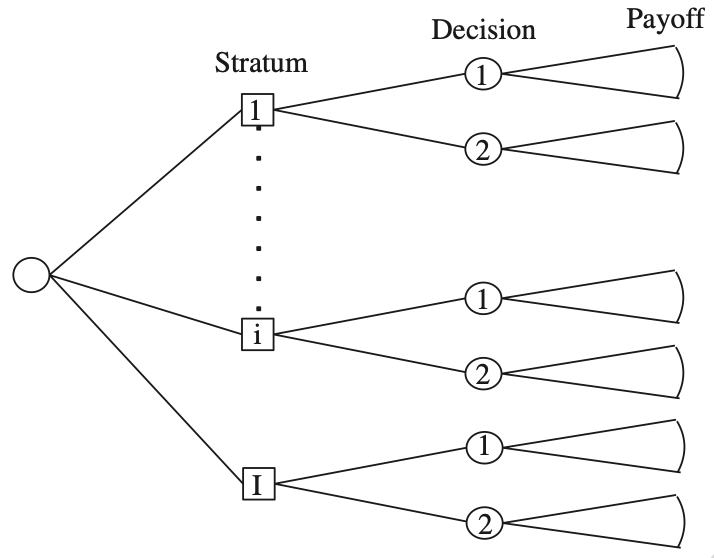
The above sketch shows a decision tree.
The circles are uncertainty nodes and the squares are decision nodes. Read the tree from left to right: to start, there is uncertainty of which of the strata i=1,…,I you will be in. In any given stratum, you will have to decide between options 1 and 2, and for each of these decision options there is uncertainty about the payoff.
The goals are:
(a) Conditional on the stratum, pick the best decision. This is the local decision problem.
(b) Averaging over the strata, evaluate the expected value of the tree, that is, the expected value under an optimal decision analysis given the uncertainty.
The challenge is that you don’t know which internal decision is best, because there is uncertainty about the payoffs.
The “optimizer’s curse” is that if, for each stratum in step (a), you make the best decision given available information–that is, you estimate the expected payoff under each of the two decision options and then pick the the one whose expected payoff is higher–then if you use these expected payoffs in step (b) you will systematically overestimate the value of the tree.
The “curse” here is not that the optimizer is making bad decisions, it’s that a naive estimate will be overly optimistic about the net value because you’re selecting on choices that look good.
In 2007, Erwann Rogard, Hao Lu, and I published a paper on the topic, including the above diagram. Here’s our abstract:
The evaluation of decision trees under uncertainty is difficult because of the required nested operations of maximizing and averaging. Pure maximizing (for deterministic decision trees) or pure averaging (for probability trees) are both relatively simple because the maximum of a maximum is a maximum, and the average of an average is an average. But when the two operators are mixed, no simplification is possible, and one must evaluate the maximization and averaging operations in a nested fashion, following the structure of the tree. Nested evaluation requires large sample sizes (for data collection) or long computation times (for simulations).
An alternative to full nested evaluation is to perform a random sample of evaluations and use statistical methods to perform inference about the entire tree. We show that the most natural estimate is biased and consider two alternatives: the parametric bootstrap and hierarchical Bayes inference. We explore the properties of these inferences through a simulation study.
I kinda like the paper. I wouldn’t say it’s one of my all-time favorites, but I think it’s interesting, and I like that we offer two different solutions to the problem.
On the downside, the paper seems to have disappeared without a trace. In 20 years, it’s only been cited three times, and none of them look very impressive:
“Using Alternating Decision Treets,” indeed.
Maybe one problem with our paper was its dry-as-dust title, “Evaluation of multilevel decision trees.”
This all came to mind because Sean Manning pointed me to this post, “The best cause will disappoint you: An intro to the optimisers curse.” Now that’s a good title.
It seems that the term “optimizer’s curse” came from this 2006 paper by James Smith and Robert Winkler, which has a lot of overlap with our article that appeared a year later. Both papers use hierarchical Bayesian analysis. Their paper is better than ours, for sure, and not just in the title, as they make a much better case for the importance of the problem. But we were working independently. Too bad: had we joined forces we could’ve produced something better, as each of the two papers had lots of material that was not in the other. Smith and Winkler consider the problem of choosing among many options with different levels of uncertainty, whereas we consider a multiplicity of binary decisions. These are just two cases of the general principle.
The above-linked post, by someone who goes by the handle “titotal,” is good too. It doesn’t have any new technical material, but it explains the problem in plain English from first principles, goes through some examples, and discusses some of the policy implications.
I was confused for a long while because this observation seemed to violate the tower property of expectations. Now I see that the issue comes from the fact that the conditional payoff distributions are not known, but estimated by sampling, which means that the chosen decision in each stratum is also a random variable.
This Optimizer’s Curse sounds much the same as a section from The World Of Mathematics series, published in 1956, if I remember correctly from long ago. The application was to a set of bidders for a contract. If the bidders had a distribution of errors in their cost estimates then the low bidder very likely would have underestimated the cost, and would therefore likely lose money on the contract.
Tom:
The example you’re talking about is known as the winner’s curse, and I agree that it has a similar mathematical structure as the optimizer’s curse discussed in the above post.
The winner’s curse often brings up Groucho Marx’s (possibly apocryphal) remark, “”I don’t want to belong to any club that would accept me as one of its members.”
Paul: There’s actually some evidence that something like that story really happened:
https://quoteinvestigator.com/2011/04/18/groucho-resigns/
Neural networks from locality sensitive hashing: https://sciencelimelight.blogspot.com/2026/06/atlas-lsh-neural-networks-geometry-as.html
I just cited the Smith and Winkler paper for the first time this week but hadn’t seen your paper; I’ll have to go through it. Picking the best choice at each stage, or among a set of competitors, is such an obvious thing to do, and the introduction of bias is somewhat surprising even to statisticians not familiar with the problem. This particular curse pops up in medical research all the time, especially early-stage research where a set of choices are made about what to continue studying, but given the sample sizes the best choice is often the most biased (related to the Type M errors).
> The challenge is that you don’t know which internal decision is best, because there is uncertainty about the payoffs.
It took me some time to understand that the “uncertainty” there was not in the risk sense (different outcomes may happen with some probability) but in the incomplete information sense (the outcomes and/or their probabilities are not known precisely) and that the issue is about single decisions and not particularly about decision trees. (It’s true that the weighted average of overestimates -in expectation- will overestimate -in expectation- the weighted average.)
Maybe you can explain it more thoroughly to me, because I’m not feeling the intuition here.
Let’s make the decision tree more concrete, the strata are people, and the decisions 1 vs 2 are their front pockets. I’ll be assigned to a given person, and I can choose to take the money they have in their left pocket or their right pocket.
Suppose I have *some* but not perfect information about them. For example, where they carry their wallet and where they carry their keys and change… Based on my model I can estimate a distribution for the money in their wallet, and the distribution of the amount of change they have in their favorite change pocket…
If I correctly estimate the average amount in their wallet and that this average amount is greater than the amount they have in their change pocket, and I know which pocket they keep their wallet in, then I can estimate the overall expected value of playing this game and always choosing the wallet pocket. I don’t see where I necessarily go wrong here? I mean, I can go wrong with estimating the distributions of change vs wallet, but there’s literally no situation where I can do better without having actual better information about the distribution of wallet/change right?
Maybe my scenario isn’t matching the one Andrew’s talking about?
If you sample from a person’s wallet and their pocket in order to estimate the values of each, then pick the one the highest estimated value, your choice X is a random variable, and E[E[Y | X]] =/= E[Y | X]. Another way of putting it is that you are conditioning on the positive outcome of a stochastic selection process, which creates a positive bias.
Let’s say there’s a game of who can score more most baskets in 30 seconds. You want to build a superteam of N players, but you have M > N candidates, so you do a trial run and pick N top scorers. Is the expectation of your superteam performance = the sum of their trial scores? No, because they won in part because of skill but in part because of luck and you expect some regression to the mean. This is true even though an individual player’s trial performance is an unbiased estimator of their next performance. I happen to have a jupyter notebook open doing some neural network stuff some here’s a simulation with a plot
# 30 players with differing scoring rate parameters
curr_key = main_key
player_skill = 10 * jnp.exp(jax.random.normal(curr_key, 30))
true, estimated = [], []
for i in range(5000):
# Run a trial
curr_key = jnp.squeeze(jax.random.split(curr_key, 1), axis=0)
trial_scores = jax.random.poisson(curr_key, player_skill, 30)
# pick the skills of top 10 scorers
best_players = jnp.argsort(-1.0 * trial_scores)[:10]
skills = player_skill[best_players]
scores = trial_scores[best_players]
true_expectation = jnp.sum(skills, axis=0)
score_based_mean = jnp.sum(scores, axis=0)
true.append(true_expectation)
estimated.append(score_based_mean)
true_arr, estimated_arr = np.array(true), np.array(estimated)
diffs = estimated_arr – true_arr
hist, edges = np.histogram(diffs, bins=30, density=True)
fig = bpl.figure()
fig.quad(bottom=0, top=hist, left=edges[:-1], right=edges[1:])
bio.show(fig)
https://imgur.com/a/tFkDNGP
A very streamlined example:
Say that two events have the same probability and the expected gain if you bet for one and against the other is zero. If you don’t know that and instead you have two unbiased independent estimates of those probabilities you will have an expected gain if you follow the “optimal” decision betting for one and against the other (except in those cases where you are lucky and estimate equal probability).
I think where this is getting confusing is that we are talking about expectations across different things…
First, we can take expectations Bayesianly across my state of information. My state of information is let’s say that selecting wallet will get me some amount averaging $20 and selecting change pocket will get me some amount averaging $2.50 so I would obviously select the wallet pocket. Let’s say the person I am assigned is random and chosen by a die, so I can average across my state of information, both the assumed unbiasedness of the die, and the information about what is in wallets vs change pockets… and come to an expected earnings from playing the game once.
There is nothing “biased” about this procedure in the sense that the procedure leads me to estimate something that isn’t the expected value you’d get from properly accounting for my state of information, but my information about the contents of the wallets and change pockets can certainly be *wrong*.
The purpose of a Bayesian state of information isn’t to encode the true variation in the world, that is literally impossible without literally emptying everyone’s pockets and counting the moneys, instead it’s to encode my *knowledge* of the plausible outcomes.
The problem is we’re confusing the long run frequency of outcomes with the expected value under the state of information.
But at least I understand where the confusion is coming from now.
Quote from the post: “Too bad: had we joined forces we could’ve produced something better, as each of the two papers had lots of material that was not in the other.”
Or, you could’ve produced something worse. And, the individual content of both of the two papers might now not have been known, which might not be a good thing.
One of the things I think about from time to time is the possibility of the incredibly unique role of individual papers, authors, and even writing styles or approaches in science. To me, all those separate papers, authors, and even writing styles or approaches might together form something important and crucial that certain directly-working-together papers or projects might not be able produce, and might even severely distort or make impossible.
I think I have consciously attempted more and more in recent years to try and figure out what my possible most unique or fitting contribution in science or writing or publishing papers could be, and then attempted to act and write in accordance with that. In a way, it’s psychologically soothing, because more explicit or possibly obvious signs that one is doing okay (e.g. number of citations, positive feedback from others, etc.) might not matter that much from that perspective. It’s more about tyring to keep track of and be mindful of one’s possible cards to play, so to say. However, that seems to come with it’s own psychologically tough issues though, as I think it is hard to know or determine whether one is on the right path when there are no clear signs to see or keep track of. And, it’s kind of hard or annoying for me to not know whether I am on the right path.
Would this principle also apply in other multi-step prediction/decision situations, like tournament brackets? I’m thinking, for example, World Cup or March Madness brackets. The outcome of each game could be considered to place you in a different stratum in the sense that your predictions for the outcomes of the rest of the games would be conditional on that outcome. As such, when you are making your bracket predictions prior to the tournament, could you end up being overly confident in your predictions? Would you also be overly biased in favor of teams/players with high a prior win probabilities?
The difference between the averaged optima and the average value over strata is the expected option value of the ability to delay the decision until you know what stratum you’re in, right?
Jonathan:
Yes, but in my example you know what stratum you’re in, you just don’t know its expected value. So the difference represents the hypothetical value of this additional information which in practice you will never completely have.