“Otto eye-balled the diva lying comatose amongst the reeds, and he suddenly felt the fire of inspiration flood his soul. He ran back to his workshop where he futzed and futzed and futzed.” –Bette Midler
Andrew was annoyed. Well, annoyed is probably too strong a word. Maybe a better way to start is with The List. When Andrew, Aki, and I work together we have The List of projects that need to be done and not every item on this list weighted the same by all of us.
The List has longer term ideas that we’ve been slouching towards, projects that have stalled, small ideas that have room to blossom, and then there’s my least favourite part. My least favourite part of The List is things that are finished but haven’t been written up as papers yet. This is my least favourite category because I never think coercing something into a paper is going to be any fun.
Regular readers of my blogs probably realize that I am frequently and persistently wrong.
But anyway. It was day one of one of Aki and my visits to Columbia and we were going through The List. Andrew was pointing out a project that had been sitting on The List for a very very long time. (Possibly since before I was party to The List.) And he wanted it off The List.
(Side note: this is the way all of our projects happen. Someone suddenly wants it done enough that it happens. Otherwise it stays marinating on The List.)
So let’s start again.
Andrew wanted a half-finished paper off The List and he had for a while. Specifically, the half-finished paper documenting the actual way that the Stan project computes $latex \widehat{R}$ (aka the Potential Scale Reduction Factor or, against our preference of not naming things after people, the Gelman-Rubin(-Brooks) statistic). So we agreed to finish it and then moved on to some more exciting stuff.
But then something bad happened: Aki broke R-hat and we had to work out how to fix it.
The preprint is here. There is an extensive online appendix here. The paper is basically our up to date “best practice” guide to monitoring convergence for general MCMC algorithms. When combined with the work in our recent visualization paper, and two of Michael Betancourt’s case studies (one and two), you get our best practice recommendations for Stan. All the methods in this paper are available in a github repo and will be available in future versions of the various Stan and Stan-adjacent libraries.
What is R-hat?
R-hat, or the potential scale reduction factor, is a diagnostic that attempts to measure whether or not an MCMC algorithm1 has converged flag situations where the MCMC algorithm has failed converge. The basic idea is that you want to check a couple of things:
- Is the distribution of the first part of a chain (after warm up) the same as the distribution of the second half of the chain?
- If I start the algorithm at two different places and let the chain warm up, do both chains have the same distribution?
If one of these two checks fail to hold, then your MCMC algorithm has probably not converged. If both checks pass, it is still possible that the chain has problems.
Historically, there was a whole lot of chat about whether or not you need to run multiple chains to compute R-hat. To summarize that extremely long conversation: you do. Why? To paraphrase the great statistician Vanessa Williams:
Sometimes the snow comes down in June
Sometimes the sun goes ’round the moon
Sometimes the posterior is multimodal
Sometimes the adaptation you do during warm up is unstable
Also it’s 2019 and all of our processors are multithreaded so just do it.
The procedure, which is summarized in the paper (and was introduced in BDA3), computes a single number summary and we typically say our Markov Chains have not converged if $latex \widehat{R} > 1.01$.
A few things before we tear the whole thing down.
- Converging to the stationary distribution is the minimum condition required for a MCMC algorithm to be useful. R-hat being small doesn’t mean the chain is mixing well, so you need to check the effective sample size!
- R-hat is a diagnostic and not a proof of convergence. You still need to look at all of the other things (like divergences and BFMI in Stan) as well as diagnostic plots (more of which are in the paper)
- The formula for R-hat in BDA3 assumes that the stationary distribution has finite variance. This is a very hard property to check from a finite sample.
The third point is how Aki broke R-hat.
R-hat is a diagnostic not a hypothesis test
A quick (added after posting) digression here about how you should treat R-hat. Fundamentally, it is not a formal check to see if an MCMC algorithm has reached its stationary distribution. And it is definitely not a hypothesis test!
A better way of thinking about R-hat is like the fuel light in a car: if the fuel light is on, get some petrol. If the fuel light isn’t on, look at the fuel gauge, how far you’re gone since your last refill, etc.
Similarly, if R-hat is bigger than 1.01, your algorithm probably isn’t working. If R-hat is less than this fairly arbitrary threshold, you should look at the effective sample size (the fuel gauge), divergences, appropriate plots, and everything else to see if there are any other indicators that the chain is misbehaving. If there aren’t, then you’ve done your best to check for convergence problems, so you might as well hold your breath and hope for the best.
But what about the 1.01 threshold? Canny readers will look at the author list and correctly assume that it’s not a high quantile of the distribution of R-hat under some null hypothesis. It’s actually just a number that’s bigger than one but not much bigger than one. Some earlier work suggested bigger thresholds like 1.1, but Vats and Knudson give an excellent argument about why that number is definitely too big. They suggest making a problem-dependent threshold for R-hat to take into account it’s link with effective sample size, but we prefer just to look at the two numbers separately, treating R-hat as a diagnostic (like the fuel light) and the effective sample size estimate like the fuel gauge.
So to paraphrase Flight of The Concords: A small R-hat value is not a contract, but it’s very nice.
When does R-hat break?
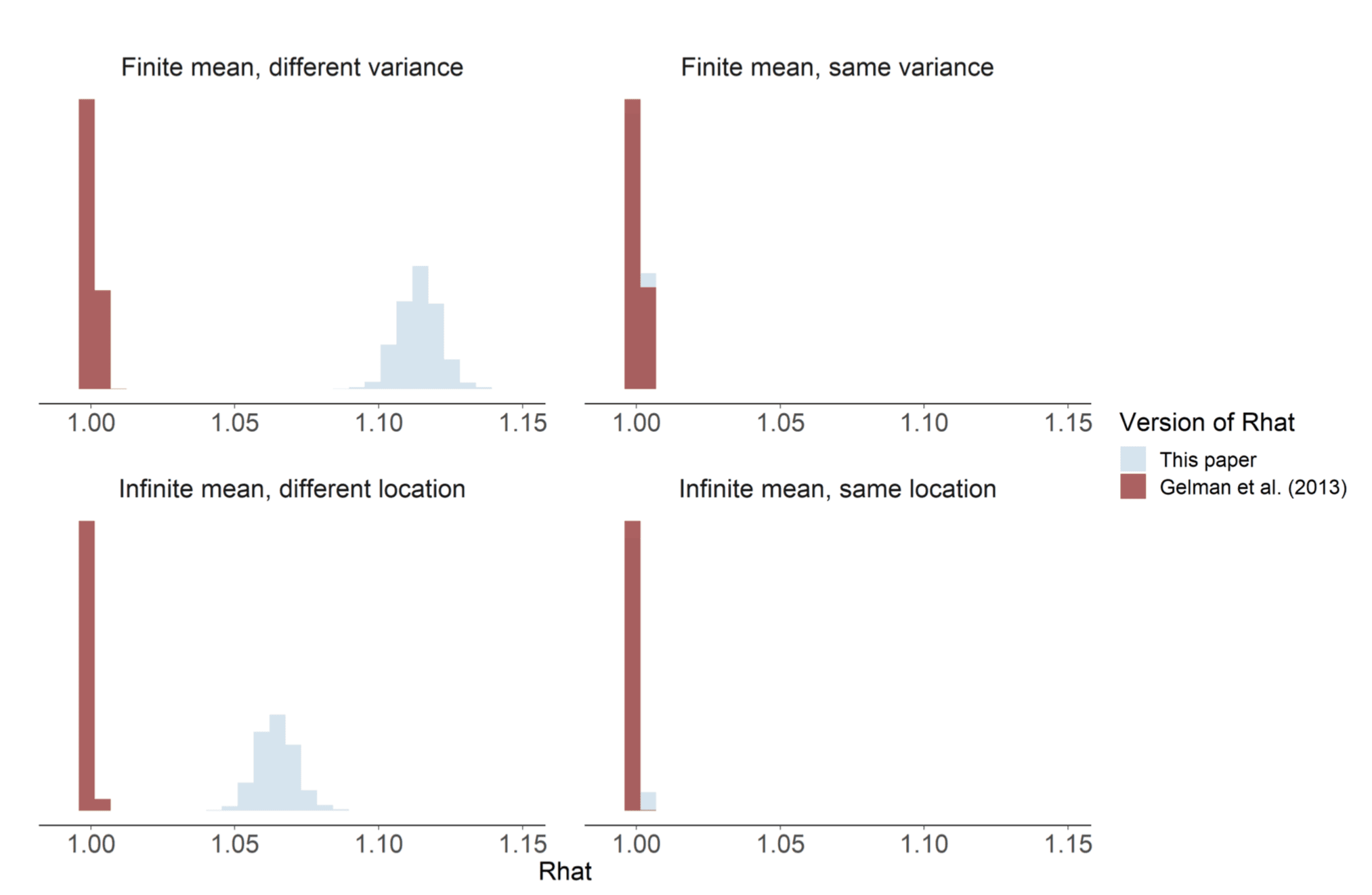
The thing about turning something into a paper is that you need to have a better results section than you typically need for other purposes. So Aki went off and did some quick simulations and something bad happened. When he simulated from four chains where one had the wrong variance, the R-hat value was still near one. So R-hat was not noticing the variance was wrong. (This is the top row of the above figure. The left column has one bad chain, the right column four correct chains.)
On the other hand, R-hat was totally ok noticing when the location parameter of one chain had the wrong location parameter. Except for the bottom row of the figure, where the target distribution is Cauchy.
So we noticed two things:
- The existing R-hat diagnostic was only sensitive to errors in the first moment.
- The existing R-hat diagnostic failed catastrophically when the variance was infinite.
(Why “catastrophically”? Because it always says the chain is good!)
So clearly we could no longer just add two nice examples to the text that was written and then send the paper off. So we ran back to our workshop where we futzed and futzed and futzed.
He tried some string and paper clips…
Well, we2 came up with some truly terrible ideas but eventually circled around to two observations:
- Folding the draws by computing $latex \zeta^{(mn)}=\left|\theta^{(nm)}-\mathrm{median}(\theta)\right|$ and computing R-hat on the folded chain will give a statistic that is sensitive to changes in scale.
- Rank-based methods are robust against fat tails. So perhaps we could rank-normalize the chain (ie compute the rank for each draw inside the total pool of samples and replace the true value with the quantile of a standard normal that corresponds to the rank).
Putting these two together, we get our new R-hat value: after rank-normalizing the chains, compute the standard R-hat and the folded R-hat and report the maximum of the two values. These are the blue histograms in the picture.
There are two advantages of doing this:
- The new value of R-hat is robust against heavy tails and is sensitive to changes in scale between the chains.
- The new value of R-hat is parameterization invariant, which is to say that the R-hat value for $latex \theta$ and $latex \log(\theta)$ will be the same. This was not a property of the original formulation.
What does the rank-normalization actually do?
Great question imaginary bold-face font person! The intuitive answer is that it is computing the R-hat value for the nicest transformation of the parameter. (Where nicest is problematically defined to be “most normal”). So what does this R-hat tell you? It tells you that if the MCMC algorithm has failed to converge after we strip away all of the problems with heavy tails and skewness and all that jazz. Similarly we can compute an Effective Sample Size (ESS) for this nice scenario. This is the best case scenario R-hat and ESS. If it isn’t good, we have no hope.
Assuming the rank-normalized and folded R-hat is good and the rank-normalized ESS is good, it is worth investigating the chain further.
R-hat does not give us all the information we need to assess if the chain is useful
The old version of R-hat basically told us if the mean was ok. The new version tells us if the median and the MAD are ok. But that’s not the only thing we usually report. Typically a posterior is summarized by a measure of centrality (like the median) and a quantile-based uncertainty interval (such as the 0.025 and 0.975 quantiles of the posterior). We need to check that these quantiles are computed correctly!
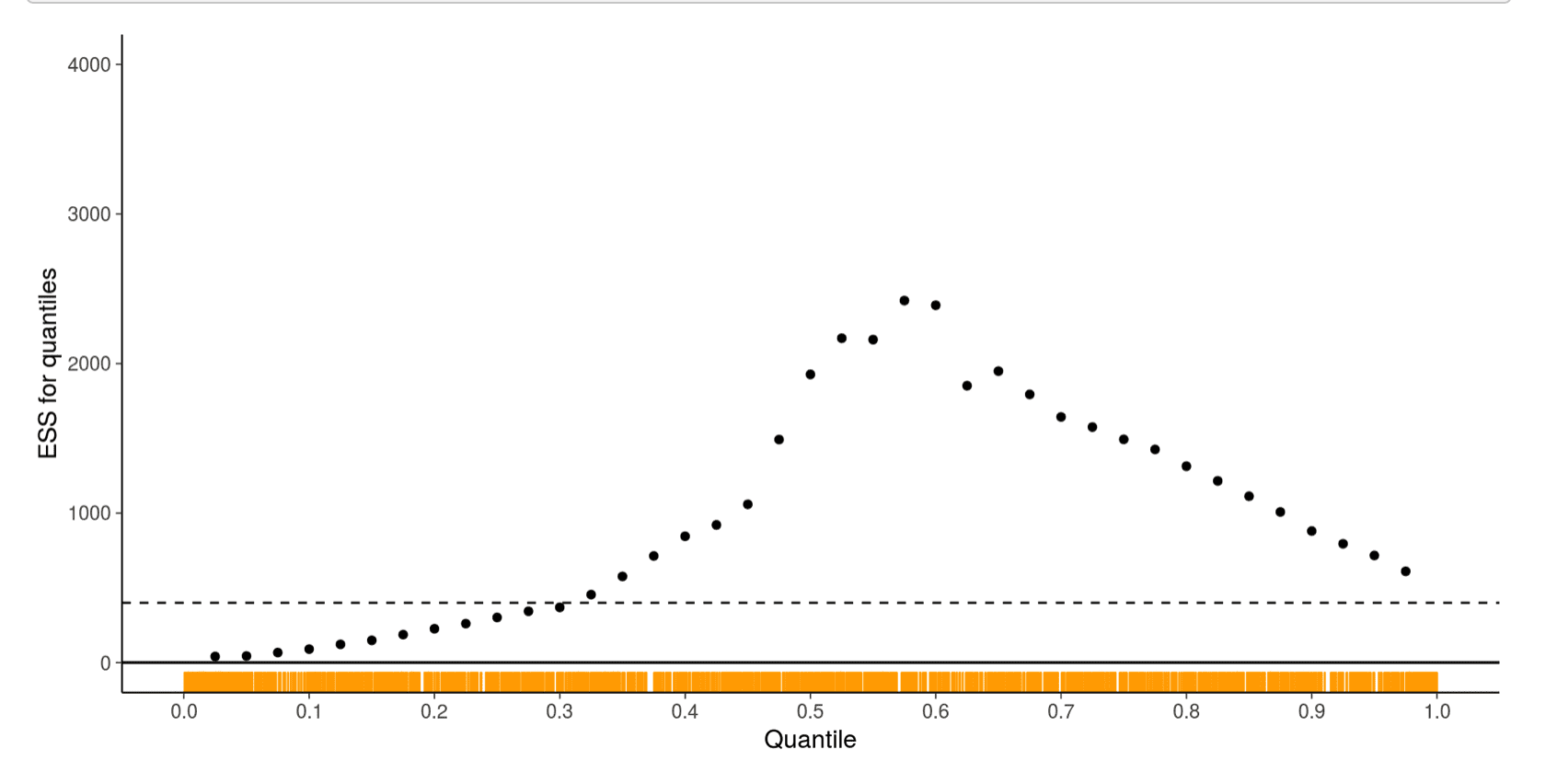
This is not trivial: MCMC algorithms do not explore the tails as well as the bulk. This means that the Monte Carlo error in the quantiles may potentially be much higher than the Monte Carlo error in the mean. To deal with this, we introduced a localized measure of quantile efficiency, which is basically an effective sample size for computing a quantile. Here’s an example from the online appendix, where the problem is sampling from a Cauchy distribution using the “nominal” parameterization. You can see that it’s possible that central quantiles are being resolved well, but extreme quantile estimates will be very noisy.
Maybe it’s time to let traceplots die
As we are on somewhat of a visualization kick around these parts, let’s talk about traceplots of MCMC algorithms. They’re terrible. If the chain is long, all the interesting information is compressed, and if you try to include information from multiple chains it just becomes a mess. So let us propose an alternative: rank plots.
The idea is that if the chains are all mixing well exploring the same distribution, the ranks should be uniformly distributed. In the following figure, 4 chains of 1000 draws are plotted and you can easily see that the histograms are not uniform. Moreover, the histogram for the first chain clearly never visits the left tail of the distribution, which is indicative of a funnel. This would be harder to see with 4 traceplots plotted over each other.

How to use these new tools in practice
To close off, here are our recommendations (taken directly from the paper) for using R-hat. All of the methods in this paper will make their way into future version of RStan, rstanarm, and bayesplot (as well as all the other places we put things).
In this section [of the paper] we lay out practical recommendations for using the tools developed in this paper. In the interest of specificity, we have provided numerical targets for both R-hat and effective sample size (ESS). However, these values should be adapted as necessary for the given application.
In Section 4, we propose modifications to R-hat based on rank-normalizing and folding the posterior draws. We recommend running at least four chains by default and only using the sample if R-hat < 1.01. This is a much tighter threshold than the one recommended by Gelman and Rubin (1992), reflecting lessons learnt over more than 25 years of use.
Roughly speaking, the ESS of a quantity of interest captures how many independent draws contain the same amount of information as the dependent sample obtained by the MCMC algorithm. Clearly, the higher the ESS the better. When there might be difficulties with mixing, it is important to use between-chain information in computing the ESS. For instance, in the sorts of funnel-shaped distributions that arise with hierarchical models, differences in step size adaptation can lead to chains to have different behavior in the neighborhood of the narrow part of the funnel. For multimodal distributions with well-separated modes, the split-R-hat adjustment leads to an ESS estimate that is close to the number of distinct modes that are found. In this situation, ESS can be drastically overestimated if computed from a single chain.
As Vats and Knudson (2018) note, a small value of R-hat is not enough to ensure that an MCMC procedure is useful in practice. It also needs to have a sufficiently large effective sample size. As with R-hat, we recommend computing the ESS on the rank-normalized sample. This does not directly compute the ESS relevant for computing the mean of the parameter, but instead computes a quantity that is well defined even if the chains do not have finite mean or variance. Specifically, it computes the ESS of a sample from a normalized version of the quantity of interest, using the rank transformation followed by the normal inverse-cdf. This is still indicative of the effective sample size for computing an average, and if it is low the computed expectations are unlikely to be good approximations to the actual target expectations. We recommend requiring that the rank-normalized ESS is greater than 400. When running four chains, this corresponds to having a rank-normalized effective sample size of at least 50 per split chain.
Only when the rank-normalized and folded R-hat values are less than the prescribed threshold and the rank- normalized ESS is greater than 400 do we recommend computing the actual (not rank-normalized) effective sample size for the quantity of interest. This can then be used to assess the Monte Carlo standard error (MCSE) for the quantity of interest.
Finally, if you plan to report quantile estimates or posterior intervals, we strongly suggest assessing the behaviour of the chains for these quantiles. In Section 4.3 we show that convergence of Markov chains is not uniform across the parameter space and propose diagnostics and effective sample sizes specifically for extreme quantiles. This is different from the standard ESS estimate (which we refer to as the “bulk-ESS”), which mainly assesses how well the centre of the distribution is resolved. Instead, these “tail-ESS” measures allow the user to estimate the MCSE for interval estimates.
Footnotes:
1 R-hat can be used more generally for any iterative simulation algorithm that targets a stationary distribution, but it’s main use case is MCMC.
2 I. (Other people’s ideas were good. Mine were not.)
Dan:
Thanks for the post. Just a couple of comments.
1. You write, “whether or not an MCMC algorithm has converged.” I prefer to pedantically say “the extent to which different MCMC chains have mixed.” Or, perhaps, “evidence for poor mixing of MCMC chains.” Or “empirical evidence for poor MCMC convergence.” I don’t like “whether or not” as if convergence is a yes/no state. I thought a lot about this back in 1990 when I first came up with R-hat, and I realized I didn’t want to set it up as a hypothesis test. Hence the term “potential scale reduction factor” which is intended to be descriptive. Not, for example, “convergence test.”
2. Aki and I and others had actually been talking about a rank-based R-hat for a long time, well before those simulation experiments you discuss in your above post. We went back and forth about whether it made sense to switch to the more robust rank-based approach, or whether it was more trouble than it was worth to have to explain the additional step in complexity, given that in real life we didn’t have so many Cauchy-distributed variables. Even while writing this paper we went back and forth. Perhaps it was the mass of simulation examples, or perhaps it was just that we were adding enough other steps to the procedure anyway, that we decided to just make that new recommendation.
1. I definitely agree. The way I think about it is that if R-hat is small then I need to still check everything else out. But if it’s big then there’s a problem. So it’s not a test so much as a quantity that I want to be close to 1 because of what that quantity means. Testing doesn’t make sense because I don’t care if it’s large by bad luck: I don’t want it to be large at all!
2. I’ll take your word for it. I suspect we tipped over to ranks because we’d just finished SBC and Aki and I were very rank-happy. We were also doing k-hat and realizing that it’s realy hard to tell if something has finite variance. And I like being able to transform things without Jacobians! But I think it makes a good recommendation because it get rid of some side conditions that have to be true without the transformation. It also has the side effect of taking it further from a test given that it’s now a statement about a transformed parameter and not the parameter itself (although that may just make sense for me)
I did some re-wording and added a little section for point 1.
Really cool and informative post.
> we strongly suggest assessing the behaviour of the chains for these quantiles
Wonder what percentage of published credible intervals are importantly wrong.
(Of course this will vary by the reference class of posterior simulation difficulty.)
Well most of them are wrong in the sense that they have unacknowledged Monte Carlo error. The situation where this really really matters are the times when people make hard judgement based on intervals covering zero (in which case some error in the interval is not the problem!)
Dan:
I like what you write about R-hat being close to 1 as being necessary but not sufficient for convergence. This was a point we made in our original 1992 paper, and in that sense it’s related to lots of hypothesis tests in that you can’t learn more than what information is used in the method. One of the cool things about these new HMC diagnostics such as divergences (see see this article from Mike Betancourt) is that they use additional information. Steve Brooks and I wrote a couple papers on using additional information to help diagnose MCMC problems, but our methods weren’t quite sophisticated enough to be useful—also we didn’t have Stan, so there was less of a sandbox to beta-test new diagnostics.
One reason I think R-hat has been so successful (appropriately so, I’d argue, despite is flaws, as it does catch lots and lots of problems with mixing) is that in some way it is a formalization and improvement on what people would otherwise be doing. By far the most important piece of practical advice is to run multiple chains. Once you have multiple chains, just about any method of looking will reveal gross failures of mixing. From that standpoint, R-hat is a quick way to look at lots of parameters and quantities of interest. You can look at R-hat for 1000 parameters and it’s not so easy to look at 1000 trace plots.
The next step was to compare variance between chains to variance within chains: this was a breakthrough because it allowed R-hat to be automatic. There’s a whole tradition of trying to empirically estimate the convergence of deterministic algorithms by looking at the steps getting smaller and smaller and comparing to some threshold—but this requires some externally determined threshold. Comparing between to within was just beautiful because it required no tuning parameters (except, as you note in your post above, the practical threshold of 1.1 or 1.01 or whatever, but that doesn’t bother me as much, as it can be interpreted as a potential reduction in uncertainty interval widths, without requiring so much problem-specific context). In that sense, R-hat is to convergence monitoring as the Nuts algorithm is to HMC, in that it contains a theoretical or conceptual element that has a big practical impact.
Finally, I think one of R-hat’s key advantages is the negative virtue that it’s not a hypothesis test: it is what it is and does not purport to be more. Our first published paper in this area was called, “A single series from the Gibbs sampler provides a false sense of security.” Not only do we want to avoid a false sense of security in our inferences from simulations, we also want to avoid a false sense of security in the statements we make about our simulations.
I want people to feel as insecure about their statistical computing as possible :p
Dan:
Sure, but remember what G. K. Chesterton said: Skepticism, when taken to an extreme, is a form of credulity. Way back in the bad old days, people thought it was impossible to monitor the convergence of iterative simulations, so they’d just one run chain for awhile, look at the trace plot, convince themselves it was OK, and stop. This probably wasn’t the worst thing in the world—actually, I’d guess that back then people lost out more by running their chains for too long, and thus fitting too few models, not doing enough data exploration, and performing weak data analysis because they were using crude models that they’d not sufficiently adapted and understood, than by not running long enough and misjudging their posterior distributions. Just as it’s said that a solid economic safety net gives businesspeople the freedom to innovate, I’d say that reliable convergence monitoring gives data analysts the freedom to try lots of models.
I think that paradoxically, this is what attracts people to and pushes them away from the sort of generative probabilistic modeling that we (the Stan community) does.
On the one hand, the strength of these methods is that you’ll know when you’re doing something wrong. If you’re doing something wrong, you’ll probably see either divergences, bad rhats, low ESS, or just plain old bad posterior predictive plots. This is great because it’s important to know when you’re wrong if you care about getting to the right answer i.e. knowledge is power.
On the other hand, when I’ve tried to get younger students into generative probabilistic modeling and Stan they’re always intimidated by all the different diagnostics and things to check. I’m curious about how Andrew handles this in his introductory courses to social scientists. In many mainstream machine learning analyses for example, really the only diagnostic people use is K-fold cross-validation of mean-square-error. This is far simpler than everything you need to check in a generative probabilistic model, but in my opinion, this can give people a false sense of security. I’m probably preaching to the choir here though.
PS: Awesome work, Dan and everyone! I like the quote too. I once saw Bette Midler at a sushi restaurant in Pasadena, but I was too scared to say hi because I didn’t want to disturb her.
Arya:
I just tell students that if R-hat is less than 1.1 for all quantities of interest, they’re ok. And then I tell them that, whether or not they have convergence, they’re not ok until they’ve checked their computing using fake-data simulation and checked their model fit by comparing data to posterior predictive simulations.
The point is, MCMC convergence is only part of the game. No point losing sleep over whether your simulations really converged, as you should check them in more important ways anyhow. The purpose of Rhat etc is not to catch everything bad that can happen, it’s to catch a lot that can go wrong, which will save you time later as you won’t have to use more laborious methods to find out that your computation isn’t doing what it’s supposed to be doing or that your model isn’t fitting the data.
I think it’s a lot easier to use these methods when you realize that (a) the world’s not gonna end if you accidentally use a fit when there is undiagnosed poor convergence, (b) you’re gonna have to check your model fit anyway.
We had a long debate at one point about whether to silence all our warnings by default. I’m not going to name names for fear of having my blog privileges revoked, but let’s just say the side of light and goodness won that battle.
K-fold cross-validation of mean-square error only works for point predictions. I usually see cross-validation over 0/1 loss for classifiers, or even worse in NLP, continued re-use of a single train/validate/test split of the data.
If calibration of probabilistic predictions were the metric (i.e., we expect binomial(N, theta) events predicted with probability theta to occur), rather than 0/1 loss or MSE, we’d see a very different game being played.
“Regular readers of my blogs”
Do you just mean your blog entries here, or do you blog elsewhere too? If so, where?
I’m far from an expert, but should the second row in Figure 2 be labeled “Infinite variance” and not “Infinite mean”? If the mean is infinite, then its location can’t be shifted in the first column. [When I went to the paper to try and update my understanding, there was also a small typo in the figure legend: “…we set one of the four chains to have a variance lower than the others.that was too low.”]