“You took my sadness out of context at the Mariners Apartment Complex” – Lana Del Rey
It’s sunny, I’m in England, and I’m having a very tasty beer, and Lauren, Andrew, and I just finished a paper called The experiment is just as important as the likelihood in understanding the prior: A cautionary note on robust cognitive modelling.
So I guess it’s time to resurrect a blog series. On the off chance that any of you have forgotten, the Against Arianism series focusses on the idea that, in the same way that Arianism1 was heretical, so too is the idea that priors and likelihoods can be considered separately. Rather, they are consubstantial–built of the same probability substance.
There is no new thing under the sun, so obviously this has been written about a lot. But because it’s my damn blog post, I’m going to focus on a paper Andrew, Michael, and I wrote in 2017 called The Prior Can Often Only Be Understood in the Context of the Likelihood. This paper was dashed off in a hurry and under deadline pressure, but I quite like it. But it’s also maybe not the best place to stop the story.
An opportunity to comment
A few months back, the fabulous Lauren Kennedy was visiting me in Toronto on a different project. Lauren is a postdoc at Columbia working partly on complex survey data, but her background is quantitative methods in psychology. Among other things, we saw a fairly regrettable (but excellent) Claire Denis movie about vampires2.
But that’s not relevant to the story. What is relevant was that Lauren had seen an open invitation to write a comment on a paper in Computational Brain & Behaviour about Robust3 Modelling in Cognitive Science written by a team cognitive scientists and researchers in scientific theory, philosophy, and practice (Michael Lee, Amy Criss, Berna Devezer, Christopher Donkin, Alexander Etz, Fábio Leite, Dora Matzke, Jeffrey Rouder, Jennifer Trueblood, Corey White, and Joachim Vandekerckhove).
Their bold aim to sketch out the boundaries of good practice for cognitive modelling (and particularly for the times where modelling meets data) is laudable, not least because such an endeavor will always be doomed to fail in some way. But the act of stating some ideas for what constitutes best practice gives the community a concrete pole to hang this important discussion on. And Computational Brain & Behaviour recognized this and decided to hang an issue off the paper and its discussions.
The paper itself is really thoughtful and well done. And obviously I do not agree with everything in it, but that doesn’t stop me from the feeling that wide-spread adoption of their suggestions would definitely make quantitative research better.
But Lauren noticed one tool that we have found extremely useful that wasn’t mentioned in the paper: prior predictive checks. She asked if I’d be interested in joining her on a paper, and I quickly said yes!
It turns out there is another BART
The best thing about working with Lauren on this was that she is a legit psychology researcher so she isn’t just playing in someone’s back yard, she owns a patch of sand. It was immediately clear that it would be super-quick to write a comment that just said “you should use prior predictive checks”. But that would miss a real opportunity. Because cognitive modelling isn’t quite the same as standard statistical modelling (although in the case where multilevel models are appropriate Daniel Schad, Michael Betancourt, and Shravan Vasishth just wrote an excellent paper on importing general ideas of good statistical workflows into Cognitive applications).
Rather than using our standard data analysis models, a lot of the time cognitive models are generative models for the cognitive process coupled (sometimes awkwardly) with models for the data that is generated from a certain experiment. So we wanted an example model that is more in line with this practice than our standard multilevel regression examples.
Lauren found the Balloon Analogue Risk Task (BART) in Lee and Wagenmakers’ book Bayesian Cognitive Modeling: A Practical Course, which conveniently has Stan code online4. We decided to focus on this example because it’s fairly easy to understand and has all the features we needed. But hopefully we will eventually write a longer paper that covers more common types of models.
BART is an experiment that makes participants simulate pumping balloons with some fixed probability of popping after every pump. Every pump gets them more money, but they get nothing if the balloon pops. The model contains a parameter ($latex \gamma^+$) for risk taking behaviour and the experiment is designed to see if the risk taking behaviour changes as a person gets more drunk. The model is described in the following DAG:
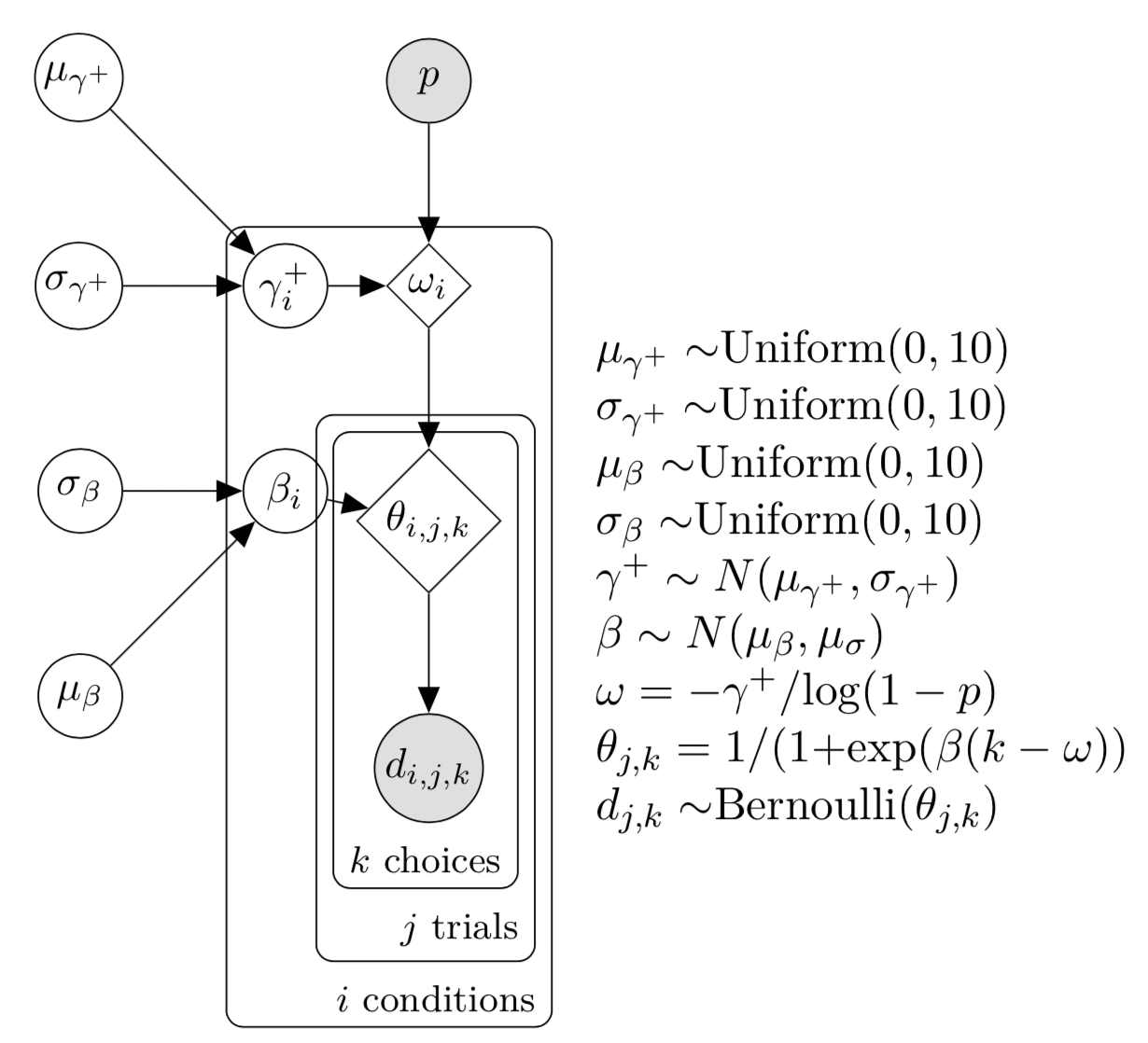
Exploring the prior predictive distribution
Those of you who have been paying attention will notice the Uniform(0,10) priors on the logit scale and think that these priors are a little bit terrible. And they are! Direct simulation from model leads to absolutely silly predictive distributions for the number of pumps in a single trial. Worse still, the pumps are extremely uniform across trials. Which means that the model thinks, a priori, that it is quite likely for a tipsy undergraduate to pump a balloon 90 times in each of the 20 trials. The mean number of pumps is a much more reasonable 10.
Choosing tighter upper bounds on the uniform priors leads to more sensible prior predictive distributions, but then Lauren went to test out what changes this made to inference (in particular looking at how it affects the Bayes factor against the null that the $latex \gamma^+$ parameters were the same across different levels of drunkenness). It made very little difference. This seemed odd so she started looking closer.
Where is the p? Or, the Likelihood Principle gets in the way
So what is going on here? Well the model describe in Lee and Wagenmaker’s book is not a generative model for the experimental data. Why not? Because the balloon sometimes pops! But because in this modelling setup the probability of explosion is independent of the number of pumps, this explosive possibility only appears as a constant in the likelihood.
The much lauded Likelihood Principle tells us that we do not need to worry about these constants when we are doing inference. But when we are trying to generate data from the prior predictive distribution, we really need to care about these aspects of the model.
Once the context on the experiment is taken into account, the prior predictive distributions change a lot.
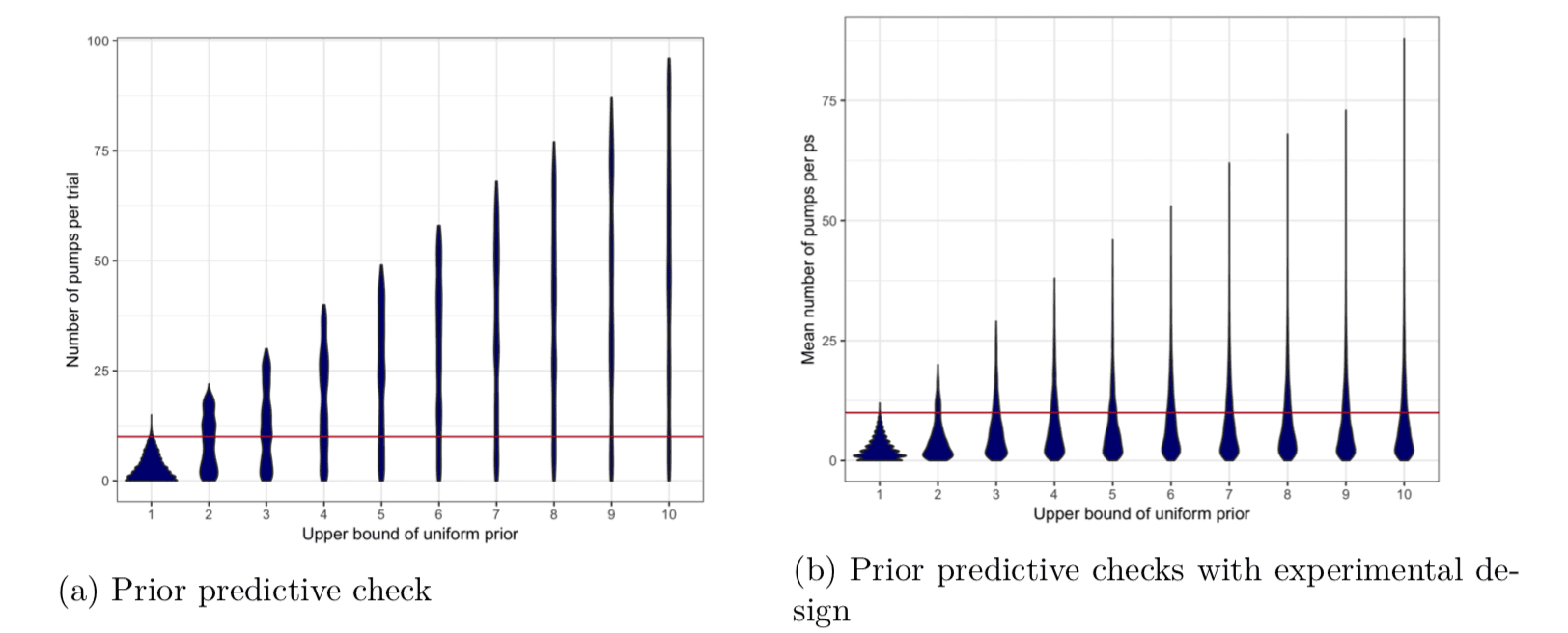
Context is important when taking statistical methods into new domains
Prior predictive checks are really powerful tools. They give us a way to set priors, they give us a way to understand what our model does, they give us a way to generate data that we can use to assess the behaviour of different model comparison tools under the experimental design at hand. (Neyman-Pearson acolytes would talk about power here, but the general question lives on beyond that framework).
Modifications of prior predictive checks should also be used to assess how predictions, inference, and model comparison methods behave under different but realistic deviations from the assumed generative model. (One of the points where I disagree with Lee et al.‘s paper is that it’s enough to just pre-register model comparision methods. We also need some sort of simulation study to know how they work for the problem at hand!)
But prior predictive checks require understanding of the substantive field as well as understanding of how the experiment was performed. And it is not always as simple as just predict y!
Balloons pop. Substantive knowledge may only be about contrasts or combinations of predictions. We need to always be aware that it’s a lot of work to translate a tool to a new scientific context. Even when that tool appears to be as straightforward to use and as easy to explain as prior predictive checks.
And maybe we should’ve called that paper The Prior Can Often Only Be Understood in the Context of the Experiment.
Endnotes:
1 The fourth century Christian heresy that posited that Jesus was created by God and hence was not of the same substance. The council of Nicaea ended up writing a creed to stamp that one out.
2 Really never let me choose the movie. Never.
3 I hate the word “robust” here. Robust against what?! The answer appears to be “robust against un-earned certainty”, but I’m not sure. Maybe they want to Winsorize cognitive science?
4 Lauren had to twiddle it a bit, particularly using a non-centered parameterization to eliminate divergences.
Robust against vagaries, of course.
But seriously, thanks for contributing to this special issue! We were bound to overlook things, so it’s very gratifying to see so many excellent people helping to build a compendium of good practices.
Those who advocate choosing the prior in the context of the likelihood, sampling model or experiment really need to think long and hard about whether they are actually using the Bayesian paradigm, or whether in fact they are just integrating over the likelihood, or a weighted version of it, simply because it feels good to do so.
The Bayesian paradigm is more than just an abstract mathematical formula.
Sorry to be a bit harsh. I do not mean to cause offence, but that’s my personal viewpoint.
P.S. Nice to hear you are enjoying a beer (hopefully a real ale) in the best country in the world.
the fundamental question is “how to expression what you know in terms of probability”. One of the most useful and fundamental ways to express knowledge is in terms of the predictive distribution. We very often know more about what kinds of data could be seen than we do about how abstract mathematical quantities interact.
for example “voltage observed at temperature T is an smoothly increasing function of temperature that takes on values between 0 and 1v and the derivative is at most dv/dT = C for values of C somewhere in the range of 1 to 2 volts per 100 degrees C”
what does that mean for the coefficients of a 6 term fourier series? Hard to express that directly, but easy to adjust the priors on the coefficients until the functions that are drawn have the appropriate properties.
Similarly re ‘the idea that priors and likelihoods can[not] be considered separately. Rather, they are consubstantial–built of the same probability substance’
I would be tempted to say a model like
p(y | theta)p(theta ; alpha)
is kinda just a ‘frequentist’/standard probability model of y, theta with unknown parameter alpha. Ie alpha maps to p(y,theta ; alpha). The twist being the Bayesian analysis treats alpha as fixed and known whereas the ‘frequentist’ treats it as unknown and considers each alpha in turn in order to estimate it.
Sometimes the Bayesian analysis does a ‘prior robustness’ study, which seems to amount to mimicking the standard approach of considering unknown parameters (alpha) for each value in turn.
Which is to say, this is the sort of Bayes that seems like a good idea, it just doesn’t really seem like ‘Bayes’ in the sense of Bayesian inference…
Naked:
You write,
Let me generalize this for you.
Sure, why not? I guess we should interrogate all our decisions. Nothing to do with Bayesian statistics in particular, though.
Andrew:
No matter how approximate things get it is definitely desirable to have a good conceptual paradigm underlying what we do. I know very well that you would not disagree with me on this point.
In your analogy (approximate) theory Y is Bayesian but method X is questionably Bayesian. Therefore what paradigm truly underlies method X? I am not saying that one definitely does not exist. The point I was making is that it would appear not to be the Bayesian one.
Dan:
That’s so Australian of you to identify a backyard with “a patch of sand”!
This prior predictive check idea is very nicely exportable into cognitive modeling. Roberts and Pashler 2000 (How persuasive is a good fit?) made a closely related point; I am smitten by their paper a little bit. Many modelers will be shocked if they actually sit down and generate the full range of plausible predictions—essentially the prior predictive distribution—from their models.
+1. One issue with this is that it highlights how sub-optimal all the models populating popular textbooks and papers are in this regard (including my own here too)! All those models with priors aimed at being “vague”, “non-informative”, gamma(epsilon,epsilon) (which appears to be a relic of the conjugate prior for Gibbs sampling era), yadayada…We can do (much) better now – but it comes at the cost of an expanded workflow (all the way, I am assuming, through peer review).
An insightful and important post.
I was recently asked to present something to a local group of data scientists who are meeting together to work through John K. Kruschke’s book and I chose the last session to do something on Bayesian Work Flow (so I’ll be stealing material from other authors on this blog).
Without adequate Bayesian Work Flow, Bayesian analyses are likely to do more harm than good. As I commented a few posts ago, it converts a black box model into an interpretable model.
Now, to try say something potentially helpful.
Bayesian theorem is deductive, so as with all deductive reasoning, the real challenge is to discern as clearly as possible how the conclusions are in fact in the premises. The premises are the joint probability model of the parameters and data and the observed data. It is clear that the posterior is in these (intuitively a slice through the joint distribution of parameters and potential data at the actual data).
But Bayesian analysis is inductive so we need more than clarity in just the deductive step. We need clarity on how empirical reality as been represented in the deductive step and whether or not that is sensible.
So Bayesian Work Flow is just make very clear how this Bayesian analysis represents empirical reality so we can see if it makes sense. Now making sense is much harder than discerning how and by interpretable I just mean clear to see how.
I like this breakdown, the Bayesian math is just formal, the way in which it connects to the world can never be formalized, so we need many informal ways of checking the quality of this connection.
+1 to both Keith and Daniel
Keith – I largely agree. I just think being truly honest about what this perspective means kind of raises a lot of more radical/interesting questions than perhaps some think/hope/etc.
E.g. if we stick to Bayesian principles ‘within’ a model but abandon them when checking the empirical adequacy of a model, why not just go straight to empirical adequacy for everything? What *principles* guide checking empirical adequacy, if not Bayes theorem?
This is important to me as I kind of think the main job of statistics is checking empirical adequacy of theoretical models, which might come from a very different place to where regression-style models come from. I kind of want a theory of statistics that focuses on empirical adequacy, not one that is *conditional* on empirical adequacy.
It’s not that I don’t think thing like a Bayesian workflow that includes checking etc isn’t a good idea, it’s that I think it somewhat ironically amounts to re-discovering that many ‘frequentist’ ideas are not so bad after all! For better or worse, this question of empirical adequacy seems to be what a lot of ‘frequentist’ statistics is about (I’m also often tempted to just throw both Bayes and Freq out and go with data analysis + mechanistic/causal modelling).
Also, what is something like a prior predictive check *really* checking? E.g. if no individual p(y|theta) is adequate but a weighted average int p(y |theta)p(theta ; alpha) dtheta is, does this show up? What does the prior predictive distribution = average of the p(y | theta) actually represent?
Where does my ‘mechanism’ live? In p(y | theta) or the average over these? Is the average of a mechanistic model still a mechanistic model? Or is my model really just p(y; alpha) since I average out theta anyway? In which case I am back to doing what seems a lot like frequentist inference for a model p(y; alpha) of observable data y given parameter alpha: for *each* alpha I check if it could have generated y in some sense (e.g. look at the sampling distribution of T(y) under that alpha).
“Where does my ‘mechanism’ live? in p(y | theta) or the average over these?”
The mechanism for the particular y should live in p(y | theta) but the mechanism for how theta varies from experiment to experiment should live in the p(theta | Background) or whatever.
For example, if I do industrial filtration, and I buy a filter and test it on my process, p(contaminant | filter_coefficient) is a model for how the particular filter I have works.
But what makes brand X a good filter company to work with is that from one order to another filter_coefficient has a small variability.
If I have a time series of filtration results as the filter has been changed over and over, then I should be allowing my filter_cofficient to change with each new installed filter…
However I think often people don’t do this, they mix together lots of stuff and try to do inference on “the average theta”. This is particularly true in stuff like economics, where for example people often talk about “the average effect of policy X on GDP” whereas this isn’t a good way to think about the problem.
Daniel – this sounds like a so-called ‘random effects’ or a ‘repeated measurements’ model with two levels/scales of ‘frequentist’ variability, i.e. each is pretty strongly connected to something *observable*: noisy measurements of contaminant for a fixed filter, and variations in filter properties for a fixed company/manufacturing process.
To me the essence of a Bayesian model is that probability is also used for e.g. *in principle* unobservable things or for things that are actually fixed but for which purely epistemic information about them is represented using probability.
“filtration efficiency of filter x” is in principle unobservable, like “viscosity of fluid y” or “mood of person z”. Only the consequences for how the concentration of contaminants change, fluid flows through a tube, or person answers the question is observable.
I mean, it sounds like from your original description you’re imagining the variability arises from real physical processes that a random effects model can capture.
But regardless, why do I care specifically about E [p(y |theta) ] where the expectation is over the prior? What does the result represent precisely? Do I care if a mixture can capture the ‘true’ process but not individual p(y|theta) can? How would I tell?
In the example filtration problem a given filter canister has an unknown efficiency that is a constant for that canister… but when we decide which filter company we buy from it matters not just the canister they send in the first order, but also the reliability that their future orders will remain high quality. in other words physical variability of the mfg process.
so we have both epistemic uncertainty about the given canister but also epistemic uncertainty caused by mfg variability about the predictive distribution in the future.
as for why you care about E[p(y|theta)] I’m not sure you would care as much as you’d care about E[y | theta] where the expectation is over the posterior for theta, because this is an estimate of tomorrow’s pollution level.
Another way to say this is that the posterior (which is basically your E[p(y|theta)] normalized) is a device for making decisions… it’s the fact that this can be used to make many many different decisions which could depend in many ways on different aspects of the problem that gives it its usefulness.
Again you can obviously model this explicit two level variability – eg within and between canisters, mfg processes etc – fine with any old probability model (eg random effects).
But what I’m getting at is, how do you decide when your (eg two level) model adequately represents the observable real world variability?
Presumably you take a series of models like p1(y,theta), p2(y,theta) etc etc and compare the observable consequences with real or imagined data. Maybe you average out theta, maybe you don’t (eg in your case you might want to examine the random effects part too).
But then, rather than eg put a prior over p1, p2 etc you compute something like a pvalue for each model (well for the usual Bayesian approach you typically just take a single model p1, *maybe* consider some others) to assess empirical adequacy.
Why not just emphasise empirical adequacy of a model of variability in the beginning, middle and end of analysis?
Genuine question I ask myself all the time when using Bayes.
Frequentist models don’t accept probability over the parameter theta… But assuming you accept the idea of probability over Theta and are doing a Bayesian analysis, yes you still have the model selection issue:
p1 vs p2 vs p3 etc.
There are a number of ways you could handle this. These days I think the most useful way to handle it is using Bayesian decision theory. Decide on a utility describing how the model will be used and choose the model that gives the highest average utility. Note that utility and accuracy aren’t necessarily the same thing. For example the “only thing that matters” to you might be say the behavior of the filtration system in the long run average, and you’re willing to put up with occasional spectacular failures… they just cost you the cost of throwing the filter away and replacing it from one off the shelf… Or maybe when the thing fails it’s a major problem, so you accept lower typical efficiency for a design that is extremely reliable…
In the second case, maybe accuracy in your model’s prediction of the typical efficiency is less important, but it should represent the tail of the distribution of outcomes very well… In the first case maybe you really don’t care about the tail but you should predict the typical efficiency very well…
Given a description like this:
> For example, if I do industrial filtration, and I buy a filter and test it on my process, p(contaminant | filter_coefficient) is a model for how the particular filter I have works.
> But what makes brand X a good filter company to work with is that from one order to another filter_coefficient has a small variability.
> If I have a time series of filtration results as the filter has been changed over and over, then I should be allowing my filter_cofficient to change with each new installed filter…
Again: you can definitely motivate a frequentist multilevel/random effects model! E.g. your description is making specific reference to actual real-world variation in the data not just a state of information or belief or whatever. You just have to accept that measuring contaminant given a particular filter has one type of variation, while the variation between filters due to manufacturing has another type of variation.
Yes a slightly different interpretation to a ‘Bayesian’ model but there is nothing in ‘frequentist’ modelling that restricts modelling data variation to a single level, especially a case like this when the different sources of variability in observations are pretty clear.
Re: doing Bayesian decision theory on the p1, p2 etc – this means you *do* need a prior over these. In the case of p(y,theta ; alpha) you need a prior over alpha. So you wouldn’t be doing prior or posterior predictive checks, but more standard Bayes over models indexed by alpha. (Though again you would have a p(alpha | gamma) and fixed gamma etc to contend with).
sure you can model data variation, but you can’t model parameter uncertainty. suppose your model is concentration follows an ODE with dc/dt =f(e,c,t,q)+err(t,c)
e is your unknown efficiency, c is your concentration, t is time and q is additional factors related to system operation. the error has a time and concentration related variability due to measurement instrument.
Suppose you change the filter every month. during a given month, the only Frequentist random component here is the observation or measurement error. you could put a Frequentist random component over the whole series of e values that you will get from future purchases, if such a thing exists (perhaps next month you plan to change the equipment?), but it has nothing to do with your knowledge of the true value of the particular e for this particular time period with this particular filter.
in other words, the Frequentist will admit the random effect over multiple e but not a probability over the particular e for this experiment which is different from the frequency with which the supplier provides filters that have a given e.
suppose you change filters every month, it’s mid month, you want to predict the concentration tomorrow. the Frequentist model says e is what it is, there’s no probability associated. only the measurement errors have frequencies. the Frequentist model will happily admit probability over next months e because unwrapping a new filter is like pulling a handle on a slot machine…
it’s a bit perverse really which is why all models of this form are actually Bayesian in practice and the “Frequentist random effects models” are just Bayes with a flat prior and a MAP estimate.
in a Frequentist setting the fact that a thing varies in time or with new equipment etc means you can put a probability distribution over it with shape equal to the shape you will get for repeated samples of the thing… if you give it a different shape you are objectively wrong according to the theory.
As for a prior over the models. I figure if I could think them up to code them in the first place, I must have some idea that they are worth considering. The next step where I give them some numerical quantity that tells me how much they’re each worth considering doesn’t bother me much, especially because I might often just put 1/N for each if I don’t have much other reason to prefer one to another…. The bigger problem which you’ve pointed out multiple times is when there is some “other unknown unconsidered model”.
I still think working hard on the utility function and then choosing the model that does the best job is a couple orders of magnitude better than the usual alternatives.
For example, suppose whenever the concentration of the pollutant exceeds some level, I have to shut down my machine and do a filter change and flush the existing fluids… and it costs me some amount of money. Suppose that if I can predict that this is going to happen in the next day, that I can schedule this shutdown in a way that doesn’t cost much money. Obviously the performance of my model in the right tail of the concentration distribution is critical here. It could do a terrible job predicting concentrations down below half the cutoff but as long as it does a good job predicting when concentrations will exceed the cutoff ahead of time, I am going to want that model.
p value based analysis of this model might easily reject it as failing to match the observed frequency of concentration, by a LOT in the range of low concentrations, but *in the portion of phase space where it matters* it could still be by far the right model. You just won’t capture that without the utility based analysis.
Whoops I didn’t mean to put the error term in the diffeq, imagine c =f(t)+err(c,t) with f defined by the diffeq… Teach me to do math first thing in the morning on my phone before getting out of bed…🙀
Re: it’s a bit perverse really which is why all models of this form are actually Bayesian in practice and the “Frequentist random effects models” are just Bayes with a flat prior and a MAP estimate.
Sigh :-(
Re: priors over models and decision theory. It’s OK if that’s what you want to do because that’s the Bayesian way or whatever, but back to the general topic of the post (!), it means the role of prior or predictive *checks* is unclear in your approach. You don’t seem to need them (which is OK I guess).
But for those who do want them, what is the rationale? And of course it’s OK to not have one clear philosophy or whatever, it just opens up a lot of other questions, like why not do something else entirely? Eg focus on the underlying rationale – empirical adequacy? – at the beginning, middle and end of analysis?
I mean, I’d be interested to see someone do a Frequentist analysis of a diffeq model not involving maximum likelihood, you know with sampling distributions of the estimator of the nonlinear parameters and no priors and p values and even someone should do some kind of severity analysis… But whatever.
Predictive checks is exactly what I’m talking about with utilities. Write the utility in terms of your accuracy at posterior prediction in terms of frequency of costing you various amounts of money or whatever, and choose your model in that basis.
Maybe I’m not being clear, so I’ll try to explain more carefully:
Approach 1) Use posterior predictive checks calculating p values for data vs prediction, try to make decisions based on some kind of frequency matching of probability of error vs frequency of error…
Approach 2) Use posterior predictive checks to maximize utility of the model in doing its main actual job, which is not to have error e with frequency p(e) but to make you make good decisions… so perhaps Cost(actual,prediction) is a function that only has appreciable quantity when actual is large (lots of pollutants) and prediction is small (model thought things were fine)… and using your data you estimate mean(Cost(actual,prediction)) averaged over the posterior for each model, and choose the model that gives you the best performance…
The model that gives the best performance is the one which correctly predicts the large deviations in pollution, regardless of what happens when actual pollution is small… it could be terribly “calibrated” but always know when something was about to break and leak pollutants everywhere… and you’d pick it.
Actually, I don’t think you really need priors over the models right? you have p1, p2, p3, you fit each one, you specify a utility in terms of something important to you: U(actual, predicted, etc…)
using the posterior for each of p1, p2, p3 you calculate E(U(…)) where the expectation is taken over the example cases / experiments you performed as well as the posterior parameters in each model…. and even the expected future cases you’ll use the model for… then choose the model that produces the least cost or most utility or whatever.
(People *do* do that…)
But back to the decision theory case it sounds like you’re doing eg maxi min expected utility or something over the space of your models. Or even just max likelihood for your hyperparameter…
Why not weight each model by a probability?
ojm, to answer your last question. If you are in the M-closed setting, and are interested in converging on (“learning”) the true model, that can be a good approach. Not so much in M-open. In that case, things like stacking are better. Now, what Daniel is talking about doing is using Bayesian decision theory, or expected utility. Expectations collapse distributions into scalars enabling neat things like ordering. Whether this is wise, is context dependent.
My $0.02
> (People *do* do that…)
A few maybe, I doubt the bit about severity, as that seems to be a newish idea that hasn’t exactly been broadly developed. The vast majority of cases I’ve seen where people fit things like diffeq models have been simple least-squares on the observations, or maybe maximum likelihood on non-normal errors. I don’t count those applications as frequentist as they don’t seem to rely on concepts strongly related to testing the frequency properties of models and they have a very simple Bayesian interpretation. I note that Mayo, a major champion of frequency based modeling routinely dismisses the “likelihood principle” so I don’t think I’m entirely off base in thinking that max-likelihood isn’t quite the same thing. Frequentism isn’t just “Bayes without a prior” but rather a procedure where only objects with long run frequency can have probability and where sampling distributions are the primary object of interest.
Back to the case of decision theory. Suppose you have 3 tools that can be used to fix your ancient tube TV set. Each one has some chance of working based on what might be wrong with your TV. You could have A, B, or C going on with your TV, and each tool has p1(Fixed | A) , p1(Fixed|B) … p3(Fixed|C)
Your utility is U(Fixed)=1, U(Broken)=0. You can calculate the expected utility for each tool… and choose to use the tool that has the highest expected utility under your model for what’s wrong.
You need a prior and/or posterior over what is likely to be wrong, but you don’t need a prior over “which is the *true* tool”.
If you view models as just “tools to make decisions” then the situation is totally symmetric. You have a model for your future usage of filtration (could be a prior, or a fitted posterior), and you have a utility over filtration outcomes in that future usage, you can choose which model to use to make decisions about the filtration maintenance without a prior over “which is the *true* model”.
You might argue how to choose that model of the future usage of filtration? but in general this is something about your own intention “I’ll be running a filter for the next 18 months while we refine corn syrup” or whatever. Could be “I’ll be running experiments on mice to see how they respond to dietary changes every week for the remaining time on my grant” or whatnot. These are not exactly M-open.
It might be hard to see what I’m talking about without some kind of example of how the utility would vary across models.
Sticking with filtration, suppose you have three models of the filtration process.
Model 1) Built on a relatively detailed analysis of how filtration paper degrades and starts to pass particles, so it’s more “true” to the physics, and it has excellent predictive performance for the first 5 days and very good performance out to 10 days, but has a tendency to underestimate the degradation at long service life for lack of a nonlinear process of agglomeration that you don’t have a good model for, so it predicts the filter should stay in service too long.
Model 2) Uses a simple non-physical constant decay and just relies on fitting this decay rate. Doesn’t predict filtration efficiency well at any point in time, but tends to decay fast enough that it predicts you should change your filter well before you really need to, at least it doesn’t leave you high and dry with a full day of downtime when your filter suddenly breaks.
Model 3) Includes a simple version of the nonlinear agglomeration process missing from 1, but because it’s too simplistic, it has nonphysical oscillations throughout the timeframe and does a very poor job of predicting filtration in the early stages due to early onset of decay and oscillations, however it falls off in efficiency rapidly at long service life in exactly the way that the real filter does, and reliably predicts end of life to within 12 hours at least 48 hours ahead of the falloff.
Obviously, if your main concern is to get the end of life behavior correct, you use Model 3 even though it has all kinds of nonphysical oscillations and does a poor job of predicting for the first several days, because what matters to you is that it give you a day or two of heads up right before the filter conks out so you can schedule a replacement during routine down-time.
Model accuracy checking would tell you that of the 3 the first one was “most correct” because for the first N days it does an *excellent* job of predicting the filtration in a regime where you really don’t need an excellent job.
I don’t need a prior over “the probability that model X” is correct to make a decision to use Model 3, I just need knowledge of how I’m using the model, and knowledge of how the model works in terms of posterior predictive Utility.
Re: m-closed, m-open, stacking etc
IMO these are just fancy ways to admit what everybody else was already saying – eg there are many things it doesn’t make sense to put probabilities over and other ideas are needed.
Cool, but now all the usual Bayesian formalism *technically* goes out the window…If you want a fancy way of phrasing one of my questions – why stick with a formalism designed for an M-closed world when faced with an M-open world? Or, how should we interpret M-closed tools in an M-open world? Etc.
Ojm:
It’s turtles all the way down. We use Bayesian inference conditional on a model because it helps us solve lots of problems that involve variation and uncertainty.
ojm, Andrew,
if you want to know the best range parameters to put into your filter model, you run Bayes on the filter data and model… it gives you a posterior distribution, the distribution tells you IF the model were a potentially accurate and self consistent one, which numerical values would make it accurate and self consistent?
the usefulness of a Bayesian model and it’s superiority over point estimates remains even if it doesn’t solve every problem.
In my filter example, I need the Bayesian posterior distribution so I can figure out how well each model does when it’s tuned into a self consistent state. I can do that with maximum likelihood as well, but it’s definitely the case that the Bayesian posterior gives a better indication of the utility than just a maxlike point estimate. the prior can lead you astray, but it can also easily lead you to a better decision. Computers obviously lead to better calculations of weather predictions even if software bugs are also possible.
I’m not a big fan of the m-open vs m-closed concept. inference about *the one true model* is not as important or even feasible as choice of a sufficiently useful model after tuning it. m-open is about being logically open to the vastness of model space… fine but here and now which of the 3 weather forecasts should I use to decide whether to go sailing?
> We use Bayesian inference conditional on a model because it helps us solve lots of problems that involve variation and uncertainty.
That’s fair – so do I, often! I ask these questions as someone who has been using the ‘Gelman-Box-Rubin’ workflow for a while and been telling people to do predictive checks since I learned about them. These questions are as much for me as for anyone else!
But when it comes to these more general questions – like how do we properly check models, define robustness, work in M-open worlds, what does a prior/posterior predictive check actually mean etc – I can’t help but wonder if it’s worth taking a broader view. Eg adapt to the world as it is rather than trying to adapt the world to fixed tools.
Eg I had a few conversations with Laurie Davies about this sort of thing a few years ago. I kept trying to stick with the usual Bayes Bayes Bayes answers to his questions but it eventually just felt like epicycles and rationalisation. Kind of fun to ask what it would look like to throw it all out and start over…
Great post. I really like the last line – “in the context of the experiment.”
This may be a dumb question – let’s say I am using a negative binomial model for count data, where I know that it is physically impossible to exceed a certain count in my data in the real world. So, I can set priors on the shape parameter, intercept, and say a binary treatment effect, where I can run prior predictive checks and predict data that is within the realm of possibility. But let’s say I have a bunch of group level effects, and I put something like half-normal(0,1) on the sd, which seems reasonably conservative on the logit scale if I don’t know much. But now when I run a bunch of prior predictive checks, I get data that is well outside of what is possible, because of all these group level effects. It seems like in this scenario, the more priors you have to sample from, then the smaller they would need to be in order to get data that is still within the realm of possibility… should one leave out group level effects from prior predictive checks?
In the just finished paper that I did read, there is a distinction being made between the likelihood and the experiment which seems unnatural to me. I thought an adequate likelihood would reflect anything that is informative in the experiment. That is “the observations you got to see generating model” part of the joint distribution if adequate – won’t miss anything informative. In fact, it would define whats is informative.