This is Jessica. I was going to blog this about elicitation a few days ago, and then before I got to publishing it Aki brought up elicitation of priors for Bayesian analysis. Elicitation is a topic I started thinking about a few years ago with Yea Seul Kim, where we were focusing mostly on graphical elicitation of prior beliefs for visualization interaction or analysis. The new paper by Aki and others is a great summary of the many hard questions one can run into in eliciting knowledge. As Tony O’Hagan, who’s written extensively on elicitation, has said “Eliciting expert knowledge carefully, and as scientifically as possible, is not simply a matter of sitting down with one or more experts and asking them to tell us what they think.” But while we know the elicitation process matters, it can be very difficult to evaluate whether you’ve gotten the “right” beliefs from someone. There’s undoubtedly some effect of asking them in the first place, and a danger that the elicitation process hallucinates an unwarranted amount of detail or bias in representing their knowledge. For me it’s been the kind of topic where the more I work on it, the less confident I feel that it is working.
Anyway, prior elicitation is just one relatively well studied form of elicitation. Dan Kerrigan, Enrico Bertini and I recently looked at a sample of papers dealing with applied machine learning papers whose modeling contributions involve integrating knowledge gained from domain experts. There’s some precedent for looking at elicitation in what are called “expert systems,” which tends to be associated with developing knowledge bases and rule-based approaches to mimic expert decision making, popular in the 80s and into the 90s. We consider knowledge elicitation broadly in the context of fully automated and mixed initiative or human-in-the-loop predictive models, where there’s often some acknowledgment of the need to work with domain experts to make sure the models solve the right problem and gain intrinsic trust in the sense of aligning with the experts’ causal models, etc.
Eliciting knowledge from domain experts can play an important role throughout the machine learning process, from correctly specifying the task to evaluating model results. However, knowledge elicitation is also fraught with challenges. In this work, we consider why and how machine learning researchers elicit knowledge from experts in the model development process. We develop a taxonomy to characterize elicitation approaches according to the elicitation goal, elicitation target, elicitation process, and use of elicited knowledge. We analyze the elicitation trends observed in 28 papers with this taxonomy and identify opportunities for adding rigor to these elicitation approaches. We suggest future directions for research in elicitation for machine learning by highlighting avenues for further exploration and drawing on what we can learn from elicitation research in other fields.
We looked at a set of papers (28) that were published in ML or related areas in the last 25 years and specifically mentioned domain knowledge elicitation. In getting to these we sifted through a much larger set of ML related papers that suggested some integration of domain knowledge, but ruled out at least as many as we report on because they didn’t motivate and describe the elicitation of expert knowledge or they didn’t demonstrate the use of the elicited knowledge in a model or system. (PS If you have paper suggestions please post them in the comments, we’re interested in growing the list for future reference).
Domain knowledge can play many roles in an ML pipeline, so among those papers that did describe elicitation in some detail, we differentiate the high level goal for each described form of elicitation, including problem definition (figuring out the task, how humans currently do it, what the relevant data sources are, how to evaluate performance), feature engineering (feature relevance, transformations, etc.), model development (eliciting rules, constraints, or feature relationships), and model evaluation, not very prevalent in the sample but cases where domain expertise was used to assess the model’s performance and validate its results to improve the model.
We also break down elicitation processes into the target of elicitation (e.g., instances, feature relevance, model constraints), process details like the medium (e.g., meetings or interviews, computer app), whether the elicitation prompt is well-defined (e.g., are there clear questions or tasks that are described as being put to the expert), whether any context given to the expert to establish common ground is described (which might include describing elicitation goals, model details, notable instances, or other information to “grease the wheel”), how well structured the prompts are, how constrained the experts’ responses are, if potentially unreliable or erroneous responses were accounted for in modeling (e.g., were expert labels treated as probabilistic?), and whether or not extracted knowledge was validated (checked for consistency or reliability in some way, even if informally like by recapitulating to the expert what one learned from an interview; notably this was absent in 75% of the papers we looked at). We look at whether there’s any pre-processing required before integrating into model development, and if so, whether it’s described, and how well defined the use of the information is in the model development pipeline. Was there a predefined and unambiguous process for applying the expert knowledge in the model development pipeline? Examples where the use of the elicited knowledge is well defined would include, for example, eliciting priors on edges for a Bayesian network, incorporating a monotonicity constraint to capture the expert’s mental model of how a feature behaves, or asking experts to label certain instances for training the model. An example where it’s not would include reporting on holding workshops with domain experts like doctors to understand what they found challenging about certain diagnoses but then not saying how exactly the information that was gained informed the model.
Here’s a diagram showing how things break down in terms of goals, different types of process details, and use of the elicited info. We have to recall that these are the papers that provided enough detail to code in the first place, but overall it seems there’s a fair number of cases where the medium used to collect information isn’t specified, and tendencies to overlook how the expert is guided to think about the goals or model details as they provide information (context), to treat the elicited knowledge as given rather than formally account for uncertainty (unreliable responses not accounted for), and to not worry about validating responses. 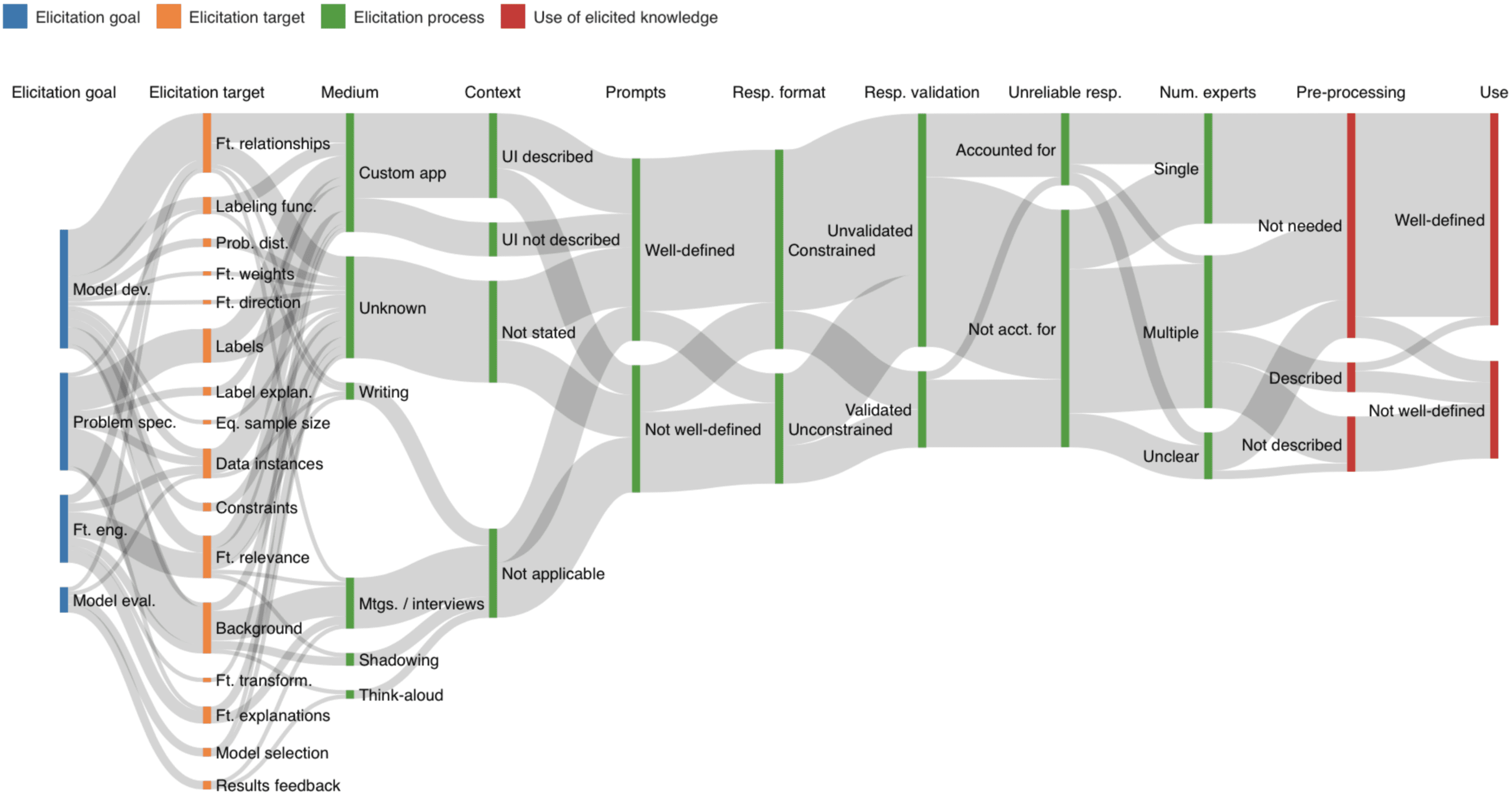
Maybe the informalness of elicitation processes that these results suggest (at least when we’re not talking about more conventional uses we saw like eliciting labels or feature relevance) isn’t that surprising, since ML has traditionally de-emphasized the human tweaking and interfacing parts. It’s still relatively recently in the history of AI/ML that ideas like intelligence augmentation, human-in-the-loop, etc. have become mainstream. Maybe the best of the old expert systems elicitation approaches should be dusted off and covered more in ML curricula.
If a bigger analysis were to find similar patterns, how important it is to increase the emphasis on more rigorous elicitation in ML? We argue that more rigor (and more development and validation of elicitation focused methods or tools) would be a worthy investment, for reasons of efficiency and transparency. If you’re not doing any validation or thinking carefully about prompting, establishment of common ground, etc. it seems easy to end up with some valid elicited knowledge and some hallucinated bits. And whenever the integration of domain knowledge is used as a selling point for the research contribution, it’s fair to expect a reproducible process that defines the target of elicitation, how the knowledge will be used, and how responses will be evaluated, rather than figuring it all out as we go.
Thanks for the paper and post.
This is an important topic for many things such as enabling interpretable machine learning and moving along Bayes versus frequentist discussions https://statmodeling.stat.columbia.edu/2021/12/02/when-confidence-intervals-include-unreasonable-values-when-confidence-intervals-include-only-unreasonable-values/#comment-2034844.
In ML, data augmentation is just a way of including prior information https://statmodeling.stat.columbia.edu/2019/12/02/a-bayesian-view-of-data-augmentation/ and would benefit from the same more thorough elicitation.
I had not heard of data augmentation, thanks!
There is some additional literature on soliciting expert opinion for simulation modeling. In addition to my book with Hubert Groenendaal, more extended discussion can be found at https://modelassist.epixanalytics.com/display/EA/Modeling+expert+opinion.
Thanks for the link!
Super cool work — sad to see this in an MDPI journal given their semi-predatory status!
https://paolocrosetto.wordpress.com/2021/04/12/is-mdpi-a-predatory-publisher/
https://academic.oup.com/rev/article/30/3/405/6348133
Yeah, I recall looking at that first link when we were considering where to send, as some part of me suspected MDPI was fishy. We first submitted it to a top human computer interaction conference on computer supported cooperative work where we’d published another oddball non technical paper on ML interpretability in organizations. They desk rejected it on the grounds that we weren’t citing enough papers from the community (I think we cited like 3) and it was more appropriate for an ML venue. We were pretty sure it would NOT go over well at an ML venue (since its not ML!) so sent it to an MDPI special issue mainly because the special issue editors were people we respect in the AI/HCI space.
My colleagues and I published one of our favorite papers, The prior can often only be understood in the context of the likelihood, in an MDPI journal. We didn’t realize the journal had these problems, and once we learned about them, it was too late!
I guess the boundary between real and fake journals is kinda fuzzy. Fake journals publish some good papers (such as ours), and real journals such as Perspectives in Psychological Science sometimes publish non-peer-reviewed crap. (Here I’m not just talking about publishing the occasional bad paper—that’s unavoidable—but publishing unvetted erroneous work via personal connections to the journal editors.) And then there was that Wiley computational statistics journal, which had lots of characteristics of a scam but was released by a reputable publisher.
I fully agree the boundary is fuzzy! That’s why I tend to point people to the two links I sent and not the spate of editorial board resignations in recent years, since the latter happens even in Elsevier-, Wiley-, whatever-MegaCorp-published venues as well. (Though, now that I’m talking about it, the one about the editorial board of Vaccines resigning after the journal published a “vaccines kill” paper is still wild to me: https://www.science.org/content/article/scientists-quit-journal-board-protesting-grossly-irresponsible-study-claiming-covid-19 ).
There definitely was a time — not even that long ago — where MDPI was fully reputable, even if some of the journals appeared to be named so people would confuse them with longer-established venues. It’s a huge shame to see them fall so far in recent years, and I definitely think a lot of people are still publishing good work in their journals as a result of those earlier years of reputation building.
What a weird industry publishing is.
Yes the boundary is fuzzy. Ultimately papers make the impact that they deserve and there are many excellent papers in MDPI, Frontiers etc. journals (I’ve published a well cited paper in Frontiers for example and in my experience the peer-review and editorial processes at Frontiers are strong). We shouldn’t be too uptight about this state of affairs even if it is really unfortunate that there are so many journals nowadays – a huge amount of unnecessary stuff is published but as I said a good paper will make the impact it deserves.
There are obviously some (lots!) absolutely trash “journals” but some of the “vaguely suspect” journals like MDPI and Frontiers are actually quite OK and we should remember that a journal isn’t a monolith and that there are likely to be some good and less good editors/sub-editors in various sections of any journal. That’s why I have a bit of a problem with this blogs trashing of e.g. PNAS or The Lancet on the basis of an example or two of less good editorial practice.
Nice graphic! (I guess to be expected given your research area)
Working with similar stuff back in the 1990,s we found that it required too many resources for most research projects – story here https://statmodeling.stat.columbia.edu/2017/01/11/the-prior-fully-comprehended-last-put-first-checked-the-least/
Also in talking to Tony O’Hagan about 7 years ago, he indicated that it was mainly large corporations that were willing to pay for it.
Don’t remember anything about costs and time delays in your paper, though I could have missed it.
Good post. No we didn’t mentions costs and time delays, but I imagine the amount of effort/preplanning required to go through a process like you describe is a big part of why elicitation processes seem ad hoc in some of the papers we looked at. As someone who has done a couple software related projects where we worked with domain experts, I know how hard it can be to get time with them at all.