“There’s the part you’ve braced yourself against, and then there’s the other part” – The Mountain Goats
My favourite genre of movie is Nicole Kidman in a questionable wig. (Part of the sub-genre founded by Sarah Paulson, who is the patron saint of obvious wigs.) And last night I was in the same room* as Nicole Kidman to watch a movie where I swear she’s wearing the same wig Dolly did in Steel Magnolias. All of which is to say that Boy Erased is an absolutely brilliant and you should all rush out to see it when it’s released. (There are many good things about it that aren’t Nicole Kidman’s wig.) You will probably cry.
When I eventually got home, I couldn’t stop thinking of one small moment towards the end of the film where one character makes a peace overture to another character that is rejected as being insufficient after all that has happened. And it very quietly breaks the first character’s heart. (Tragically this is followed by the only bit of the movie that felt over-written and over-acted, but you can’t have it all.)
So in the spirit of blowing straight past nuance and into the point that I want to make, here is another post about priors. The point that I want to make here is that saying that there is no prior information is often incorrect. This is especially the case when you’re dealing with things on the log-scale.
Collapsing Stars
Last week, Jonah an I successfully defended our visualization paper against a horde of angry** men*** in Cardiff. As we were preparing our slides, I realized that we’d missed a great opportunity to properly communicate how bad the default priors that we used were.
 This figure (from our paper) plots one realization of fake data generated from our prior against the true data. As you can see, the fake data simulated from the prior model is two orders of magnitude too large.
This figure (from our paper) plots one realization of fake data generated from our prior against the true data. As you can see, the fake data simulated from the prior model is two orders of magnitude too large.
(While plotting against actual data is a convenient way of visualizing just how bad these priors are, we could see the same information using a histogram.)
To understand just how bad these priors are, let’s pull in some physical comparisons. PM2.5 (airborne particulate matter that is less than 2.5 microns in diameter) is measured in micrograms per cubic metre. So let’s work out the density of some real-life things and see where they’d fall on the y-axis of that plot.
(And a quick note for people who are worried about talking the logarithm of a dimensioned quantity: Imagine I’ve divided through by a baseline of 1 microgram per cubic metre. To do this properly, I probably should divide through by a counterfactual, which would be more reasonably around 5 micrograms per cubic metre, but let’s keep this simple.)
Some quick googling gives the following factlets:
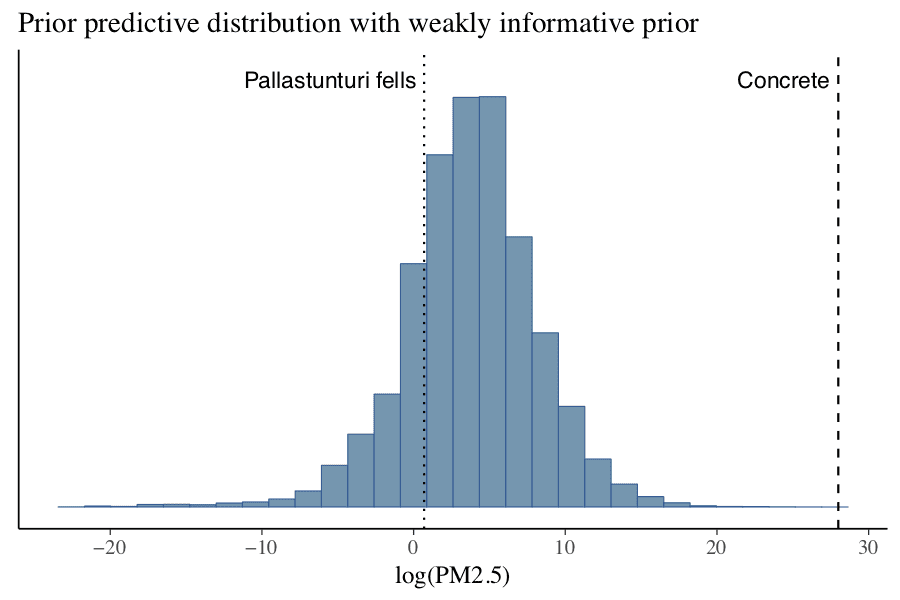
- The log of the density of concrete would be around 28.
- The log the density of a neutron star would be around 60.
Both of these numbers are too small to appear on the y-axis of the above graph. That means that every point in that prior simulation is orders of magnitude denser than the densest thing in the universe.
It makes me wonder why I would want to have any prior mass at all on these types of values. Sometimes, such as in the example in the paper, it doesn’t really matter. The data informs the parameters sufficiently well that the silly priors don’t have much of an effect on the inference.
But this is not always the case. In the real model for air pollution, that our model was the simplest possible version of, it’s possible that some of the parameters will be hard to learn from data. In this case, these un-phyiscal priors will lead to unphysical inference. (In particular, the upper end of the credible interval on the posterior predictive interval will be unreasonable.)
The nice thing here is that we don’t really need to know anything about air pollution to make weakly informative priors that are tailored for this data. All we need to know is that if you breathe try to breathe in concrete, you will die. This means that we just need to set priors that don’t generate values that are bigger than 28. I’ve talked about this idea of containment priors in these pages before, but a concrete example hopefully makes it more understandable. (That pun is unforgivable and I love it!)
Update: The fabulous Aki made some very nice plots that shows a histogram of the log-PM2.5 values for 1000 datasets simulated from the model with these bad, vague priors. Being Finnish, he also included Pallastunturi Fells, which is a place in Finland with extremely clean air. The graph speaks for itself.
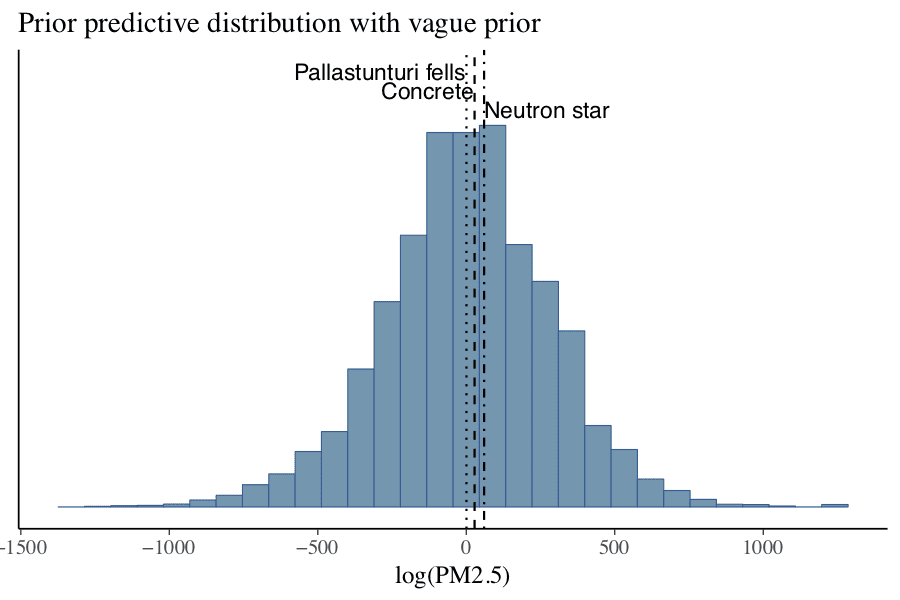
One of the things that we should notice here is that the ambient PM2.5 concentration will never just be zero (it’ll always be >1), so the left tail is also unrealistic.
A similar plot using the weakly informative priors suggested in the paper looks much better.
The Recognition Scene
The nice thing about this example is that it is readily generalizable to a lot of cases where logarithms are used.
In the above case, we modelled log-PM2.5 for two reasons: because it was more normal, but more importantly because we care much more about the difference between $latex 5\mu gm^{-3}$ and $latex 10\mu gm^{-3}$ than we do about the difference between $latex 5\mu gm^{-3}$ and $latex 6\mu gm^{-3}$. (Or, to put it differently, we care more about multiplicative change than additive change.) This is quite common when you’re doing public health modelling.
A different time you see logarithms is when you’re modelling count data. Once again, there are natural limits to how big counts can be.
Firstly, it is always good practice to model relative-risk rather than risk. That is to say that if we observe $latex y_i$ disease cases in a population where we would ordinarily expect to see $latex E_i$ disease cases, then we should model the counts as something like
$latex y_i\sim \text{Poisson}(E_i\lambda)$
rather than
$latex y_i\sim \text{Poisson}(\tilde{\lambda})$.
The reason for doing this is that if the expected number of counts differs strongly between observations, the relative risk $latex \lambda$ can be estimated more stably than the actual risk $latex \tilde{\lambda}$. This is a manifestation of the good statistical practice of making sure that unknown parameters are on the unit scale.
This is relevant for setting priors on model parameters. If we follow usual practice and model $latex \log\lambda\sim N(\mu,\sigma)$, then being on unit scale puts some constraints on how big $latex \sigma$ can be.
But that assumes that our transformation of our counts to unit scale was reasonable. We can do more than that!
Because we do inference using computers, we are limited to numbers that computers can actually store. In particular, we know that if $latex \log\lambda>45$ then the expected number of counts is bigger than any integer that can be represented on an ordinary (64bit) computer.
This strongly suggests that if the covariates used in $latex \mu$ are centred and the intercept is zero (which should be approximately true if the expected counts are correctly calibrated!), then we should avoid priors on $latex \sigma$ with much mass on values larger than 15.
Once again, this is the most extreme priors for a generic Poisson model that don’t put too much weight on completely unreasonable values. Some problem-specific though can usually make these priors even tighter. For instance, we know there are fewer than seven and a half billion people on earth, so anything that is counting people can safely use much tighter priors (in particular we don’t want too much mass on sigma that’s bigger than 7).
All of these numbers are assuming that $latex E_i\approx 1$ and need to be adjusted when the expected counts are very large or very small.
The exact same arguments can be used to put priors on the hyper-parameters in models of count data (such as models that use a negative-binomial likelihood). Similarly, priors for models of positive, continuous data can be set using the sorts of arguments used in the previous section.
Song For an Old Friend
This really is just an extension of the type of thing that Andrew has been saying for years about sensible priors for the logit-mean in multilevel logistic regression models. In that case, you want the priors for the logit-mean to be contained within [-5,5].
The difference between this case and they types of models considered in this post, is that the upper bound requires some more information than just the structure of the likelihood. In the first case, we needed information about the real world (concrete, neutron stars etc), while for count data we needed to know about the limits of computers.
But all of this information is easily accessible. All you have to do is remember that you’re probably not as ignorant as you think you are.
Just to conclude, I want to remind everyone once again that there is one true thing that we must always keep in mind when specifying priors. When you specify a prior, just like when you cut a wig, you need to be careful. That hair isn’t going to grow back.
Deserters
* It was a very large room. I had to zoom all the way in to get a photo of her. It did not come out well.)
** They weren’t.
*** They were. For these sort of sessions, the RSS couldn’t really control who presented the papers (all men) but they could control the chair (a man) and the invited discussants (both men). But I’m sure they asked women and they all said no. </sarcasm> Later, two women contributed very good discussions from the floor, so it wasn’t a complete sausage-fest.
Dan:
This happened to Susanna and me with the Poisson distribution once! We were setting up a prior distribution for a model involving survey weighting—I don’t remember the details, but I think it’s related to what’s in this paper), and we were having some computing difficulties, and then we did some prior predictive simulation and we realized that our prior for the log of the rate parameter was way too vague; we were getting some simulations where the rates were all things like 0.001. The discreteness of the Poisson distribution implies that the scale of the prior can really matter. It’s not like the normal distribution this way.
Also this was a good example of the folk theorem.
I’ve done it too!
I was about to say that we saw this instance of the folk theorem arise for Poisson distributions on the Stan mailing list in the generated quantities block. Simulations would generate counts that were bigger than our 32-bit integers can hold (about 2 billion; we’re going to move to long ints one of these days).
I think this is also a really good way of reminding people that their inferences are a blend of prior information and information in the data, so that if you don’t have much data, you need more prior information to make reasonable inferences. In the extreme case of not having collected any data, you get the prior predictive distribution.
By the time you’re seeing counts into say 10000 or so, it probably makes sense to divide everything by 1000 and treat it as continuous with 3 decimal digits of accuracy. Lots of things we automatically treat as continuous, like the output of a digital voltmeter, are obviously discrete when you think about it, but it really doesn’t matter so long as the discreteness is at a small enough scale relative to the measurement overall value.
Other than (possibly) time, this seems true for just about everything. What is commonly measured that is “truly” continuous?
That’s right, continuous is an approximation to discrete, not the other way around as is often thought.
Daniel Lakeland’s enthusiastic endorsement in 3… 2…
I love that bit about breathing concrete and neutron stars. Let’s take it farther though. You can’t breathe 50% smoke particles by mass. Density of air is 1.2e9 micrograms per cubic meter, and ln of that is about 21.
Next let’s look at the airnow.gov site where they state 500ppm smoke is beyond the range of air quality and into hazardous to life… So we can go a factor of 1000 smaller ln(1.2e6)=14
So now I think we’ve finally got to an uninformative prior, in that we’ve only ruled out the completely impossible.
Also, let’s go for a lower bound. One 2.5 micron cuboid particle of carbon in 1 m^3 of air. Volume (2.5e-6)^3 m^3, density of graphite = 2.3 g/cm^3, I hate converting units by hand because I’m always making mistakes, so I ask gnu units to do it… 3.6e-5 micrograms/m^3
ln(3.6e-5) = -10
so now in Stan we can do something like
real logpm25;
Now if we leave this uniform it’s relatively uninformative, all it does is say “we’re somewhere between the smallest conceivable non-zero value and the highest you can breathe without dying rapidly of smoke inhalation (1000ppm).”
But beyond that, we know it should be typically something like 10ppm to 200ppm with median around say 50ppm because we live in LA and watch the airnow.gov so our kids don’t stay out at summer camp too long in bad air. 200ppm is something like 12 on the log scale, and 20 ppm is 10, so let’s do
normal(11,2)
having done all this we now need to ask if something went wrong, because although it seems that 11 is a reasonable pm2.5 number corresponding to 5.9e4 micrograms/m^3 and density of air is 1.2e9 micrograms/m^3 so that we’re talking 50ppm which is a typical mid-day september reading near Pasadena… the observed levels in Dan’s paper are log(pm2.5) of say 3 or exp(-8)= 3.3e-4 times the mass density typical on a good day where I live.
which suggests a units issue, like using cm^3 instead of m^3 or kg instead of g or something, or maybe he’s taking readings in an industrial clean room?
Of course, wordpress ate the angle brackets, the stan code should look like:
real<lower=-11,upper=15> logpm25;
Daniel:
I think hard constraints are generally a mistake. Instead of bounding a parameter between A and B, better to give it a normal prior with mean (A+B)/2 and sd (A-B)/2. I say this both for computational reasons and modeling reasons.
Two advantages of the normal rather than uniform prior:
1. Partial pooling toward the center of the range.
2. No pathological behavior at the ends of the range.
Sure, but my suggested prior is normal(11, 2) with bounds at -11 and 15. The main reason for the bounds here is to prevent problems with getting really wacky initial values. Remember we’re probably exponentiating this value since we’re working on the log scale!
All that being said, the *real* concern here is that my back of the envelope calculation suggesting that 10 to 12 is a reasonable quantity completely fails to cover the range of the actual data which is 1-5 !!!
I think the problem is that I was using parts per million as what I understood the airnow values to be, but in fact they are of course micrograms/m^3 for pm2.5 (they are parts per billion for ozone for example so it’s always *really important* to check the units of measurement), so my calculations are off because I was multiplying by density of air to get micrograms/m^3
Always check the sensibility of your basic math first. Issues like whether or not you’re putting a hard boundary out pretty deep in the tail of your distribution come second ;-)
So, correcting my math: log(1000) giving the high end of pollution = 6.9 and -10 as the lower bound, with 50 ug/m^3 being a typical value during the day in Pasadena so log(50)=3.9 we can set our prior as something like
real<lower=-10,upper=8> logpm25;
logpm25 ~ normal(4,2);
and now going back to the graph we’ll find that all the data is in fact somewhere between 1 and 5, and the tail at either -10 or 8 does not enter into the calculation so whether it’s got a hard bound or not won’t really matter (I only do it as I say because if it gets initialized to 15 or something things could go very wrong and take a long time to get initialized)
Daniel, I like your additional considerations on feasible range. Two other comments
1) In the paper, the prior is not directly on log(PM2.5) but on model parameters. It is more difficult to set prior on several parameters so that it would be constrained in some range for the outcome.
2) You justified constrained range by avoiding “wacky” initial values. With your constraint, due to transformation, the initial values by default in Stan would be from range [-7.85, 5.85]. Without constraint the default initial values are from range [-2, 2].
Aki, thanks for additional comments. It’s not just that initial range is the issue, but also I’ve found that when you start well out of equilibrium, sometimes you wind up with tremendous overshoot in certain variables. Perhaps potential energy coming from one variable gets transferred into another during the equilibriation process. If the second variable is constrained to *never* go into bananas territory it may help. It may not. But particularly with a variable you’re planning to exp(x) keeping x from ever being 1000 seems like a good idea ;-) obviously mileage may vary. I would rarely put a hard constraint on a variable (except if logically it can’t be outside the range), this kind of case where I’m transforming the variable and it can result in truly ridiculous quantities on the other end of the transform is probably the only time I usually put hard constraints.
I did know that in the real paper the prior is not directly on log(PM2.5) but felt that it would be helpful for people to see the kind of modeling that can go into choice of priors, so I abstracted that away for the comments here.
However, when it comes to setting priors on parameters that indirectly affect another measurement, I do think we can do well by using a “pseudo-likelihood” function. That is, imagine you have a,b,c with some kind of simple order of magnitude priors:
a ~ normal(10,5);
b ~ normal(10,5);
c ~ normal(10,5);
But through some function you have a fourth quantity that is physically meaningful about which you have prior information.
d = f(a,b,c)
In the Stan language there’s nothing that prevents you from calculating d in the transformed parameters block, and then in the model block doing:
d ~ gamma(5,4.0/10);
or whatever is meaningful for the physical information. The idea is, you know that d needs to be something in the vicinity of 10 so you reweight your prior on a,b,c by a function that downweights the regions of a,b,c space when they result in d being well outside the range you expect. The prior is now implicitly a multidimensional correlated one, but if your information is primarily in d space, this prior should be much more effective than the generic ones on the individual coefficients.
Some times is not obvious how to make the obvious – well obvious.
Plots often are good at making the implications of poor priors obvious, but my guess almost anyone who has done Bayesian analyses in real applications has been blinded sided by this issue. Wonder what percent of the time it was noticed (within and over analysts)? On the other hand, there did seem to be a reluctance to simulate and plot priors, which has hopefully past.
Unlike your claim of it being hazardous to breath concrete, I can point to some empirical evidence here – Hidden Dangers of Specifying Noninformative Priors. John W. Seaman III, John W. Seaman Jr. & James D. Stamey The American StatisticianVolume 66, Issue 2, May 2012, pages 77-84. http://amstat.tandfonline.com/doi/full/10.1080/00031305.2012.695938
Now why did this only? arise in “amstat” journal rather than a more prominent technically oriented stats journal and only in 2012?
(To date about 40 citations, so not totally being ignored.)
I had not seen that paper! I like it.
As to why it’s not in a prominent technical journal, I know the answer to that: prominent technical journals have no interest in publishing this sort of work, so you put it where you can.
Yup – as I found out when I tried to publish this in 2011 (which had similar but much briefer arguments) http://statmodeling.stat.columbia.edu/wp-content/uploads/2011/05/plot13.pdf
> I had not seen that paper!
So you missed Xi’ans and my comment it in 2013
https://xianblog.wordpress.com/2013/11/21/hidden-dangers-of-noninformative-priors/
Oh my. X did rather miss the point, didn’t he.
Dan, I do miss a lot of points and even entire lines! So what is this particular point that I missed? Kaniav and I tried to publish a rebuttal to this paper in TAS, but between some maladresses in the early version and some difficulties in communicating with the TAS editors, and again another maladresse in selecting the next journal it could be submitted to, the paper ended up in a predatory OMICS journal. I was going to suggest that our experiment in the first example with the unlikely distributions of death was akin to your elimination of vague priors in the paper. But since I missed “the” point, this is presumably not the case.
Just a bit of feedback—the plots could be labeled much better. I’m not a statistician, just an interested layperson with a math/physics background, but I found it very difficult to follow what was being plotted based on the plot labels. Even in the full paper the plots could have used more descriptive labels. Labels like “log(satellite)” and “Simulated data” tell you the source of the measurement/estimates, but not what they’re estimates of. “Log (PM_2.5)” on the other hand tells you what is being measured, but not the source. So it’s a confusing mix of conventions, and at first glance it’s not at all obvious that both axes are plotting the same quantity.
Wouldn’t it be better to label both axes with “Log (PM_2.5)”, followed by “[ground measurement]” / “[satellite data estimate]” / “[simulated satellite data estimate]”?
I ripped this plot out of context, but yeah, it should definitely be labelled better. Ironic given it was a paper about visualization :p
Question: How are the prior predictive data generated on the red scatterplot paired with actual data if no data is used to generate them? In what sense does each data point “belong together?” Thanks.
The prior predictive data y_tilde, log(PM2.5), generated conditional on x, log satellite measurement in each ground station. x_obs is common for prior predicted y_tilde and observed y_obs.
I came to the party late. What does this have to do with Arianism?