Last year I wrote about the value of testing observable consequences of a randomized experiment having occurred as planned. For example, if the randomization was supposedly Bernoulli(1/2), you can check that the number of units in treatment and control in the analytical sample isn’t so inconsistent with that; such tests are quite common in the tech industry. If you have pre-treatment covariates, then it can also make sense to test that they are not wildly inconsistent with randomization having occurred as planned. The point here is that things can go wrong in the treatment assignment itself or in how data is recorded and processed downstream. We are not checking whether our randomization perfectly balanced all of the covariates. We are checking our mundane null hypothesis that, yes, the treatment really was randomized as planned. Even if there is just a small difference in proportion treated or a small imbalance in observable covariates, if this is high statistically significant (say, p < 1e-5), then we should likely revise our beliefs. We might be able to salvage the experiment if, say, some observations were incorrectly dropped (one can also think of this as harmless attrition not being so harmless after all).
The argument against doing or at least prominently reporting these tests is that they can confuse readers and can also motivate “garden of forking paths” analyses with different sets of covariates than planned. I recently encountered some of these challenges in the wild. Because of open peer review processes, I can give a view into the peer review process for the paper where this came up.
I was a peer reviewer for this paper, “Communicating doctors’ consensus persistently increases COVID-19 vaccinations”, now published in Nature. It is an impressive experiment embedded in a multi-wave survey in the Czech Republic. The intervention provides accurate information about doctors’ trust in COVID-19 vaccines, which people perceived to be lower than it really was. (This is related to some of our own work on people’s beliefs about others’ vaccination intentions.) The paper presents evidence that this increased vaccination:
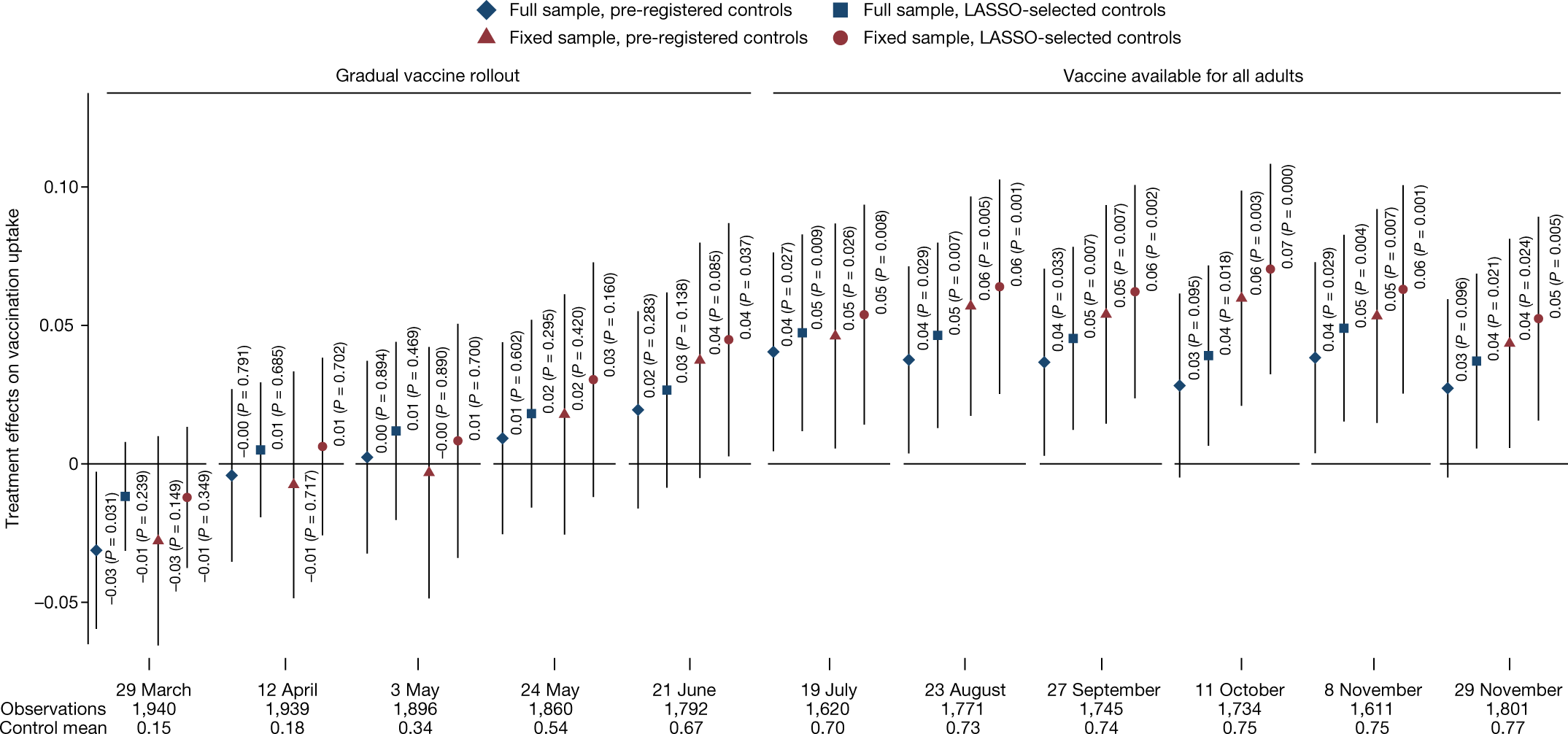
This figure (Figure 4 from the published version of the paper) shows the effects by wave of the survey. Not all respondents participated in each wave, so this creates the “full sample”, which includes a varying set of people over time, while the “fixed sample” includes only those who are in all waves. More immediately relevant, there are two sets of covariates used here: a pre-registered set and a set selected using L1-penalized regression.
This differs from a prior version of the paper, which actually didn’t report the preregistered set, motivated by concerns about imbalance of covariates that hadn’t been left out of that set. In my first peer review report, I wrote:
Contrary to the pre-analysis plan, the main analyses include adjustment for some additional covariates: “a non-pre-specified variable for being vaccinated in Wave0 and Wave0 beliefs about the views of doctors. We added the non-specified variables due to a detected imbalance in randomization.” (SI p. 32)
These indeed seem like relevant covariates to adjust for. However, this kind of data-contingent adjustment is potentially worrying. If there were indeed a problem with randomization, one would want to get to the bottom of that. But I don’t see much evidence than anything was wrong; it is simply the case that there is a marginally significant imbalance (.05 < p < .1) in two covariates and a non-significant (p > .1) imbalance in another — without any correction for multiple hypothesis testing. This kind of data-contingent adjustment can increase error rates (e.g., Mutz et al. 2019), especially if no particular rule is followed, creating a “garden of forking paths” (Gelman & Loken 2014). Thus, unless the authors actually think randomization did not occur as planned (in which case perhaps more investigation is needed), I don’t see why these variables should be adjusted for in all main analyses. (Note also that there is no single obvious way to adjust for these covariates. The beliefs about doctors are often discussed in a dichotomous way, e.g., “Underestimating” vs “Overestimating” trust so one could imagine the adjustment being for that dichotomized version additionally or instead. This helps to create many possible specifications, and only one is reported.) … More generally, I would suggest reporting a joint test of all of these covariates being randomized; presumably this retains the null.
This caused the authors to include the pre-registered analyses (which gave similar results) and to note, based on a joint test, that there weren’t “systematic” differences between treatment and control. Still I remained worried that the way they wrote about the differences in covariates between treatment and control invited misplaced skepticism about the randomization:
Nevertheless, we note that three potentially important but not pre-registered variables are not perfectly balanced. Since these three variables are highly predictive of vaccination take-up, not controlling for them could potentially bias the estimation of treatment effects, as is also indicated by the LASSO procedure, which selects these variables among a set of variables that should be controlled for in our estimates.
In my next report, while recommending acceptance, I wrote:
First, what does “not perfectly balanced” mean here? My guess is that all of the variables are not perfectly balanced, as perfect balance would be having identical numbers of subjects with each value in treatment and control, and would typically only be achieved in the blocked/stratified randomization.
Second, in what sense is does this “bias the estimation of treatment effects”? On typical theoretical analyses of randomized experiments, as long as we believe randomization occurred as planned, error due to random differences between groups is not bias; it is *variance* and is correctly accounted for in statistical inference.
This is also related to Reviewer 3’s review [who in the first round wrote “There seems to be an error of randomization on key variables”]. I think it is important for the authors to avoid the incorrect interpretation that something went wrong with their randomization. All indications are that it occurred exactly as planned. However, there can be substantial precision gains from adjusting for covariates, so this provides a reason to prefer the covariate-adjusted estimates.
If I was going to write this paragraph, I would say something like: Nevertheless, because the randomization was not stratified (i.e. blocked) on baseline covariates, there are random imbalances in covariates, as expected. Some of the larger differences are variables that were not specified in the pre-registered set of covariates to use for regression adjustment: (stating the covariates, I might suggest reporting standardized differences, not p-values here).
Of course, the paper is the authors’ to write, but I would just advise that unless they have a reason to believe the randomization did not occur as expected (not just that there were random differences in some covariates), they should avoid giving readers this impression.
I hope this wasn’t too much of a pain for the authors, but I think the final version of the paper is much improved in both (a) reporting the pre-registered analyses (as well as a bit of a multiverse analysis) and (b) not giving readers the incorrect impression there is any substantial evidence that something was wrong in the randomization.
So overall this experience helped me fully appreciate the perspective of Stephen Senn and other methodologists in epidemiology, medicine, and public health that reporting these per-covariate tests can lead to confusion and even worse analytical choices. But I think this is still consistent with what I proposed last time.
I wonder what you all think of this example. It’s also an interesting chance to get other perspectives on how this review and revision process unfolded and on my reviews.
P.S. Just to clarify, it will often make sense to prefer analyses of experiments that adjust for covariates to increase precision. I certainly use those analyses in much of my own work. My point here was more that finding noisy differences in covariates between conditions is not a good reason to change the set of adjusted-for variables. And, even if many readers might reasonably ex ante prefer an analysis that adjusts for more covariates, reporting such an analysis and not reporting the pre-registered analysis is likely to trigger some appropriate skepticism from readers. Furthermore, citing very noisy differences in covariates between conditions is liable to confuse readers and make them think something is wrong with the experiment. Of course, if there is strong evidence against randomization having occurred as planned, that’s notable, but simply adjusting for observables is not a good fix.
[This post is by Dean Eckles.]
It seems to me that uncertainty in the properties of the control group must show up as larger uncertainties in the estimations of the treatment effects. If the analysis cannot show this effect, then the analysis is missing something.
Another way to think about it is to consider that there is no control group – all participants were in the same pool – but that there is another random variable, which is whether a given person did or did not receive the treatment. Or the extra random variable could be how much of the treatment effect did each participant receive – there would be a random distribution of this amount, with some receiving the minimum amount of zero. This would be an extreme case of a dose-response curve.
Yet another way to think about this is that if the experiment produces useful results, it should be possible to predict (by analyzing the outcome and treatment data) who was in the control group and who was not. If there is so much uncertainty that one cannot tell, then the experiment has perhaps not produced useful information.
Continuing to repeat this is only squandering the trust in doctors/”science”. It was known to be false beforehand, and then obviously everyone got covid anyway after the mass vaccination campaign.
1) This has never happened for any respiratory virus ever, you get temporary immunity for up to a few months to years roughly proportional to the severity of the illness.
2) Further, intramuscular vaccines have never resulted in the mucusol immunity (IgA in the mucosa) required to have a meaningful impact on infection/transmission, because the body is exposed as if it is a systemic infection. This was then verified by the animal trials with these particular vaccines.
3) Finally, your body would never produce immunity to only the fastest mutating region of 1/29 proteins. This strategy always fails, because the virus/bacteria/cancer will just evolve resistance. And especially when you create a monoculture of antibodies towards the exact same sequence.
What you want immunity towards multiple variants of the most highly conserved regions than can be turned on within a day or so when exposed. Agile diversity is your defence, not uniformity.
Anyway, the premise of this paper is a falsehood, which should be dealt with before other issues with the data.
The claim “COVID-19 is a salient example of a disease with profound economic, social and health impacts, which can be controlled by large-scale vaccination if enough people choose to be vaccinated.” is syntactically ambiguous. It can mean either that the disease can be controlled by large-scale vaccination of enough people, or that the economic, social, and health impacts can be so controlled.
Anoneuoid’s arguments rebut the first interpretation, but not the second. And the second seems to be correct in that after the deployment of large-scale vaccination we saw a substantial decline in hospitalization and mortality. Moreover that decline was greater among vaccinated people than among the unvaccinated. Covid-19 itself remains uncontrolled: the apparent decline in infections is surely due largely if not entirely to the fact that we don’t really test for it much anymore. But the massive kill-offs that we saw early in the epidemic are no longer happening; the morgues are not overflowing, nor are the hospitals any longer bursting at the seams.
Anoneuoid’s points suggest that an ideal vaccine would be administered mucosally and wold include multiple antigens that induce antibodies against “multiple variants of the most highly conserved regions.” Certainly this makes sense, at least in theory. But I wonder (serious question, I pretend to have an answer) whether a vaccine of this nature has ever been successfully deployed against a respiratory illness, or whether it would be feasible to develop one with existing technologies. If so, would it be possible to do so in a short time scale?
As mentioned, there is only transitory mucosal immunity to respiratory viruses after infection, there is no reason to believe a vaccine that induced permanent immunity would be desirable.
If your body did that for every virus you got exposed to, you wouldn’t be able to breath. Then those viruses will mutate so those antibodies become non-neutralizing and start increasing the rate of infection. It is not a sustainable strategy.
Eg, most of these are bacteriophages, but the point is you are walking through a literal soup of viruses: https://www.newsweek.com/viruses-atmosphere-falling-800694
Anoneuoid, I doubt you are a virologist, microbiologist, or immunologist. My model of you is someone with C.S. or developer background that has quite a bit of free time to perform Google searches to annoy blog readers. (I also think you are probably of Germanic descent and have a mental illness and are within the age of 30-40, but I’m not sure about the descent thing.)
Here are other findings relating IM vaccines to protective effects:
“However, it appears that i.p. immunization generally induces non-protective mucosal (particularly the gastrointestinal) IgA responses while i.m. immunization with DNA-based vaccines is likely to induce a protective mucosal immune response including CMI.”
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4962944/
“Overall, intramuscular administration of IDLV followed by protein boosts using the sublingual route induced strong, persistent and complementary systemic and mucosal immune responses, and represents an appealing prime-boost strategy for immunization including IDLV as a delivery system.”
https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0107377
“Despite being a vaccine administered via the intramuscular route, Comirnaty, and likely other mRNA vaccines, induces S1-specific IgA and IgG in the nasal mucosa of vaccine recipients as early as 14 days after the first dose.”
https://www.frontiersin.org/articles/10.3389/fimmu.2021.744887/full#B19
My feeling is it’s a little more complicated than the either/or scenario you make it out to be, and I also feel your statements are too strong. I wish you were humble enough to not go B.S.ing a bunch of nonsense on a message board.
@Anoneuoid Please explain how measles is not a counterexample to your points 1 and 2. Thanks.
https://journals.plos.org/plospathogens/article?id=10.1371/journal.ppat.1009509
@Anoneuoid Thank you for the info and the link; very useful. Measles does contradict your points, but you merely need to elaborate on them with more detail.
Did you mean “doesn’t”?
@Anoneouid No, I did mean what I wrote. Measles IS a respiratory virus, but the vaccine does NOT give only “temporary immunity”. Furthermore, its “intramuscular vaccines” HAVE “a meaningful impact on infection/transmission”.
I see, well that paper explained the situation quite clearly (measles virus does not primarily replicate in the mucosa like influenza, coronaviruses, etc). So there is not much more to be said if you (and unanon below) are unwilling to learn enough to comprehend the papers you are reading.
Meanwhile, everyone got covid regardless of vaccination.
While most of what you listed makes sense, you forgot the main reason vaccination was helpful in select individuals (elderly, etc.) is cellular immunity. A simple exposure of, albeit simple, imitation of the virus (vaccine) administered to a naive organism, elicits cellular immunity, and that’s the only one that matters and prevents people from assuming perpetual horizontal position. Remember that entire globe was naive to this virus.
However, all of it was misunderstood and ‘immunity’ was talked about as if it’s one thing (just like ‘inflation’-there are four kinds of it). The result was this booster lunacy that is unbearable, especially when touted by some seemingly smart people.
The quoted passage was about “herd immunity”. The idea was that if everyone got vaccinated the virus would disappear, because it couldn’t find enough new susceptible hosts. Thus it was very important for everyone to get the vaccine even if they were not personally concerned or at risk.
This idea was completely false, which was pointed out at the time. Then unsurprisingly (except to those who believed this false idea) everyone got covid whether vaccinated or not.
Protection against viremia is a separate issue.
Dataviz comment: would have been much easier to read the chart if they had used 2 shapes x 2 colors instead of 4 shapes x 2 colors
Kaiser:
Also I don’t like that “comb plot” that multiplexes two dimensions onto the x-axis. I’d prefer to see a grid of 4 plots.
In the plot’s defense: 4 shapes x 2 colors ensures readability for b/w reproductions for a small cost in color readability (although solid symbols vs outlines could have replaced the colors and only required two shapes, making for the best of both worlds, but who would dream of generating a purely b/w plot nowadays anyway).
The comb plot also maximizes ability to compare visually across samples and covariates. As long as the main signal is large compared to the variation across samples and covariate sets, it works for me.
I think these work better with more visual space between the groups of points for each wave. This is made more difficult here because of the decision to print the estimates and p-values, requiring more space between each point within wave.
+1
in particular ,those p-values. should readers care about the individual p-values? 0.004 vs 0.007 etc.
On a second look, I note that the width of the CIs are roughly the same everywhere so there may be a way to simplify that.
I also prefer grids although in this case, shifting to grids causes some decisions to be made about the other dimensions.
Now that I look at it another time. I think they should have turned it around. Let time run from top to bottom.
Dean:
Getting back to the main point in your post . . . you wrote, “unless the authors actually think randomization did not occur as planned (in which case perhaps more investigation is needed), I don’t see why these variables should be adjusted for in all main analyses.”
But if a study includes a highly-predictive pre-treatment variable, then the analysis should adjust for it, right? Adjusting will tend to give a more accurate estimate of the treatment effect by removing a source of error arising from random differences between treatment and control group.
I get your point about preregistration, but (a) this could be solved by the researchers including this adjustment in their preregistration plan, and (b) I would think the adjusted analysis is better, so even if the preregistration had the unadjusted analysis, I’d still recommend doing the preferred, adjusted analysis also.
It seems to me that in your post you are mixing two issues: (1) possible evidence for botched randomization or some sort of missing data problem causing imbalance between the treatment and control groups, and (2) the question of when and how to adjust for pre-treatment variables in a randomized experiment.
Also, yes, indeed I have seen a real-life A/B test where I realized there was a problem because there were not essentially equal numbers of items in the two groups. So I could relate to your post!
I totally agree that ex ante I would prefer to adjust for these covariates. For the number of covariates, there is plenty of data to likely make the payoff in precision from linear adjustment worthwhile.
But if someone preregisters set A and then only reports set B and the empty set (no covariates), with the results looking less clear with no covariates, I think it is a different story. I think that’s consistent with the frequentist way of thinking, you sketched here https://statmodeling.stat.columbia.edu/2022/12/02/not-frequentist-enough-2/
So I wrote “These indeed seem like relevant covariates to adjust for. However, this kind of data-contingent adjustment is potentially worrying.” And, not previously quoted in this post:
“As far as I can tell, the only variation on this analysis offered is one without controls altogether (for which the estimates is not statistically significant at p < 0.05, whether for vaccine demand in wave 1, Table S9, or vaccine takeup in wave 7, Table S11). That is, we don’t ever get the preregistered analysis. This seems like an important omission, which should be corrected. This absence also seems at odds with the claim in the main text that 'Second, the effects on vaccination demand and vaccine take-up are robust to changes in the set of control variables.' Unless I am misunderstanding, again this only is true in the sense that there are some analyses entirely without covariates…"
I'm happy with including a fuller set of covariates (as they did throughout the paper, including that figure). But I wasn't happy with using vague concerns about imbalance to select covariates ex post. So I also liked the more hands-off approach of using the lasso, though still there one could worry that without specifying this in advance there can be a lot of forking paths available.