This post is by Ryan Bernstein. I’m a PhD candidate at Columbia with Andrew and Jeannette Wing.
Right now, each probabilistic program we write represents a single model. As we tackle a modeling task, we try one model after another, and old programs pile up in our “models” folder or git history. What if instead of describing one model at a time, we focused on drawing a map of our model space? What if a program represented not a single probabilistic model, but a whole network of models and their rich interconnections, a region of model space that grew as we explored?
If we drew maps of model space as we experimented, it would be easier for others to follow our work. We could annotate regions of our map, like “These models rely on a big assumption,” or “Here, there be dragons convergence issues.” We could draw our path of exploration, from our first experiment to our final model and all of the false turns along the way. We could document, “This way was too slow”, or “This way gave strange prior predictions”, or “I didn’t have time to explore this way, maybe you should.” Issues like the Garden of Forking Paths and P-hacking make it clear that how and why a model was grown is necessary context for assessing its trustworthiness; model space maps would act as living documentation of that context.
Having a map would also help us navigate through model space as we explore. We could orient ourselves in model space by contrasting our current model to its immediate neighbors: we could say things like, in that direction, a posterior mean trends upwards, or calibration issues appear, or predictive accuracy improves.
Once we sketch out a region of model space, we could deploy robot servants to help us understand it. They could scout ahead for models that are accurate, simple, or robust. They could also check that our conclusions don’t depend too much on any one turn we made along our route, ala the Garden of Forking Paths. Maps enable automation, and automation can save us time and catch our errors.
So what kind of program can represent a growing network of models while remaining concise and readable?
I’ve developed a simple metaprogramming feature called ‘swappable modules’1 that can extend languages like Stan to do just that. Each ‘modular Stan program’ can compile down to a whole set of normal, ‘concrete’ Stan programs. For now we’ll treat model space as a discrete2 network of models and we’ll assume that the data is consistent across the network.
First I’ll introduce ‘modular Stan’ alongside a trivial example, and then I’ll give two more interesting case studies. You can play along at home with my prototype compiler and interactive visualizations at https://ryanbe.me/modular-stan.html. You can load each example with the buttons on the lower left, or you can write your own modular program. Expect plenty of bugs!
A way to program maps
Suppose we have some data x that we believe to be normally distributed. Let’s write a modular Stan program to represent a region of the model space of x.
Modular Stan programs start with a base, and then they are built up by adding one piece, or module, at a time. The base is part of every model we produce, so it should only contain things we’re sure won’t change: the shape of the data, the key inferred quantities, and a basic outline of the model. Here is the base for our `x` modular program:
data { int N; vector[N] x; } model { x ~ normal(Mean(), Stddev()); }
So far this is like a Stan program except that it has two “holes” in it, Mean and Stddev, that represent as-yet undefined behavior.
Next, we write a module to fill in each hole. A module can contain arbitrary code and declare new parameters like a miniature Stan program, and it can also return a value.
Here’s a module to fill in the Mean hole:
module "standard" Mean() { return 0; }
This reads as: define a module called "standard" that fills the Mean hole with 0.
Here’s a module to fill Stddev:
module "standard" Stddev() { return 1; }
Our modular Stan program up to this point is equivalent to a single concrete Stan program:
data { int N; vector[N] x; } model { x ~ normal(0, 1); }
This isn’t very interesting, so let’s explore the model space a little bit more. We can explore by simply adding more modules.
Let’s try modeling the mean of x as a random variable. We add a module called "normal" to fill the Mean hole with a new parameter that has a prior:
module "normal" Mean() { parameters { real mu; } mu ~ normal(0, 1); return mu; }
If we use "normal" to fill Mean and "standard" to fill Stddev, the concrete Stan program will be:
data { int N; vector[N] x; } parameters { real mu; } model { mu ~ normal(0, 1); x ~ normal(mu, 1); }
Since we now have two ways to fill the holes, our modular Stan program is equivalent to a set of two concrete Stan programs.
Now suppose we also want to model the standard deviation, but we aren’t sure whether or not to use an informative prior (sorry for the contrived example). We can leave that decision as another hole:
module "lognormal" Stddev() { parameters { real<lower=0> sigma; } sigma ~ lognormal(0, StddevInformative()); return sigma; } module "yes" StddevInformative() { return 1; } module "no" StddevInformative() { return 100; }
StddevInformative is a hole nested inside the module "lognormal". In this way, modular programs are hierarchical as well as branching. We can view modular programs as trees3:

Our modular program now represents a set of six concrete models, one for each way the set of holes can be filled: two ways for Mean ("standard" and "normal") times three ways for Stddev ("standard", "lognormal" with StddevInformative: "yes", and "lognormal" with StddevInformative: "no".).
How do we build a network from this set of programs? There’s a natural definition: we draw an edge between two models if they differ by only one module4. Each neighbor is then one ‘decision’ away5. Here is the network of models for this trivial example:

A representation of the network of models for the “x” example. Edges are annotated with “hole” that differs between the two models. The prototype website has an interactive version of this visualization.
‘Golf’ Example: A travelogue through model space
I’ve rewritten Andrew’s golf case study as a modular program to show what it would look like to write a case study as a “travelogue” of development through model space.
In the case study, the modeling task is to understand a golfer’s chance of sinking a shot given their distance from the hole. Like before, we’ll start by writing an outline of the problem that will be constant for the whole model space:
data { int J; // Number of distances vector[J] x; // Distances int n[J]; // Number of shots at each distance int y[J]; // Number of successful shots at each distance } model { y ~ NSuccesses(n, PSuccess(x)); }
We start with two holes: NSuccesses is the distribution of the number of successful shots given the number of attempts n and the probability of success; PSuccess is the probability of success given the distance from the hole x.
A good way to count successes is the Binomial distribution, so let’s add a module called “binomial” to fill NSuccesses:
module "binomial" NSuccesses(y | n, p) { y ~ binomial(n, p); }
Now we need a module for PSuccess to map the distance of a shot x to the probability of success. We start with a logit function:
module "logistic" PSuccess(x) { parameters { real a; real b; } return logit(a + b*x); }
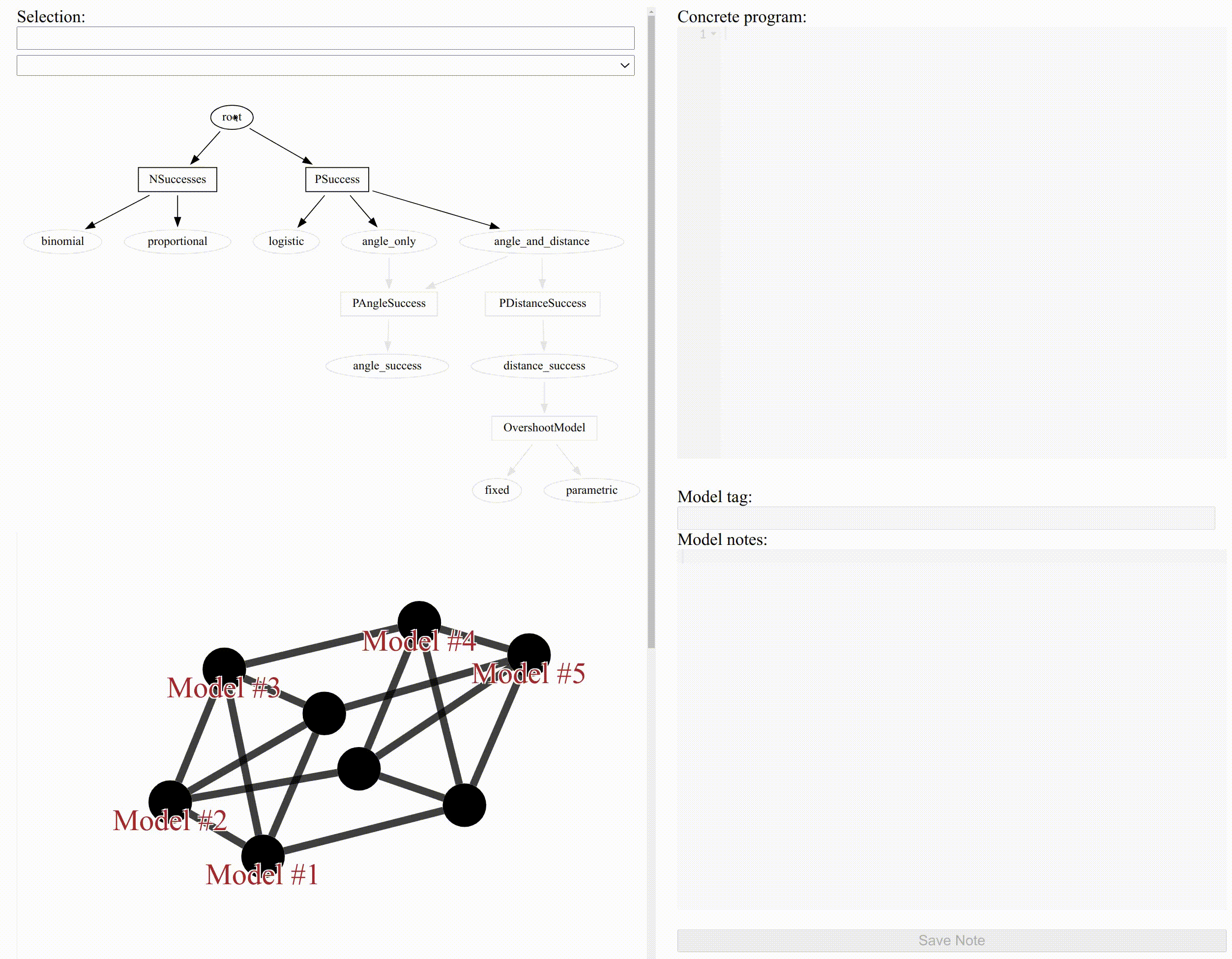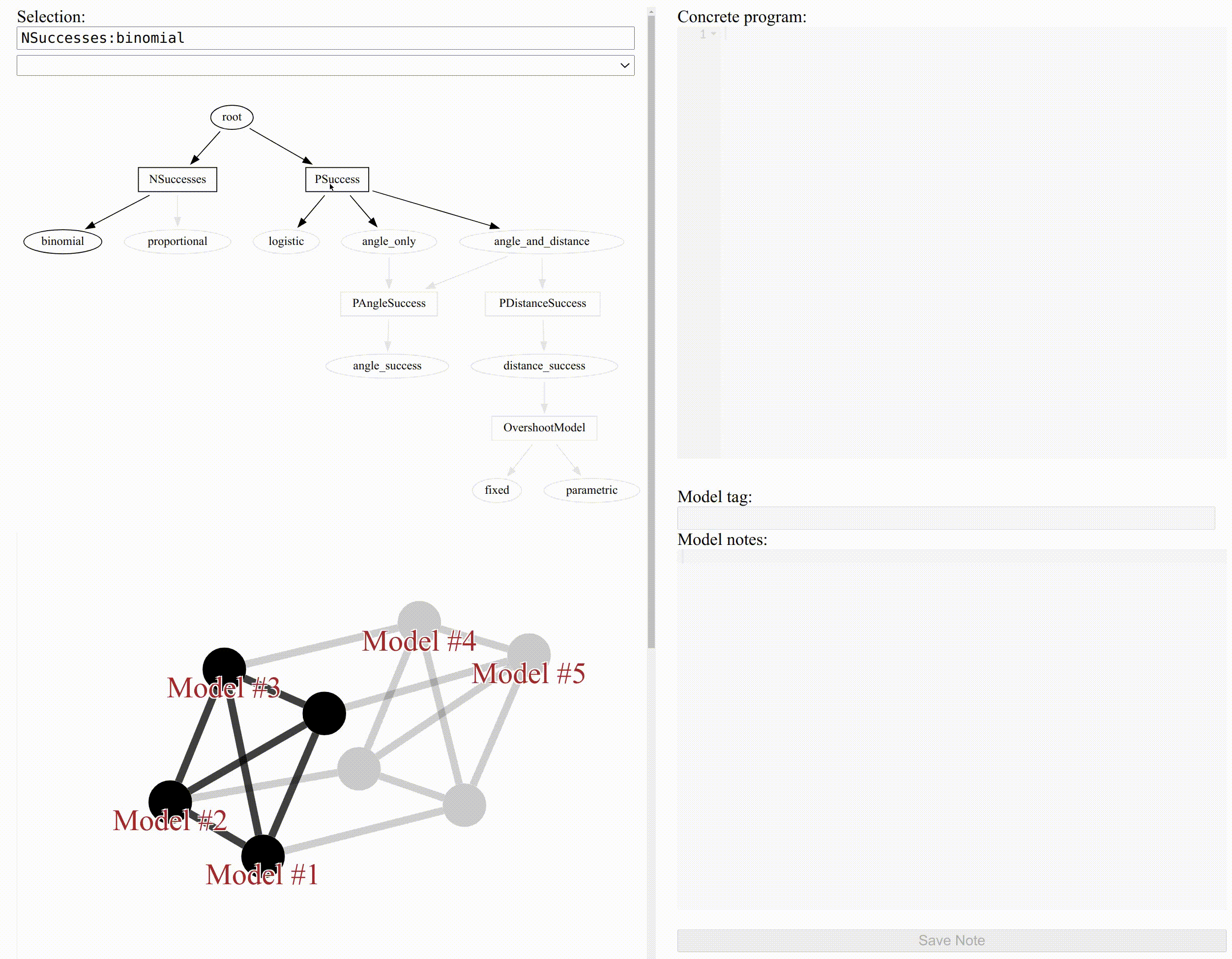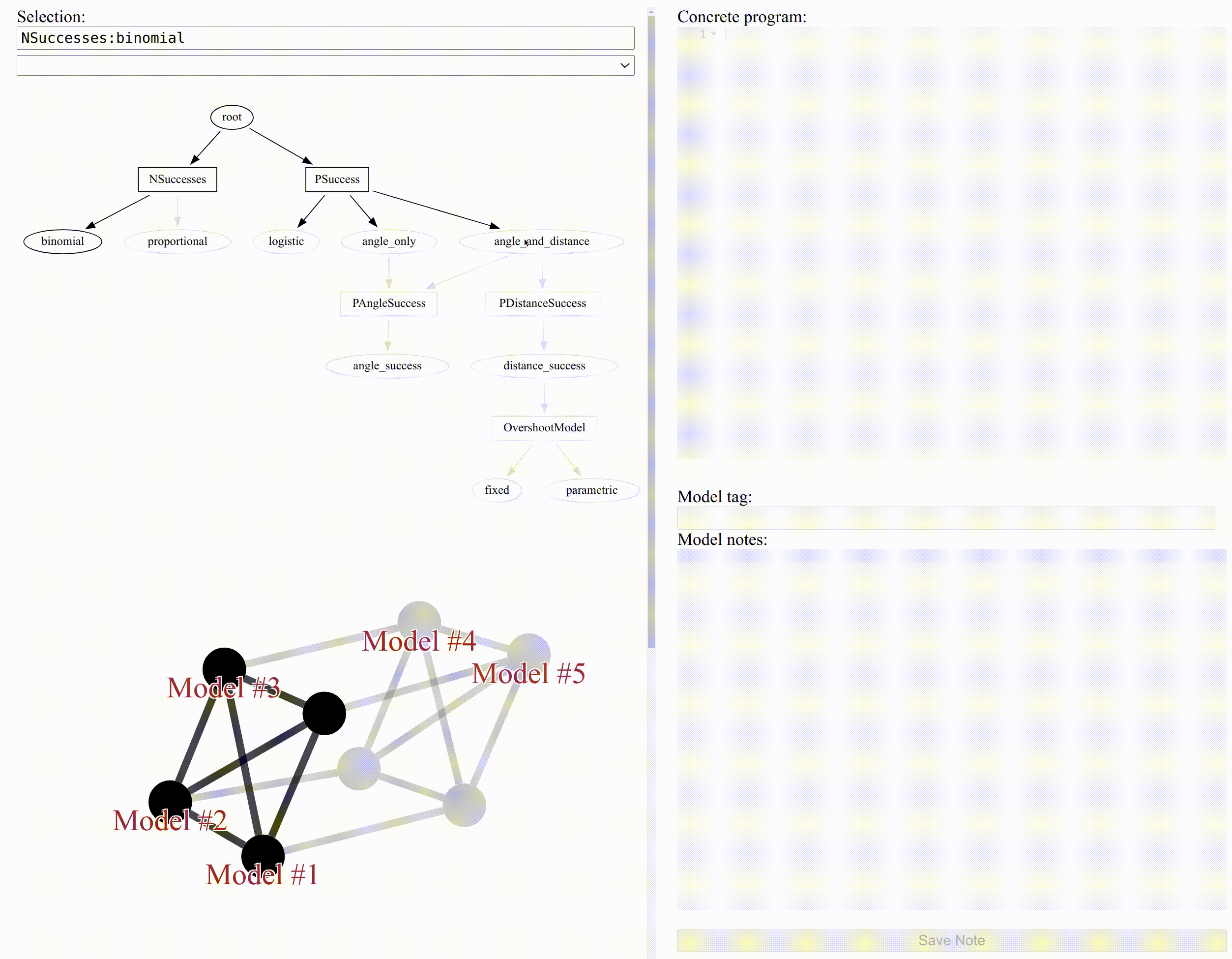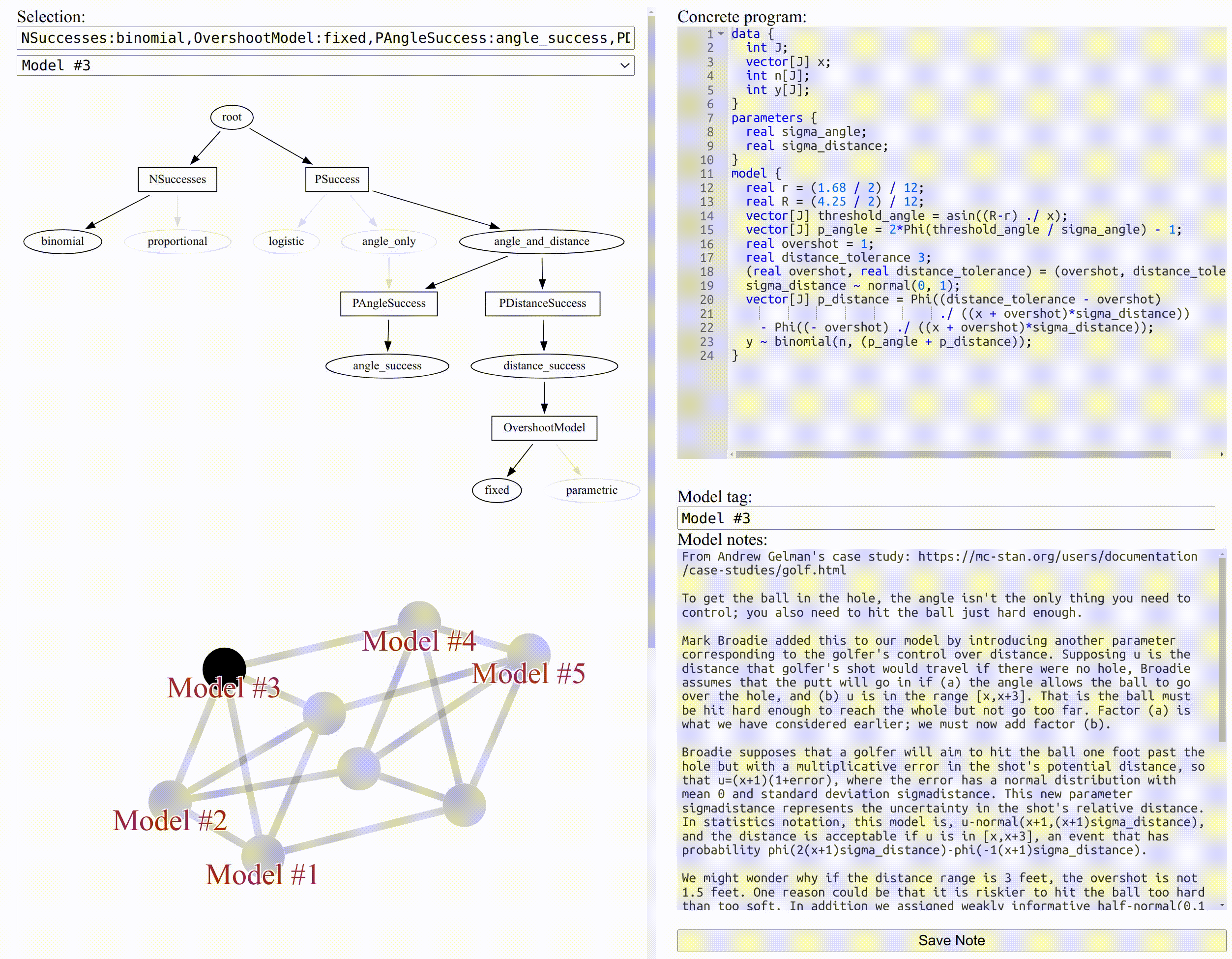
We’ve now defined logistic regression, the first model from the case study:
data { int J; // Number of distances vector[J] x; // Distances int n[J]; // Number of shots at each distance int y[J]; // Number of successful shots at each distance } parameters { real a; real b; } model { y ~ binomial(n, logit(a + b*x)); }
In this fashion, we can add a new module for each step of Andrew’s logic in the case study. See the full modular program here: https://ryanbe.me/modular-stan.html?example=golf.
Let’s use my prototype graphical interface to visualize the resulting modular program. Here are the parts of the interface:

1. Modular program editor with compile and load buttons. 2. Interactive module tree. 3. Interactive network of models. 4. Selected concrete Stan program, if any. 5. Label and documentation editor for the selected concrete program, if any.
We can select modules to narrow down the network of models to a single concrete model, as shown in the figure at the top of this post.
And finally we can see the case study as a “travelogue” that documents a path through the network of models:

‘Birthday’ Example: Exploring model space with “scouting robots”
To demonstrate automation on the network of models, I’ve rewritten the Birthday case study from as a modular program. I collaborated with Hyunji Moon to build this demo.
The goal of the birthday case study is to understand trends in the number of births over time. The authors use a Gaussian process time series model, and they experiment with including a few different types of trends (e.g. day-of-week, day-of-year, holidays, seasonal) and other modeling decisions (e.g. the weighting structure of days-of-week scores and the choice of hierarchical priors on day-of-year scores). When each trend inclusion or other modeling decision is represented as an independent choice of module, the modular program represents 120 models.
You can load the example with the full source code at https://ryanbe.me/modular-stan.html?example=birthday.
Here is the network of modules:

Suppose we want to find a model that does a reasonable job of fitting our time-series birthday data. That’s a lot of possibilities to explore manually! So let’s enlist a friendly robot to search the network for promising models.
We send off our robot with instructions for a greedy search:
“Start here.
Score the neighbors of every model you visit.
Move to the highest scoring model you’ve seen so far.
If you’re already at the highest scoring model, stop searching.”
This is like discrete gradient descent. We equip our robot with a scoring method: Expencted Log-Predictive Density (ELPD) is a reasonable choice that approximates goodness-of-fit.
Here is the data our robot collects:

The red annotations show the ELPD scores for the assessed models. The robot traveled along the arrow path from [START] to [GOAL].
In this case the robot ended its search at the case study’s final model. This optimization amounts to simple symbolic regression on probabilistic programs.
While greedy maximization of ELPD is naive and we shouldn’t blindly trust it to give us our final model, we can at least use it to find promising neighborhoods. I hope this serves as a proof of concept to open the door for other, smarter network-wide algorithms.
Future work
I hope that model space “maps” will give us new “navigation” tools for development, enable automatic search and validation, and help others to understand and reuse our work.
There’s a ton of opportunity for development in this area, such as:
- What other algorithms can run on a network or neighborhood of models? What other scores would be useful to optimize?
- How should we decorate network edges to support model navigation? What about for special cases like causal inference?
- Can we validate modules themselves6?
- Can we build libraries of modules?
- Can we learn to synthesize modules?
- Can we automatically ensemble or stack models in a network?
- Can we include automated model transformations in the network in addition to module-swapping transformations?
- If we’re fitting models in a network one after another, can we use their relatedness to sample more efficiently?
- Are there extensions of the module-swapping system or other metaprogramming features that would be worth the added complexity7?
If you have any questions or ideas, please leave a comment or reach me directly at ryan[dot]bernstein[at]columbia.edu!
Footnotes:
A more technical programming languages term might be, ‘module system with non-deterministic functor application’.
We can treat the model space as discrete by unifying models that differ only by the values of continuous hyperparameters. Those hyperparameters can be optimized (or modeled) independently from the network of models approach.
It is possible for modular programs to not form trees when two modules contain the same hole, but all modular programs form DAGs.
Strictly speaking, to account for holes like
StddevInformative that aren’t always in use, two models are neighbors if they differ by one subtree of modules.
To paraphrase Bob’s 2021 ProbProg talk: modularity is the elephant in the room, but its big challenge is testing modules in isolation. The next best alternative may be to test within a modeling context by a sort of swap-one-out validation.
For example: a special type of “hole” that’s filled with a collection of modules and returns their values as an array. This would be useful for cases like including a subset of features in a regression or components of a Gaussian process.
Pretty cool. Thanks for sharing.
It looks really great. I have a few immediate thoughts:
1. Many of these models are nested: one node includes other nodes as special cases (e.g. set some parameters = 0). How to represent this nested relation on your graph?
2. Can we separate the structure of the model and the concrete prior values (e.g., setting some parameter = 0 changes priors, but the model structure remains the same)
3. For the purpose of “model diversity”, I would argue the most useful case if when we have non-nested models. We have some theory on model diversity. But how would that guide automatic model building? I don’t know.
4. LOO-ELPD is not model-selection consistent for nested models.
Thanks Yuling!
1. You can see this come up in the first example, where there’s a module “StddevInformative” that’s nested in one of the “Stddev” modules. In the model graph, we treat two models as neighbors if they differ by either “StddevInformative” or by “Stddev”. I said a little more about this in footnote #4.
2. Yeah, it could make sense to distinguish between choosing values (I think of them as hyperparameters) and structural changes, but there’s nothing build into this system to distinguish them. You could still use the trick of making a data variable.
3. That’s interesting, what do you mean about the theory of model diversity? It sounds like it could be a good guide for model synthesis but also for network exploration.
4. Good point, we had some discussion about that. ELPD won’t work in all cases. It’s still not very clear to me exactly when ELPD is comparable between two models.
Well, this is really cool! Thanks for sharing.
Since we’re talking about visualising (meta)-models, is there currently a way to visualise the graphical model implied by a stan file? Similar to what is feasible in PyMC3? https://docs.pymc.io/en/v3/pymc-examples/examples/case_studies/moderation_analysis.html?highlight=graphical
Mm:
A Stan program defines a target function and, thus, implicitly, a joint distribution of all parameters, which in turn implies a conditional dependence structure (which is sometimes called a “graphical model”). So I guess this could be done, as long as it’s not required that it necessarily be 100% correct. I don’t see how it could be done in complete generality because dependence can be entangled in the internal computations of the code.
What we’ve been talking about is the opposite: a Stan wrapper where the user specifies the graphical model, which is then converted into a Stan program.
There are Stan programs that cannot be mapped into a “graphical model”/”generative model”, or at least not explicitly:
For example, we may use
Target += – (theta[i]-theta[i-1])^2.
to encode some smoothness condition on a vector. We may argue it is an AR model with normal error. Fine, but now consider the case in which we regularize a covariance matrix cov[n][n]:
Target += – lambda * (cov -Id)^2.
It is not a named distribution. It is also not directly generative because Id + noise is not necessarily a covariance matrix— yet it is still a valid prior regularization.
The point is that Stan does support more than fully-generative models—these loss function based models are sometimes called generalized Bayesian update. I believe you can find some connections to semiparamtrics too.
For inference, it is fine to run a “non-generative” model in Stan. For predictive check, it is also ok because it is still generative on data. But we cannot (directly) run fake data simulation or SBC here!
Yuling:
You’re making two valid points. Just to separate them for convenience:
1. Stan defines an objective function, which when exponentiated can be interpreted as an unnormalized joint posterior density. But this density is not necessarily “proper” and normalizable. It can have an infinite integral, in which case there’s no joint distribution.
2. When writing a Stan program, the resulting objective function can be any function of parameters and data, and there’s no requirement that it be a generative model for the data.
If the function is not normalizable then also Stan won’t sample from it in any meaningful way. For example the sampler will probably drift off to infinity in some direction and never come back. You won’t have a distribution to sample from.
yup
Fair enough, I fully understand these points — I still think it would be valuable for most common use-cases, to attempt to draw a graphical representation.
In cases of ambiguity, or where an arbitrary computation is involved, the drawer can issue a warning and fail gracefully.
Re the opposite (a Stan wrapper where the user specifies the graphical model, which is then converted into a Stan program), I suppose it might be useful (and less ambiguous?) but is it more efficient than writing down the model statements?
Thank you!
As Andrew said, we can’t always get a directed graphical model from a Stan program, only when the conditional dependency structure works out. I did actually write a tool to extract and visualize the directed graph when it is present. I built it for this paper: https://arxiv.org/abs/2008.09680. The bad news is it’s still janky prototype on GitHub.
Cool!
For the robot searching through the network –
It seems the network is defined by the user in that the nodes are modeling decisions made and the edges link these decisions. If every possible decision were known and every possible model made, then one could imagine this massive network. But the network that we end up with is actually a subset of this giant network with many holes and large gaps in the space and maybe extra long edges with missing nodes between. The robot can only follow a path in the scaffold where edges and nodes exist, but this of course ignores the giant real network with invisible chunks in the scaffold where entire neighborhoods might not exist. Is this tool designed to possibly inform about these missing neighborhoods or the real network, or is it only for whatever the modeler constructs on their own, anyway? Seems like it might matter? Or is that an impossibly unrealistic concept anyway?
Thanks!
That’s right, this tool currently can only navigate the network that’s defined by the user’s modular program; it can’t detect missing alternatives or suggest new ones. We could go beyond user’s networks if we had standard libraries of modules or if we could automatically synthesize modules. It’s hard to say what “the real network” would be.
Your model graphs looks similar to
https://en.wikipedia.org/wiki/Kabbalah#/media/File:Sefiroticky_strom.jpg
This is actually a great way to visualize the “researcher degrees of freedom” that an investigator acknowledges as part of developing a model.
Looks very promising, thanks for sharing.
> We can treat the model space as discrete by unifying models that differ only by the values of continuous hyperparameters.
Well some (e.g. CS Peirce) would claim otherwise.
Models are possibilities, abstract mathematical creations and between any two this is _in between_ abstract mathematical creation. Think of a mixture model.
Unlikely of any importance as some finite subset will be more than adequate.
Thanks!
> Models are possibilities, abstract mathematical creations and between any two this is _in between_ abstract mathematical creation. Think of a mixture model.
I see what you mean, fair point. I think what I wrote becomes correct when you think of models as programs.
Ryan:
Thanks for the post. This looks really cool. I’ve been talking about the network of models for awhile, but there’s a big difference between a vague idea and a live demo. Thanks also to Hyunji for collaborating on this, as it relates to her work on joint distributions and generative models. It’s great to see all these strands of research connecting. There’s nothing more rigorous than a computer program.
Thanks Andrew I appreciate it.
Ryan,
Very cool project! Have you seen this? https://proceedings.neurips.cc/paper/2018/file/b59a51a3c0bf9c5228fde841714f523a-Paper.pdf
It’s a related, but distinct idea.
I hadn’t seen that. Fascinating! Thanks.