstated the number of returning Bush voters by 9 million – assuming the unadjusted 2004 state aggregate exit poll (Kerry by 52-47%).
Obama's True Vote margin was cut in half.
The landslide was denied.
In summary:
If Final NEP weightings indicate a mathematically impossible number of returning voters, then simple logic dictates that the weightings are impossible.
Since impossible weightings were necessary to match to the official vote count, then the official vote count must also be impossible.
Since the vote count is impossible, then all demographic category cross tabs must use incorrect weights and/or vote shares to match the count.
Prof. Gellman says: "In 2008 and in earlier years as well, exit polls had huge nonresponse biases."
However, the truth is that Ron Baiman and I developed two methods of evaluating whether or not discrepancies between exit polls and election results are caused by response bias or by vote miscount. It turns out that the two causes of discrepancies create entirely different patterns when the discrepancy data is ordered by the partisanship of the exit poll or vote share.
We mathematically proved that the discrepancies in 2004 in Ohio could *not* be explained by exit poll response bias and that the largest share of the discrepancy was consistent with a pattern caused by vote miscount.
Anyone wanting to see the methodology can visit the exit poll section at http://electionmathematics.org
Unfortunately, the exit pollsters rarely release any data that can be used to judge the cause of the discrepancies.
My point is that the claim that there is a large partisan response bias (more Democrats answering exit polls) is not supported by any valid analysis due to the lack of public release of exit poll and vote count data for the same polling locations.