Carl Bialik and Andrew Flowers at fivethirtyeight.com (Nate Silver’s site) ran a story following up on our birthdays example—that time series decomposition of births by day, which is on the cover of the third edition of Bayesian Data Analysis using data from 1968-1988, and which then Aki redid using a new dataset from 2000-2014.
Friday the 13th: The Final Chapter
Bialik and Flowers start with Friday the 13th. For each “13th” (Monday the 13th, Tuesday the 13th, etc.), they took the average number of babies born on this day over the years in the dataset, minus the average number of babies born one week before and one week after (that is, comparing to the 6th and 20th of the same month). Here’s what they found:
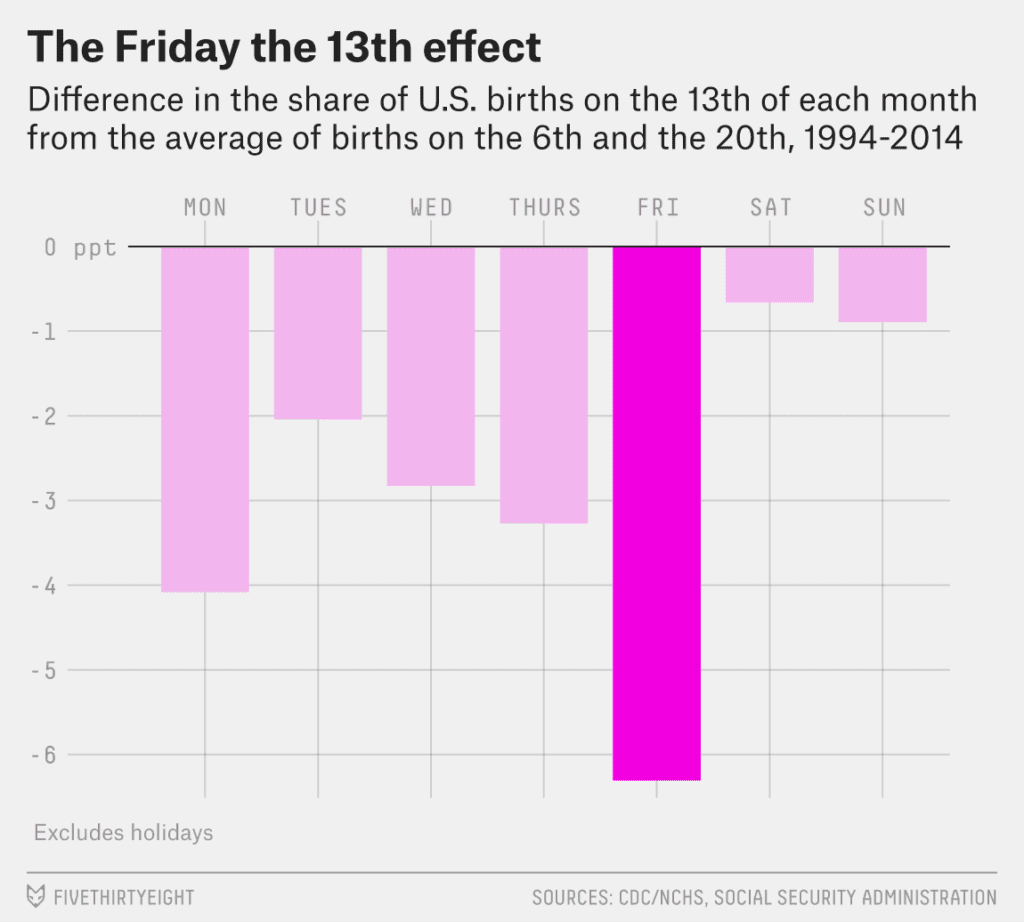
The drop on the 13th is biggest on Fridays, of course. It’s smaller on the weekends, which makes sense. Weekend births are already suppressed by selection so there is not much room for there to be more selection because of being on the 13th.
All 366 days
Here’s the fivethirtyeight’s art department’s redrawing of a graph Aki made for the 2000-2014 data:
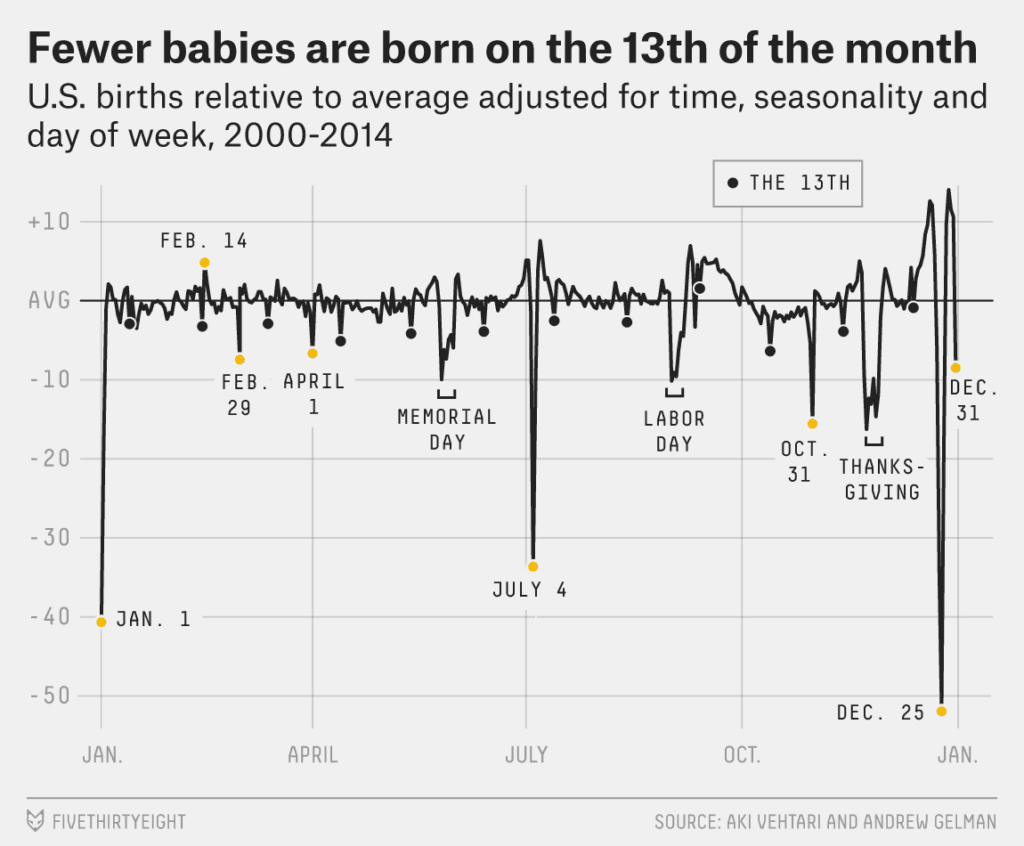
You can see dips on the 13th of each month, also a slight bump on Valentine’s, and drops on several other special days, including February 29th, Halloween, and September 11th, along with a bunch of major holidays.
Here’s the full decomposition:
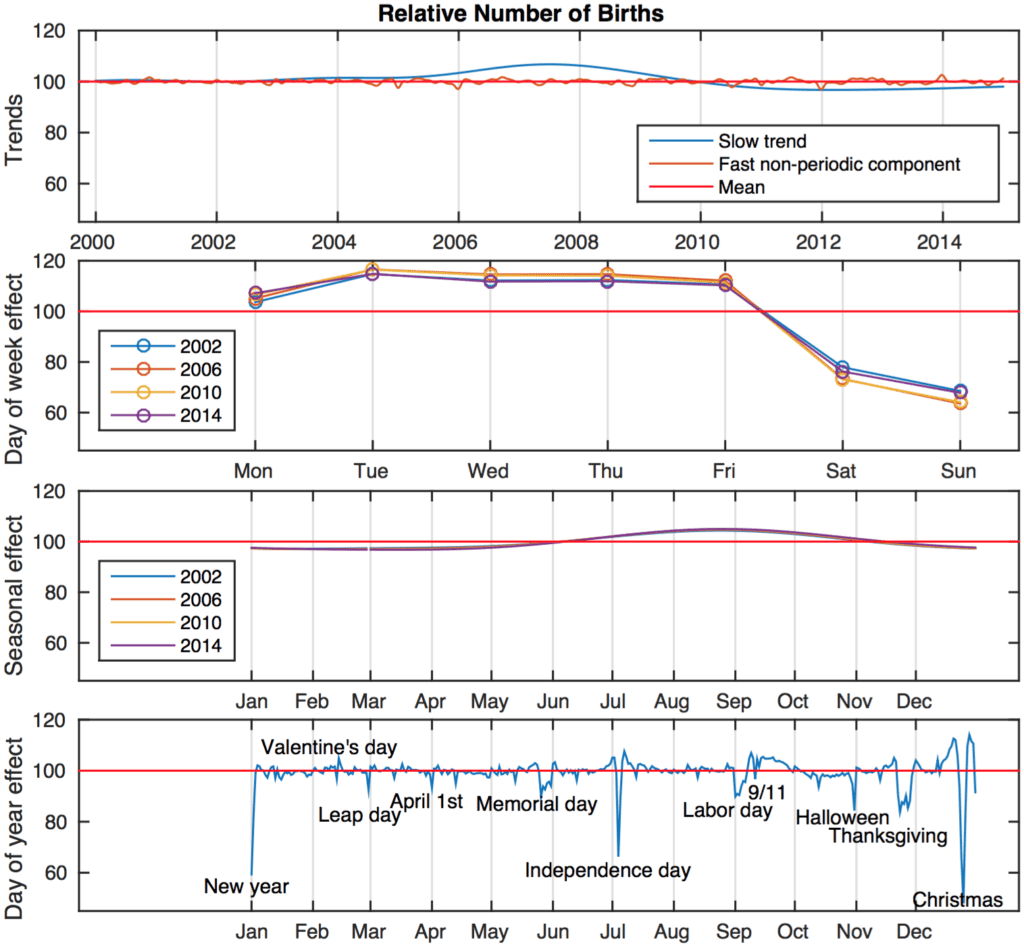
If you look carefully on the bottom graph you’ll again see the little dips on the 13th of each month, but the blow-up above is better. The reason I’m showing all four graphs here is so you can see the decomposition with all the pieces of the model.
Comparing to the results from the earlier time period (just look at your copy of BDA3!), we see the new pattern on September 11th, also in general the day-of-week effects and special-day effects are much higher. This makes sense given that the rate of scheduled births has been going up. Indeed if the birth rate on Christmas is only 50% on other days, that suggests that something like 50% of all births in the U.S. are scheduled. Wow. Times have changed.
Checking and improving the model
There are some funny things about the fitted model. Look either at the graph above with the day-of-year patterns (the very second plot of this post) or, equivalently, the bottom of the four plots just above.
The first thing I noticed, after seeing the big dips on New Year’s, July 4th, and Christmas, were the blurs around Labor Day, Memorial Day, and Thanksgiving. These are floating days in the U.S. calendar, changing from year to year. (For example, Thanksgiving is the fourth Thursday in November.) At first I thought this was a problem, that the model was trying to fit these floating holidays with individual date effects, but it turns out that, no, Aki did it right: he looked up the floating holidays and added a term for each of them, in addition to the 366 individual date effects.
The second thing is that the day-of-week effects clearly go up over time, and we know from our separate analyses of the 1968-2008 and 2000-2014 data that the individual-date and special-day effects increase over time too. So really we’d want these to increase for each year in the model. Things are starting to get hard to fit if we let these parameters vary from year to year, but a simple linear trend would seem reasonable, I’d think.
The other problem with the model we fit can be seen, for example, around Christmas and New Year’s. There’s a lot more minus than plus. Similarly on April Fools and Halloween: the number of extra births on the days before and after these unlucky days is not enough to make up for the drop on the days themselves.
But this can’t be right. Once a baby’s in there, it’s gotta come out some time! The problem is that our individual-date and special-day effects are modeled as delta functions, so they won’t cancel out unless they just happen to do so. I think it would make more sense for us to explicitly fit the model with little ringing impulse-response functions that sum to 0. For example, something like this: (-1, -2, 6, -2, -1), on the theory that most of the missing babies on day X will appear between days X-2 and X+2. It’s an assumption, and it’s not perfect, but I think it makes more sense than our current (0, 0, 1, 0, 0).
You can also see this problem arising in the last half of September, where there seem to be “too many babies” for two entire weeks! Obviously what’s happening here is that the individual-date effects, unconstrained to sum locally to zero, are sucking up some of the variation that should be going into the time-of-year term. And, indeed, if you look at the estimated time-of-year series—the third in the set of four graphs above—you’ll see that the curves are too smooth. The fitted Gaussian process for the time-of-year series got estimated with a timescale hyperparameter that was too large, thus the estimated curve was too smooth, and the individual-date effects took up the slack. Put zero-summing impulse-response functions in there, and I think the time-of-year curve will be forced to do better.
This is a great example of posterior model checking, and a reminder that fitting the model is never the end of the story. As I said a few years ago, just as a chicken is an egg’s way of making another egg, Bayesian inference is just a theory’s way of uncovering problems with can lead to a better theory.
Data issues
Results from U.S. CDC data 1994-2003 look similar to the results from U.S. SSA data 2000-2014, but for some reason in the overlapping dates in years 2000-2003 there are on average 2% more births per day in the SSA data:
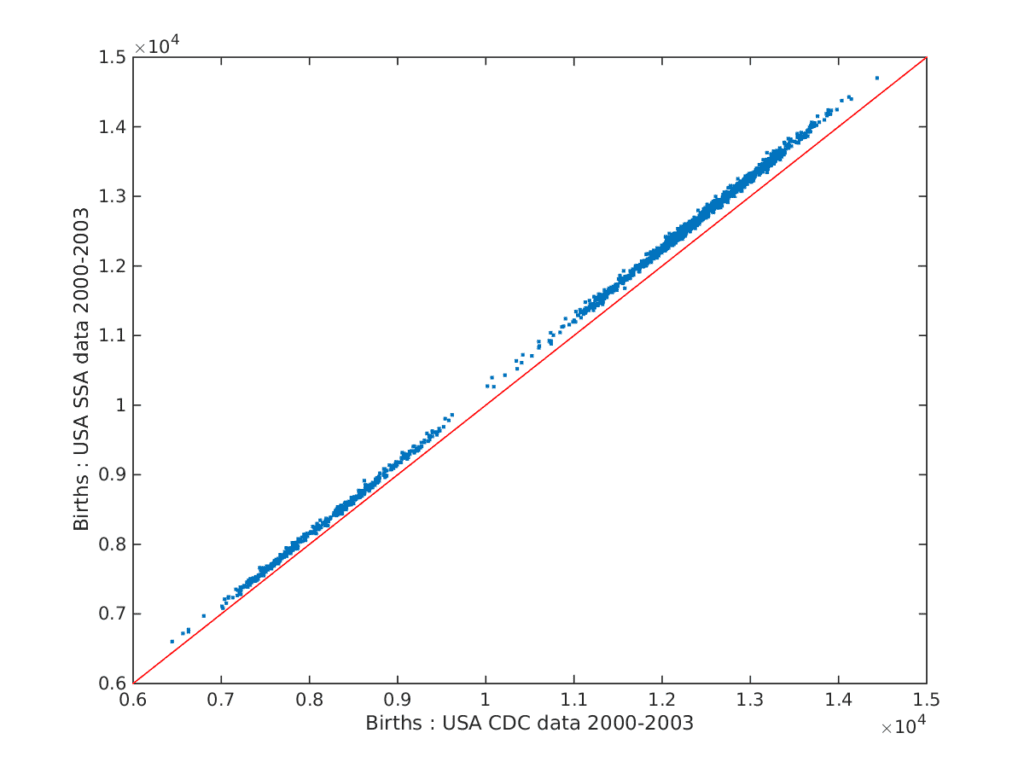
It’s easy enough to adjust for this in the model by just including an indicator for the dataset.
The model
We (that is, Aki) fit a hierarchical Gaussian process to the data, with several additive terms (on the log scale, I assume; at least, it should all be on the log scale). Details are in the appropriate chapter of BDA3.
Code or it didn’t happen
I’d love to give you the Stan code for this model—but it’s too big to fit in Stan. It’s not that the number of data points is too big, it’s that the Gaussian process has this big-ass covariance matrix which itself depends on hyperparameters. So lots of computing. We have plans to add some features to Stan to speed up some matrix operations so this sort of model can be fit more efficiently. Also there should be some ways to strip down the model to reduce its dimensionality.
But for now, the model was fit in GPstuff. And here’s the GPstuff code for various versions of the model (maybe not quite the one fit above).
P.S. The movie Friday the 13th and its sequels were supposed to be really bad—I never actually saw any of them myself, despite being in the target audience—but I just read the wikipedia article for the series, and it’s fascinating. Just for example:
When Harry Manfredini began working on the musical score for the 1980 film, the decision was made to play the music only alongside the killer so as not to trick the audience into believing that the killer was around during moments that they were not supposed to be.[34] Manfredini explains that the lack of music for certain scenes was deliberate: “There’s a scene where one of the girls […] is setting up the archery area […] One of the guys shoots an arrow into the target and just misses her. It’s a huge scare, but if you notice, there’s no music. That was a choice.”[34] Manfredini also noted that when something was about to happen, the music would cut off so that the audience would relax a bit, which allowed the scare to become more effective.
Since Mrs. Voorhees, the killer in the original Friday the 13th, does not show up until the final reel of the film, Manfredini had the job of creating a score that would represent the killer in her absence.[34] Manfredini was inspired by the 1975 film Jaws, where the shark is not seen for the majority of the film, but the motif created by John Williams cued the audience as to when the shark was present during scenes and unseen.[35] While listening to a piece of Krzysztof Penderecki music, which contained a chorus with “striking pronunciations”, Manfredini was inspired to recreate a similar sound for Friday the 13th. He came up with the sound “ki ki ki, ma ma ma”, based on the line “Kill her mommy!”, which Mrs. Voorhees recites repeatedly in the final reel. The “ki” comes from “kill”, and the “ma” from “mommy”. To achieve the unique sound he wanted for the film, Manfredini spoke the two words “harshly, distinctly, and rhythmically into a microphone” and ran them into an echo reverberation machine.[34] Manfredini finished the original score after a few weeks and recorded it in a friend’s basement.[35] Victor Miller and assistant editor Jay Keuper have commented on how memorable the music is, with Keuper describing it as “iconographic”. Manfredini makes note of the mispronunciation of the sounds: “Everybody thinks it’s cha, cha, cha. I’m like, ‘Cha, cha, cha’? What are you talking about?”[36]
538’s simple nonparametric method of estimating special day effects seems less error prone than the big fancy model. I don’t really understand what the model’s value added is, but I assign a pretty high prior that this is my own shortcoming. Andrew?
Z:
The 538 graph estimates an average “the 13th” effect, averaging over 12 days of the year. This would be pretty noisy if you wanted to estimate each individual date. With enough data, any method would work, but given data limitations, there are benefits to fitting a model.
It’d be interesting to see someone run both strategies on a smaller data-set to see the actual benefits.
Naive question: What exactly does adjusted for time + seasonality + day of week mean?
It’s a good question. In this case, it says “relative to average adjusted for …” and the idea is that you’re comparing to what’s expected on that day if you know “time, seasonality, and day of week”
One way to intuitively understand that is as a low-pass filter. If we fit the data restricting our function to have only slow variations on the scale of say 30 days, then we’ll get a “time, and seasonality” (here think of “time” as something like “timescale of > 200 days” and “seasonality” as “timescale between say 30 and 200 days”. Of course, day of week introduces an exactly periodic component with period 7 days.
Other than averages that we can compute strictly with these “slow moving” or “7 day periodic” functions, what else is going on? That’s what’s meant.
Thanks.
Just to compare, I wonder how a raw, un-adjusted graph would look. i.e. All you do is for each day average over all the years in the dataset.
Aki / Andrew: Is that graph posted anywhere?
The dataset is online, so it’s not hard to calculate this. The datasets are mentioned (but not actually linked) at the top of this page:
https://research.cs.aalto.fi/pml/software/gpstuff/demo_births.shtml
they are:
https://chmullig.com/wp-content/uploads/2012/06/births.csv
and
https://www.mechanicalkern.com/static/birthdates-1968-1988.csv
The thing about doing sums over each day of the year is that you’re assuming EXACT periodicity of 1 year (which isn’t even a well defined unit of time thanks to leap years).
Births are basically a function of time in days, and f(t) doesn’t need to be exactly periodic with period 365 days, and all the spectral components integer multiples of this 365 day period. In fact, it isn’t according to the graphs above.
However, the gaussian process stuff *is* very computationally challenging due to the massive covariance matrix. So, it’s a good question as to whether you can get nearly-as-good inference by some other less computationally heavy method.
One issue is that we’re using a lot of knowledge in setting up the covariance matrix. There are NxN elements where N is the number of days of data we have. But there are only 5 or 10 hyperparameters that determine the full NxN matrix.
Can we specify some basis expansion using maybe a few more hyperparameters, say 10 or 20, which represents our knowledge sufficiently well to get similar high quality inference? For example, can we do a low order chebyshev polynomial to represent the long time trends, a radial basis function expansion that represents the “seasonal trends”, a periodic 7 day “weekday” basis function for the weekly trends, and some kind of discrete exactly year-periodic “special day” functions and wind up with say 20-50 parameters to estimate but the computation is much faster than inverting a million element matrix?
Yes, inverting a million element matrix for this sort of problem does have the feel of killing mice with cannon.
Rahul:
In many areas of research, you start with the cannon. Once the mouse is dead and you can look at it carefully from all angles, you can design an effective mousetrap. Red State Blue State went the same way: we found the big pattern only after fitting a multilevel model, but once we knew what we were looking for, it was possible to see it in the raw data.
I completely agree with Andrew here. When I first analysed the new 2000-2014 data, I did not have special component for 9/11, but with the “cannon” model it popped out anyway. After that I added specific component taking into account that 9/11 is likely to happen only after 2001.
Well, maybe. But, it is a pretty small cannon in today’s arsenal. Playing around with my new laptop earlier this week, I ran some tests including calculating the inverse of large matrices using Mathematica. I generated 1000 x 1000 matrices using RandomReal and inverted them. Mean execution time of 100 trials was 59 ms—according to Mathematica’s timing function—but clock time seemed longer.
If I crank the matrix size up to 10,000 x 10,000, it takes about 24.3 seconds to calculate the inverse (mean of 10 trials). And, if I go to 30,000 x 30,000, I seem to get memory thrashing and I have never waited for completion.
Interestingly, it takes Mathematica about 500 ms to invert a 300 x 300 matrix of integers—using integer arithmetic. In one case, it calculated that the (1,1) element of the inverse matrix is a fraction with a denominator having about 456 digits.
I may be missing something, but I don’t think these are the new datasets (i.e. 2000-2014). Are they (specifically the SSA data) available somewhere?
Thanks
Rahul:
The raw data show the gross features of the data (Christmas, etc.) but it’s hard to pick out what’s going on with the smaller effects such as Valentine’s Day.
For the older dataset you can see “average over all the years” here
https://statmodeling.stat.columbia.edu/2012/06/14/cool-ass-signal-processing-using-gaussian-processes/
The problem with this approach is that when the number of years is not divisible by 7, the weekday effect dominates and some special day effects are difficult to see. Weekdays, leap days and floating special days makes simple approaches more difficult.
It’s sort of non-intuitive to interpret the plot based on adjusted data. e.g. The ordinate of the Christmas dip is approx. 50% from the plot.
But the births.csv file reveals that the dip is more like 20% of the Dec. average.
Isn’t the adjustment exaggerating the effect?
Rahul:
The data you’re looking at are the old 1968-1988 data, where the Christmas dip is 20%. The above graph show the 2000-2014 data, where the Christmas dip is 50%. The effect has increased over the years, as the proportion of scheduled births has increased. There’s no exaggeration here; it’s just a change over time.
Ah ok. My bad. Thanks for pointing out my mistake.
Interesting.
Completely unrelated. What happened to last week’s scheduled items?
Thurs: FDA approval of generic drugs: The untold story
Fri: Acupuncture paradox update
Bob (who is sitting on pins and needles waiting for the Friday item)
PS Google Books Ngram Viewer shows use of the phrase “sitting on pins and needles” peaking just before 1900—but, it started coming back in about 1980 and in about 2003 usage surpassed that of any time in the 20th century. (smoothing of 3 in Ngram viewer)
“PS Google Books Ngram Viewer shows use of the phrase “sitting on pins and needles” peaking just before 1900—but, it started coming back in about 1980 and in about 2003 usage surpassed that of any time in the 20th century. (smoothing of 3 in Ngram viewer)”
1978: https://www.youtube.com/watch?v=fGWR3uI3Qa0
(But the word order is backwards, and ‘needles and pins’ doesn’t show the post 1980 rise that ‘pins and needles’ does.)
Well, let’s go back to the beginning or back to 1963 anyway: https://www.youtube.com/watch?v=SSbM_Zmx9kA
Bob
I don’t think “50% of all births are scheduled” is a valid extrapolation. Some women going into labor they day before Christmas will come in, get some help (e.g. pitocin, or having medical staff that don’t want patients stuck in L&D on Christmas), and deliver the same day, whereas otherwise it would have been the next day (on Christmas). Some women going into labor on Christmas evening will wait until the next day to go into the hospital (really), or go in the same night and have delivery delayed (pharmacologically or otherwise) until the next day because the hospital is low on staff or the family just doesn’t want a Christmas birthday. I suppose these are still forms of “scheduling” but not in the way you would normally schedule a C-section or regular induction days or weeks in advance.
It would be interesting to look at Christmas Day by day of week as well. Births are likely to be scheduled for week days not week ends … so how does the number of Christmas day births differ between weekdays and weekends.
There are ways to bring on contractions – I suspect that women will use those ways on days after Christmas but not before. Before and on Christmas they’ll be too busy with Christmas preparations and celebrations to want to deal with a baby as well.
Megan:
Yes, and in general I think the individual-date effects will interact with weekend effects: When April Fool’s or Feb 29th is Sunday, for example, I’d expect the number of births to be slightly lower than for the same date as a weekday, but not as low as would be implied by the additive model of special-date and day-of-week effects.
Are there any really old datasets on births by day of year? It’d be interesting to check if there was any Christmas dip at all, say in 1900.
Rahul:
That’s a good question! This sort of data is easy enough to gather. But I guess back in 1900 most of the births were at home, so there’s a possibility that people would misreport.
This conclusion does match with the data I am familiar with as an employee in a New York maternity unit. About 30% of labors are scheduled inductions, and about 30% are c sections. I’m not sure how many of the c sections are scheduled, but considering in New York it is the norm to schedule a c section for all moms with a previous c section and any baby who is breech (feet or butt down, which is around 3-7% of babies depending on when the determination is made), as well as babies determined to be “large” which is entirely subjective as measurements can be off by as much as 20%, and that the WHO estimate for the number of c sections that should be medically indicated is only about 10-15% of all births, I could easily see scheduled c sections making up another 20% of all births in New York. The choice of when to induce is not based on staffing, but on convenience. For example, my hospital schedules a full day of c sections on Wednesday’s because the mothers will stay 3 days after the procedure and go home on Saturday morning, when the traffic is light and the family can enjoy the weekend together.
These decisions are absolutely a huge part of how deliveries are determined, and have been since about the 1950s, when women were routinely given scopolamine to remove their senses and memories of labor and then strapped down to prevent them from hurting themselves while waiting. Doctors back then made all of the decisions on timing themselves, based on their expertise but also their golf schedule and weekend plans. That idea of women being a passive part of their own labor decisions has continued through our current labor and delivery practices, with doctors deciding when it would be convenient to deliver. We now have the technology to schedule inductions and c sections very precisely. We also have the ability to “augment” labors by carefully titrating a pitocin drip to cause women to proceed through labor on a precise (but unmanageably painful) schedule. So even if a delivery is not scheduled, if you are coming in at a time that may be inconvenient for the doctor, such as close to a holiday, they are more likely to enforce strict time limits on the phases of labor and to forcefully suggest augmentation or c section even if not medically indicated.
In summary, 50% sounds about right but I would argue it’s higher at some hospitals (which would offset the birth center and home births that are never augmented or scheduled due to legal restrictions on these practices out of hospital). Statistically, the single most important factor in deciding how you deliver and what your birth outcomes are is your provider at the time of delivery. We are truly living in the dark ages.
FiveThirtyEight has made the raw data for the above analysis available here
https://github.com/fivethirtyeight/data/tree/master/births
Is there an approximate data set for the number of c-sections on each day, perhaps from a subset of hospitals?
I’m remembering that our second daughter’s scheduled c-section was scheduled for June 30, which was the last day of the medical practice’s fiscal year. [they were reorganizing as of July 1, and would not have been covered by our insurance, requiring us to switch practices at the last minute or pay for it all ourselves.]. I’m not particularly superstitious, but I don’t think we’d have intentionally scheduled a c-section for Friday the 13th.