This post is by Phil Price, not Andrew.
The World Chess Championship is going on right now. There have been some really good games and some really lousy ones — the challenger, Ian Nepomniachtchi (universally known as ‘Nepo’) has played far below his capabilities in a few games. The reigning champ, Magnus Carlsen, is almost certain to retain his title (I’ll offer 12:1 if anyone is interested!).
It would take some real commitment to watch the games in real time in their entirety, but if you choose to do so there is excellent coverage in which strong grandmasters discuss the positions and speculate on what might be played next. They are aided in this by computers that can evaluate the positions “objectively”, and occasionally they will indeed mention what the computer suggests, but much of the time the commenters ignore the computer and discuss their own evaluations.
I suppose it’s worth mentioning that computers are by far the strongest chess-playing entities, easily capable of beating the best human players even if the computer is given a significant disadvantage at the start (such as being down a pawn). Even the best computer programs don’t play perfect chess, but for practical purposes the evaluation of a position by a top computer program can be thought of as the objective truth.
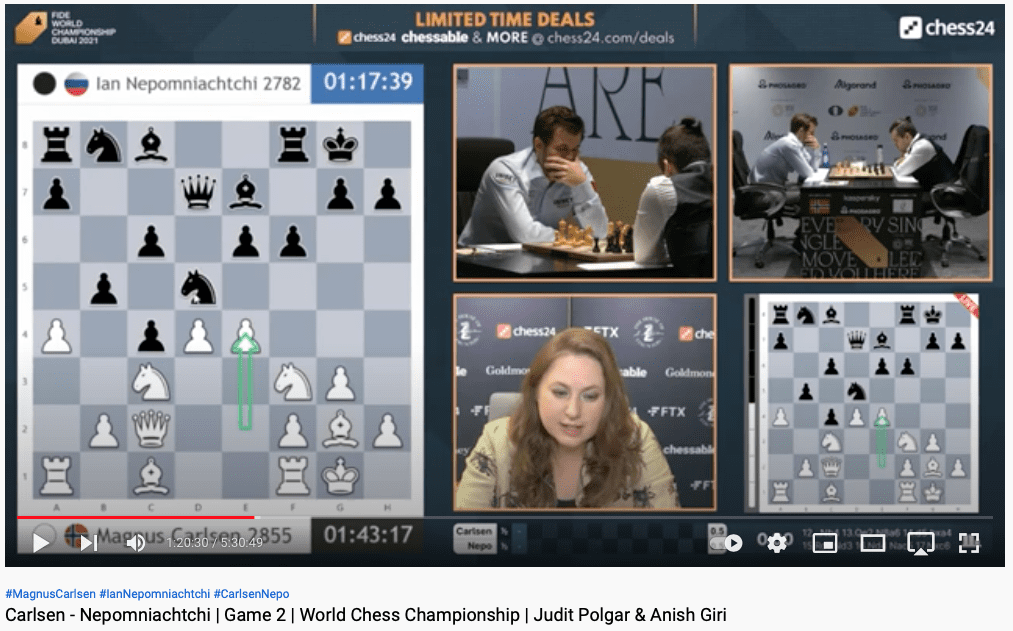
I watched a fair amount of live commentary on Game 2, commented by Judit Polgar and Anish Giri…just sort of got caught up in it and spent way more time watching than I had intended. At the point in the commentary shown in the image (1:21 into the YouTube video), the computer evaluation says the players are dead even, but both Polgar and Giri felt that in practice White has a significant advantage. As Giri put it, “disharmonious positions [like the one black is in] require weird solutions…Ian has great pattern recognition, but where has he seen a pattern of pawns [on] f6, e6, c6, queen [on] d7? Which pattern is he trying to recognize? The pattern recognition is, like, it’s broken… I don’t know how I’m playing with black, I’ve never seen such a position before. Fortunately. I don’t want to see it anymore, either.”
In the end, Nepo — the player with Black — managed to draw the position, but I don’t think anyone (including Nepo) would disagree with their assessment that at this point in the game it is much easier to play for White than for Black.
Interestingly, this position was reached following a decision much earlier in the game in which Carlsen played a line a move that, according to the computer, gave Nepo a slight edge. This was quite early in the game, when both players were still “in their preparation”, meaning that they were playing moves that they had memorized. (At this level, each player knows the types of openings that the other likes to play, so they can anticipate that they will likely play one of a manageable number of sequences, or ‘lines’, for the first eight to fifteen moves. When I say “manageable number” I mean a few hundred.). At that earlier point in the game, when Carlsen made that “bad” move, Giri pointed out that this might take Nepo out of his preparation, since you don’t usually bother looking into lines that assume the other player is going to deliberately give away his advantage.
So: Carlsen deliberately played in a way that was “objectively” worse than his alternatives, but that gave him better practical chances to win. It’s an interesting phenomenon.
Very interesting post, thanks. I vaguely recall at one time fears that if the computers got too good it would “ruin” chess, but of course that hasn’t happened, because imperfect play is what makes games interesting.
I was very into a chess app on my phone for a while during this pandemic, but I got frustrated by what I consider unsporting play in short timed games, and I don’t like totally untimed games or have time for long timed games, so I gave it up again. Oh well.
Modern chess preparation is often like this. Everyone has access to the same strong computer you can’t really hit them with a very strong move that they missed in their prep. Instead, preparation is about finding interesting and challenging moves that the computer doesn’t recommend but are practically challenging. Even if the moves leads to a forced draw or a position that is worse for you often top players will play it If it has a high surprise value or it is practically it’s very difficult and your opponent has to find a lot of hard to find or weird/counterintuitive computer moves. Surprise value is extremely important in modern chess preparation and try to get them out of their computer prep while you still have your computer prep.
Perhaps such move could also be phrased as “marginally worse, but jointly better”, which often occurs in statistics too.
I was thinking this would be marginally better but jointly worse. If one dimension is the move of the opponent and the other is the probability of the move being played and the entry is the computer evaluation I can see the best marginal move being inferior to the best response to another move, if that makes sense.
So “objective truth” may be called that only if both players are computers. But as the post points out, in real games the “truth” must be renormalized to take into account the fact that the players are human.
It’s an interesting analogy: just as there is no “real” mass of the electron, since it always is immersed in a sea of virtual particles which renormalizes the naked mass to the one we observe, in human societies there is no objective truth, since “facts” are always mediated through interactions with other humans and their constructs.
Yes, good point about…well, if something is “objectively” better, what is the objective function? If you were maximizing a function that included human capabilities, rather than computer-vs-computer, you’d choose different moves from if you’re just trying to play the “objectively best chess.”
I interpreted your statement about the computer’s assessment being objectively true, to mean that, in the long run, either player will always perform better against the other by doing what the computer would do. We know that’s true because every human player will always be beaten by a computer over sufficiently many games. However, I’m not sure the claim holds up if you play your human strategy throughout the game but then switch to the computer’s strategy at an arbitrary point. If not, the computer’s move-by-move choices will become increasingly suboptimal.
It’s more like the opposite way around, really: you play computer-approved moves as far as you can, and then at some point you’re out of your preparation and you’re forced to rely on your own wits. You can find yourself in a position the computer thinks is just fine but is very hard for you to play.
Chess players are well aware of this, of course, and not just grandmasters. For example, the very entertaining chess streamer Simon Williams (who goes by GingerGM) constantly reminds people that to improve at chess they should analyze their games afterwards and not just look at the computer evaluation. He also tells people that it’s often more important to steer towards positions that you understand than towards positions the computer says are better.
But in grandmaster play I think it’s unusual for an “objectively equal” position to be so much worse for one player than another. I can very easily find myself sliding into an unplayable position, but grandmasters can see that happening and try to steer the game another direction. The fact that even Nepo — one of the best players in the world — found himself in this predicament is what made it so noteworthy.
I don’t think it’s fair (or possible) to directly compare the human commentary with the computer output, even when they seem superficially to address the same point. They are not, in fact, making equivalent statements. For example, suppose we want to compare commentary with output to answer the question, “What move should each player make next?” Based on your description of the commentary, the commentators are free to give multiple answers, couched in different assumptions or conditions. For example, they may say: “This is what I would do” or “This is what I think the player will do.” They condition on their own skills, their knowledge of each player’s skills, and/or other factors.
But the computer (I assume) is conditioning only on both sides playing optimally for the remainder of the game. Then it just solves the relevant equations. This is “the Objective Truth” but only with respect to optimal play. We may *want* to directly compare commentary with output, and the output display probably *implies* we can. But, that’s just operationalizing a thing we want to know as a thing the computer can tell us. In reality: a) the commenters probably never condition on optimal play (unless they just say they agree with the computer’s evaluation), and b) the play will not be optimal, and c) no one ever asks the computer (or, presumably, programmed it) to condition on anything other than optimal play.
The same applies for assessing game difficulty for one side, and for predicting the winner. It’s all apples and oranges, Baby!
Human strategic encounters are often decided by one side making a mistake. It’s good strategy to achieve a position that encourages this: use the element of surprise, pretend a time pressure in a sales negotiation, etc.
A computer strategy that is developed with the assumption that the other side plays optimally can’t exploit this (except by chance).
This sort of play reminds me of the Thirty-Six Strategems. https://en.wikipedia.org/wiki/Thirty-Six_Stratagems
Maybe intentional, maybe accidental, who knows?
I want offer a slightly different take on Carlsen playing a move which is not considered best by the computer (the take is not due to me, I have heard GM commentators mention it). If it is still in Carlsen’s preparation, it is likely that he picked a move that the computer initially considered less good, but would appreciate if it analysed longer. If it is in the preparation, it would be analysed longer by Carlsen’s team. The point is that if you can find a good move that the computer initially overlooks, you can trap your opponent in his preparation. Even if he analysed the position, he may not have considered the move, because the computer dismissed it. So it is not really about the move being bad, but it being initially dismissed by the computer.
If you are offering to take either side of the 12:1 odds, I will gladly bet any amount on Carlsen winning. :) I’ve seen models put the odds at 1600:1. I don’t know how much I trust those models, but it seems a better ball park.
Many lines in chess (a “line” here means “a series of moves starting from a given position”) depend upon seeing, at the end of a line, a key move or a feature of the position. Computers are very good at calculating many moves ahead, but humans aren’t. So, humans may choose “sub-optimal” moves which are easier to calculate and/or understand.
Also, chess has a fair bit of margin of error, especially when you’re playing White (as Carlsen was doing, here). It is very common to get a “slightly worse” position and then draw it. Therefore, Carlsen could try out a “slightly worse” move in his preparation, with the confidence that he can draw it if things get out of hand.
As it happenned, Carlsen made a big mistake later on in the game, and had to scramble to draw.
“Also, chess has a fair bit of margin of error, especially when you’re playing White (as Carlsen was doing, here).”
Yes. More specifically, there are a lot of draws in chess, so as long as you are still in that space (or close enough that you can get back to it with a mere human as an opponent), it doesn’t matter if it’s “perfect” or not. In Go, there are (essentially) no draws, so the programs (and players) have to try to find the truly objectively best move. Even back in the 1960s, a “speculative attempt to complicate” was important enough to have it’s own symbol (?! or !?, I forget which…)
As I understand it, MCTS (the amazingly brilliant breakthrough that made computer Go possible) hasn’t made the impact in chess it has in Go, so chess programs still have a horizon problem. IMHO, MCTS could/should have a big impact on chess, because it evaluates actually completed positions, whereas ordinary chess programs are still calculating tactical variations within their horizon. There are people working on this, though. So maybe more progress has been made than I know about.
Also interesting is that chess programs really haven’t changed human play all that much. Openings that were old and boring back when I was playing chess (1960s/1970s), the Ruy Lopez and Petroff’s have been the mainstay of this match. Go programs have completely revolutionized openings in Go. It’s a completely new game now. (Although, interestingly, humans are adapting. A lot of pro games are near optimal by computer standards well into the game.)
A related point here is that in chess, once you are out of the opening, humans really can’t find the computer moves over the board. So a computer recommendation late in an opening analysis may not be much use, since you don’t know why it’s good and don’t know how to refute a (computer thought to be) less than optimal reply.
David:
There’s an interesting analogy here to our favorite chess writer, Christian Hesse, who copies work from chess writers who know more chess history than he does. Which wouldn’t be so bad except that he, Wegman-like, introduces errors when he does this. If Chrissy were to to just write what he knows—play his own game, as it were—he’d operate fine as a chess writer at his own level. But when he copies things he doesn’t fully understand, he ends up embarrassing himself, kinda like a player might mess up if he were to use a few moves from the chess engine and then try to complete the game on his own. It would have been better for Chrissy to just do it all on his own, or else go all out with the assistance and actually fully credit his sources. His hybrid play yields the worst of both worlds.
Andrew, why do you insist on using a “nickname” that Christian has said he finds disrespectful? https://statmodeling.stat.columbia.edu/2015/02/04/plagiarist-next-door/
Josh:
“Insist” is a bit strong! It’s just how we referred to him back in grad school.
Yes, the draw margin sheds light on an important part of the story. Among high-level players the margin is fairly wide because they have the technique to steer the game to a probable draw. Computers don’t recognize this. They will give positive evaluations to positions that are agreed-upon draws by grandmasters. You could call it a horizon effect, in that, if the position is within the tablebase (known, fully analyzed positions with just a few pieces), the machine will get it right. But it is also an evaluation issue that expresses the subtle distinction between what the computer vs the human is evaluating for. A player of Carlson’s ability senses the shadow of the draw margin almost from the start of the game; if his position is worse, he is always assessing how close it is to the outer bound of this margin. Small changes within the margin that might disturb Alpha Zero won’t disturb him.
By the way, a really fascinating special case of the draw margin is the fortress, a formation in which a player at a large material disadvantage can nevertheless prevent any defensive breach. As far as I know, no machine can recognize a fortress; they will give very large evaluation pluses to dead draws in such cases. Does anyone out there know if progress is being made on that front?
Also, I really like Anish Giri’s explanation. It truly is about pattern recognition in the end. Most of the time a player can play well almost on auto-pilot, in that the position in front of them conforms to a known pattern, and effective strategies are also known and don’t have to be invented on the spot. Skill lies mainly in the precision of implementation of those strategies, as well as quick recognition of the occurrence or just the possibility of pattern change. The “old” computer approach also relied on pattern recognition, but AI systems, which are far stronger, have shed it. That’s why they produce “weird” moves that make little sense in terms of patterned response but exploit the singular characteristics that pattern recognition obscures.
The question of whether human play has been affected by the application of machine learning comes down to whether humans are able to “pattern” the surprising choices of Alpha Zero et al. The one example I can think of is the increased human predilection for pushing wing pawns. For a long time the word was, don’t push your pawns, especially on the sides of the board, unless you can identify a concrete payoff, because they can’t move back. But the “invisible” payoffs are apparently larger than we realized, since the computers go for those a- and h-pawn pushes with regularity. So now the advice has changed. I think there is also a little more confidence in defenses that, from a traditional human point of view, seem to just barely hold things together. It’s that singularity thing again.
On a personal level, I really feel for Nepo. I was never remotely in his class, but in my own way I suffered from the same malady, susceptibility to elementary oversights. I would be coming up with what for me were creative ideas, calculating long variations, and then I would just blunder something. It’s a major reason I gave up playing. (Also, it was stop playing or kiss your dissertation goodbye. Overnight I went cold turkey.)
> program can be thought of as the objective truth
I think people can fall into a category error here as a program is just an abstraction created by some cognoscente mind and all its objective truth can be is the exhaustive implications of that abstraction.
In essence, abstractions are diagrams or symbols that can be manipulated, in error-free ways, to discern their implications. Usually referred to as models or assumptions, they are deductive and hence can be understood in and of themselves for simply what they imply. That is, until they become too complex. For instance, triangles on the plane are understood by most, while triangles on the sphere are understood by less. Reality may always be too complex, but models that adequately represent reality for some purpose need not be. Triangles on the plane are for navigation of short distances while on the sphere, for long distances. Emphatically, it is the abstract model that is understood not necessarily the reality it attempts to represent. https://www.statcan.gc.ca/en/data-science/network/decision-making
Now given chess is itself an abstraction that may not be too complex, the computer program might be a complete accurate representation of that. But any particular chess game is not an abstraction but an empirical happening which as above can never be fully understood with certainty.
You’re right, of course. I’d just add that your comments apply more to scientific models, which are usually a) created by a small number of people with shared intent, b) imbued with a particular meaning, and c) communicated, along with their output, in the context of that meaning. The models here are a special case: we don’t speak of the modeler, but of the computer, as if the computer has intent and so is capable of imbuing meaning. Our culture encourages us to anthropomorphize software, so calling this automated system “the computer” or “the program” may implicitly confer some kind of intellectual agency. We’re aided in that interpretation by a screen display that presents the output as if coming from an unseen chess commentator named “Computer.”
I believe that’s what you mean when you say the program was “created by some cognoscente mind,” but even that is potentially misleading. Yes, scientific models and the programs that operationalize them are created with specific intent as to their meaning. Here, however, we’re talking about a product for mass consumption, created by many different individuals (graphic designers, TV producers, programmers, and maybe even chess experts), whose primary intent was not expressing truth but (let’s face it) to meet a set of specifications. Probably the originator(s) of the equations underlying the algorithm were expressing truths–mathematical truths, not chess truths, and certainly not truths about this game of chess.
Consequently, one can argue that the system and its output do not convey meaning. As a product, it is given meaning by the user (the commentators) and the consumer (the viewers). These individuals want to know a thing, and they operationalize the thing they want to know as the thing the system tells them. Quite the opposite of objective!
> “created by some cognoscente mind,”
I used that phrase to avoid these considerations.
But think of a person or group of people who wrote a program – does not mean they know all it’s implications.
So think of inputs and the code as premises – there can only be one output (conclusion) given set random number seed.
So outputs may well be surprising but they are the objective truth.
I think you guys are trying too hard.
Since chess programs can’t (yet) solve chess, the values a program calculates are heuristic estimates of what result each move might give were it played. Different programs using different techniques will calculate different estimates for the expected values of the moves. There’s no truth here, absolute, objective, or otherwise, just heuristic estimates computed by various algorithms…
For example, the blokes working on Go programs (e.g. Leela, Katago) talk about superhuman programs, but not perfect programs. (Leela is a first generation reimplementation based the Google paper on Alpha Go, Katago a second generation; both use crowdsourcing of computational resources instead of Google server farms.) Also, they are still finding blind spots that even these superhuman programs mess up on and need special inputs to their training to avoid. Google was smart to take down their programs; more experience with them would have found these glitches, and people would have realized that Google wasn’t the last word in Go programming, merely the next in an ongoing story.
(There’s a rant (or a bevy of rants) at the back of my mind here. These programs are completely, totally, solely nothing more than ad hoc kludges to estimate move values in games, and have no relation whatsoever to anything that anyone who thought about it would call “intelligence”. (More generally, to quote Roger Shank, “There’s no such thing as AI” nowadays. Really. There isn’t.) The intellectual content here is MCTS vs. local tree search (in chess), larger pattern databases (that take longer to compute) vs. faster (less comprehensive) pattern matching allowing more nodes evaluated in the MCTS calculation (in Go). The philosophical content is not about “machine intelligence”, but what is a human that it’s willing and eager to spend insane amounts of time and effort writing game programs.)