(this post is by Charles)
Last week, BayesComp 2023 took place in Levi, Finland. The conference covered a broad range of topics in Bayesian computation, with many high quality sessions, talks, and posters. Here’s a link to the talk abstracts. I presented two posters at the event. The first poster was on assessing the convergence of MCMC in the many-short-chains regime. I already blogged about this research (link): here’s the poster and the corresponding preprint.
The second poster was also on the topic of running many chains in parallel but in the context of models based on ordinary differential equations (ODEs). This was the outcome of a project led by Stanislas du Ché, during his summer internship at Columbia University. We examined several pharmacometrics models, with likelihoods parameterized by the solution to an ODE. Having to solve an ODE inside a Bayesian model is challenging because the behavior of the ODE can change as the Markov chains journey across the parameter space. An ODE which is easy-to-solve at some point can be incredibly difficult somewhere else. In the past, we analyzed this issue in the illustrative planetary motion example (Gelman et al (2020), Section 11). This is the type of problem where we need to be careful about how we initialize our Markov chains and we should not rely on Stan’s defaults. Indeed, these defaults can start you in regions where your ODE is nearly impossible to solve and completely kill your computation! A popular heuristic is to draw the initial point from the prior distribution. On a related note, we need to construct priors carefully to exclude patently absurd parameter values and (hopefully) parameter values prone to frustrate our ODE solvers.
Even then—and especially if our priors are weakly informative—our Markov chains will likely journey through challenging regions. A common manifestation of this problem is that some chains lag behind because their random trajectories take them through areas that frustrate the ODE solver. Stanislas observed that this problem becomes more acute when we run many chains. Indeed, as we increase the number of chains, the probability that at least some of the chains get “stuck” increases. Then, even when running chains in parallel, the efficiency of MCMC as measured by effective sample size per second (ESS/s) eventually goes down as we add more chains because we are waiting for the slowest chain to finish!
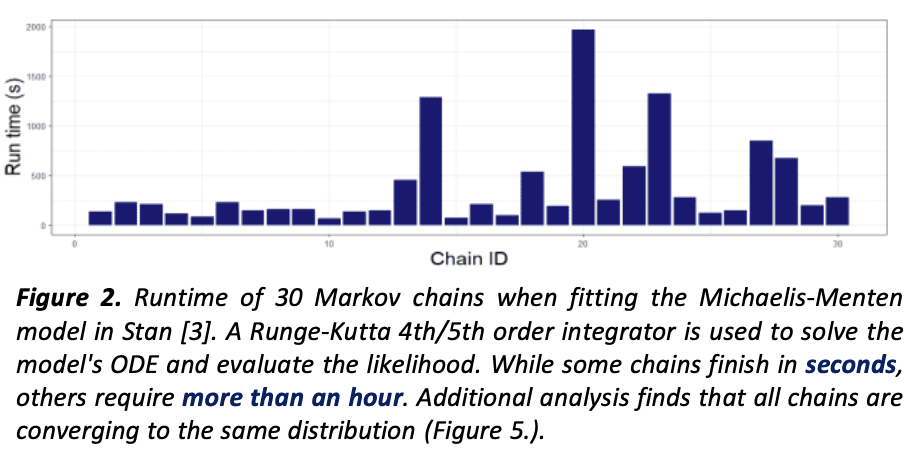
Ok. Well, we don’t want to be punished for throwing more computation at our problem. What if we instead waited for the fastest chains to finish? This is what Stanislas studied by proposing a strategy where we stop the analysis after a certain ESS is achieved, even if some chains are still warming up. An important question is what bias does dropping chains introduce? One concern is that the fastest chains are biased because they fail to explore a region of the parameter space which contains a non-negligible amount of probability mass and where the ODE happens to be more difficult to solve. Stanislas tried to address this problem using stacking (Yao et al 2018), a strategy designed to correct for biased Markov chains. But stacking still assumes all the chains somehow “cover” the region where the probability mass concentrates and, when properly weighted, produce unbiased Monte Carlo estimators.
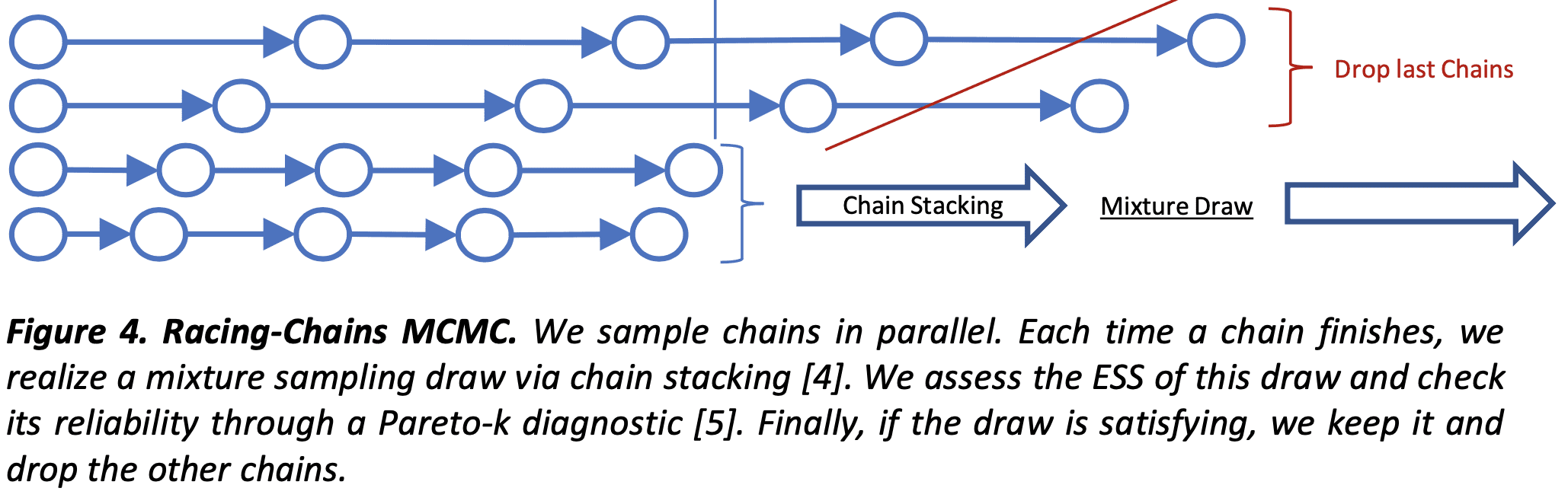
We may also wonder about the behavior of the slow chains. If the slow chains are close to stationarity, then by excluding them we are throwing away samples which would reduce the variance of our Monte Carlo estimators, however, it’s not worth waiting for these chains to finish if we’ve already achieved the wanted precision. What is more, as Andrew Gelman pointed out to me, slow chains can often be biased, for example if they get stuck in a pathological region during the warmup and never escape this region—as was the case in the planetary motion example. But we can’t expect this to always be the case.
In summary, I like the idea of waiting only for the fastest chains and I think understanding how to do this in a robust manner remains an open question. This work posed the problem and took steps in the right direction. There was a lot of traffic at the poster and I was pleased to see many people at the conference working on ODE-based models.
Hi Charles, this is a very interesting question and I really appreciate your and Stanislas’ work on the matter. The only thing I could think to add would be some quantification of which combinations of parameters most frustrated the ODE solver. Is it necessarily true that by random chance, a set of “bad” parameters was chosen from the tails of the priors which slows down the ODE? Are there any parameter draws from the “heart” of the prior that induce strong correlation and also harm the solver (which may not be the case as these are probably our “most physical” values a priori)?
I feel like evaluating the log-prior probability of the “bad” parameters may provide a diagnostic to inspect the slow chains and hope that this would be similar to looking at the regions which create divergent transitions when inspecting `pairs()` plots.
Great discussion of the bias though, double edged sword to include or exclude these slow chains, looking forward to seeing where the work goes next.
Hi Kiran,
It is indeed possible to study which parameter values frustrate the ODE solver. In the planetary motion example from the Bayesian Workflow paper, we showed that as a particular parameter, k, takes on larger values, the ODE needs to take smaller step sizes in order to achieve a wanted precision. The analysis is a bit more detailed in section 2.4.1 of my dissertation (https://academiccommons.columbia.edu/doi/10.7916/0wsc-kz90)…
You can conduct a similar analysis for the pharmacokinetic models, though we haven’t done so (I believe pharmacometricians have though). It seems that the absorption parameter, ka, influences whether the ODE is stiff or non-stiff. This informs which ODE integrator might work better. But beyond these relatively simple examples, this type of analysis can be hard to conduct. I agree a good diagnostic would be to indicate on the pairs plots where does the ODE solver fail, as we do with divergent transitions.
Now to your next question: there may indeed be parameter values at the heart of the prior or the posterior where the ODE is still very difficult to solve. Sometimes the ODE we want to solve and which makes sense physically cannot be solved efficiently or at least not with the solver we’re attempting the problem with.
Awesome. Now I just need to figure out what an ODE is. I bet it’s defined in one of the linked posters/papers…hmmm…nope….
Ah, ordinary differential equation! The Ohio Department of Education will be devastated.
Fair point. I spelled it out before using the acronym and updated the post.
Cool. Sorry about the flip comment–I plead too much caffeine!
Charles:
Just a slight correction. You write, “slow chains can often be biased, for example if they get stuck in a pathological region during the warmup and never escape this region. . . . But we can’t expect this to always be the case.”
I’d put it slightly differently. I’d say that all chains are biased, with the bias depending on the starting point. It makes sense that chains that are slower to converge will have larger biases. To put it another way, as a chan approaches convergence, its bias approaches zero.
So I think it does make sense to expect slow chains to be more biased. Not always, but generally.
I agree with your statement, “I like the idea of waiting only for the fastest chains and I think understanding how to do this in a robust manner remains an open question.”
If you are already introducing dependence between chains, rather than dropping the chains that are random walking why not pull them towards where the other chains currently are? Ie, something like gravity. For each chain you have a “mass” and distance from all the other chains, this is then used to bias the proposal distribution towards the center of “mass” of all the chains. This mass can be a constant or somehow a function of the past behavior of the chain.
Perhaps there could be a lag for chains that are far away from each other. Ie, they are biased to go where each other was 10 steps ago (or whatever it would be as a function of distance in the parameter space).
I can’t tell if this is a dumb idea or not without playing with it. Does it exist?
I think this comes back to the point that if you only ever look at the fast moving chains, that you never sample the probability mass that the slow moving chain is stuck in. Could bias away from the lower probability lobes in favor of just looking at the lobe with the largest mass.
Right, that is why I’m pretty skeptical of introducing any independence between chains. But if you are going to do it anyway, throwing away the “bad” chains seems too extreme.
What if instead of a “mass”, it was charge instead? Ie, each chain is attracted/repelled by half of the others. Idk, taking the physics analogy to its logical conclusion seems like something worth exploring though.
Kiran:
I’m not sure. Right now the default recommendation is, if the chains do not mix well, to not draw any conclusions at all, to just say we don’t yet have convergence. We also look at inferences from all the chains mixed together but we don’t take these inferences too seriously. Within this framework (accepting that we have not reached convergence so our conclusions are just tentative), I think it could make more sense to throw away the slow chains.
Of course, at this point, throwing away the slowest chains is an idea rather than a recommendation.
But this approach is not unheard of. Sequential Monte Carlo (SMC) will, at various steps, initialize multiple chains (or particles) and use a resampling step to only keep the most “relevant” particles, where relevance is assessed by using an (unnormalized) log probability density. Then, the “worst” particles are eliminated while the “best” particles are replicated. You could imagine resampling chains during the warmup phases by closely following what has been done in the SMC literature.