A couple years ago Wei and I published a paper, Difficulty of selecting among multilevel models using predictive accuracy, in which we . . . well, we discussed the difficulty of selecting among multilevel models using predictive accuracy.
The paper happened as follows. We’d been fitting hierarchical logistic regressions of poll data and I had this idea to use cross-validated predictive accuracy to see how the models were doing. The idea was that we could have a graph with predictive error on the y-axis and number of parameters on the x-axis, and we see how adding new parameters in a Bayesian model increased predictive accuracy (unlike in a classical non-regularized regression, where if you add too many parameters you get overfitting and suboptimal predictive performance).
But my idea failed. Failed failed failed failed failed. It didn’t work. We had a model where we added important predictions, definitely improved the model—but that improvement didn’t show up in the cross-validated predictive error. And this happened over and over again.
Our finding: Predictive loss was not a great guide to model choice
Here’s an example, where we fit simple multilevel logistic regressions of survey outcomes given respondents’ income and state of residence. We fit the model separately to each of 71 different responses from the Cooperative Congressional Election Survey (a convenient dataset because the data are all publicly available). And here’s what we find, for each outcome plotting average cross-validated log loss comparing no pooling, complete pooling, and partial pooling (Bayesian) regressions:
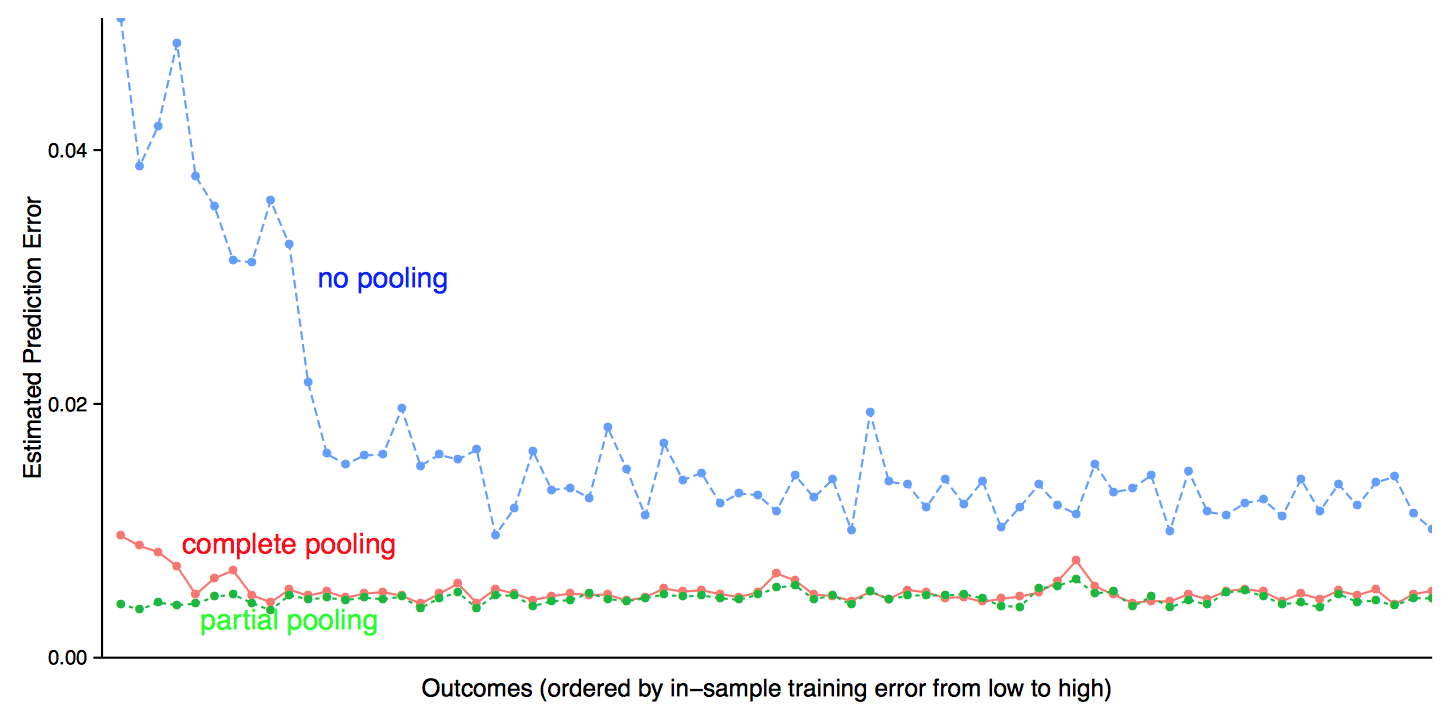
OK, partial pooling does perform the best, as it should. But it’s surprising how small is the difference compared to the crappy complete pooling model. (No pooling is horrible but that’s cos of the noisy predictions in small states where the survey has few respondents.)
The intuition behind our finding
It took us awhile to understand how a model—partial pooling—did not perform much better given that it was evidently superior to the alternatives.
But we eventually understood, using the following simple example:
What sorts of improvements in terms of expected predictive loss can we expect to find from improved models applied to public opinion questions? We can perform a back-of-the-envelope calculation. Consider one cell with true proportion 0.4 and three fitted models, a relatively good one that gives a posterior estimate of 0.41 and two poorer mod- els that give estimates of 0.44 and 0.38. The predictive log loss is −[0.4 log(0.41) + 0.6 log(0.59)] = 0.6732 under the good model and −[0.4 log(0.44) + 0.6 log(0.56)] = 0.6739 and −[0.4 log(0.38) + 0.6 log(0.62)] = 0.6763 under the others.
In this example, the improvement in predictive loss by switching to the better model is between 0.0006 and 0.003 per observation. The lower bound is given by −[0.4 log(0.4) + 0.6 log(0.6)] = 0.6730, so the potential gain from moving to the best possible model in this case is only 0.0002.
Got that? 0.0002 per observation. That’s gonna be hard to detect.
We continue:
These differences in expected prediction error are tiny, implying that they would hardly be noticed in a cross-validation calculation unless the number of observations in the cell were huge (in which case, no doubt the analysis would be more finely grained and there would not be so many data points per cell). At the same time, a change in prediction from 0.38 to 0.41, or from 0.41 to 0.44, can be meaningful in a political context. For example, Mitt Romney in 2012 won 38% of the two-party vote in Massachusetts, 41% in New Jersey, and 44% in Oregon; these differences are not huge but they are politically relevant, and we would like a model to identify such differences if it is possible from data.
The above calculations are idealized but they gives a sense of the way in which real differences can correspond to extremely small changes in predictive loss for binary data.
Can this be formalized by formulating an alternative y-axis metric that incorporates the size of the expected real application & the size of the cross validation sample?
3 reasons? I see only one..
See: Buzzfeed Posts: What’s the Magic Number for “Best of” Lists? and cross-reference with Andrew’s sense of humor w.r.t. adding pictures to posts.
But why do you think 0.0002 is small? This can be a huge difference depending on the context!
Anon:
As I wrote, 0.0002 will be hard to detect.
If you don’t use predictive performance to judge models, what do you use instead? The example of log loss indicates that log loss measures make important differences seem tiny, but that is an argument against that loss measure, not against predictive performance as a standard for model choice in general. Maybe I’m just ignorant, but can you ever say “my model predicts worse, but it’s better [for some other reason]?”
Maybe a way to rephrase the argument is “use predictive performance as an ordinal measure, not a cardinal one.”
Bradford:
The concern is that the predictive measures can be noisy enough or subject to enough biases that they won’t work so well as an ordinal measure either. In answer to your question, “if you don’t use predictive performance to judge models, what do you use instead?”: I don’t have a general answer. In the example discussed in the above post, it makes sense to compare predictions at the state level rather than at the level of individual voters.
It seems like the performance metric you are using for evaluating the model is not the one you actually care about.
I’m not sure I entirely understand how set up the partial pooling vs. the no pooling. It says you add an assumption to allow the variance of the interaction parameters to change based on each survey outcome. So how many different values are there? I would think J1XJ2, but the way survey outcome is worded could mean J1 or the total sample size.
Are you using something similar to this:
https://statmodeling.stat.columbia.edu/2004/10/26/partial_pooling/
The difference in predictive accuracy between the complete pooling model and the partial pooling model is only small compared to the difference with the no pooling model, which is kind of your own fault for choosing a highly convex loss function. What’s the fundamental problem here?
I didn’t get this sentence: ” We had a model where we added important predictions, definitely improved the model—but that improvement didn’t show up in the cross-validated predictive error.”
How did you know the model improved, if not by the predictive error?
Sometimes models are used for prediction, sometimes for identification of underlying causal or correlative factors. In fact, lots of the stuff I do with Bayesian statistics is about identifying parameters and there is no prediction of future or out of sample data involved at all. So, I can certainly see how adding factors could increase the INFORMATIVENESS of the model while leaving prediction of future/out-of-sample data unchanged or even worse.
Here is a simple physical example: suppose you’re trying to determine something about cooking times for pre-made food products in a microwave. You have a model that predicts the actual cooking times for those 10 tested products very well. The model has 2 parameters, weight of the food, and rated wattage of the microwave. Now, you add as factors information about the water content, fat content, and the minimum thickness dimension of the food. The cooking time predictions become less accurate on average over the posterior for the parameters. Yet, you are able to identify the effect of packaging (via the thickness calculation) and the effect of the food composition. What you really care about is designing packaging for different types of food based on their composition.
This model is likely to generalize better, and most likely it will predict better for some kind of “optimal” choice of parameters, but it adds two dimensions to the model and the uncertainty in those dimensions could be enough so that the average predictive accuracy across the posterior distribution for the parameters goes down… but, clearly, this model is going to be better for helping you design packaging than one that doesn’t really offer any information about the effect of packaging and water content.
Sometimes out-of-sample prediction isn’t as important as “usefulness” for the purpose you have in mind.
+1
How is this possible (I am not saying it isn’t, just asking how)? If adding predictors makes out-of-sample fit worse, it means that extra predictors are in some sort of correlation with other predictors within the sample that is not true out of sample. Which means that whatever you’ve learned looking at the sample won’t hold in general…
@Daniel
I had the same question as D.O.
I like the microwave analogy. Could you make up toy data to illustrate what you are saying?
I think the confusion comes from not thinking like a Bayesian. You’ve added two extra dimensions, and you have uncertainty over those dimensions. If your data isn’t informative enough (sample too small, not distributed broadly enough in the various dimensions of observation etc), then *averaged over the posterior* you could have worse predictive performance, while some particular values of the parameters would still have better predictive performance. Typical frequentist/classical methods will take point estimates, and those point estimates might be a lot like “particular values” I’m talking about.
@Rahul: I’m not sure how I’d go about generating this data, but it’s not just the data, you also need to have a causal model to go along with it.
OK. I’m just not convinced as to how the situation you are describing will result.
Here’s my naive reasoning: If the model helps you design packaging better then the thickness must have a fair bit of impact on the cooking time. If your sample did have points with enough variation in thickness then the original model which didn’t use the thickness as a predictor at all must have had a pretty bad fit & predicative performance.
It’s like trying to estimate someone’s weight from his age and sex alone while dropping height as a predictor entirely.
In other words, if adding the thickness predictor degrades model performance then I’m not sure whether such a model is going to help you much in designing packaging anyways.
I’m sure I’m missing something, and hence I was curious about a toy data set. :)
Suppose that thickness doesn’t vary much in your 10 samples. It varies a little bit, and you get a little bit of information about the proper coefficient. If you do leave-one-out of the 10, you just happen to get worse predictive performance with the thickness information because of happenstance of those 10. Now you go to package a pot-roast, where it’s 8 times as thick, your model predicts based on thickness^2 because that’s how diffusion of heat scales… so you have massively better prediction for this case because it’s well outside of the range of your original data.
So, your model with thickness involved is more useful for the wider range of uses you imagine you will have, even though it doesn’t help within the original 10 samples.
*averaged over the posterior* means for example that you draw a sample of the coefficients from the posterior, make the predictions for each coefficient sample, and then average the predictive error across this sample.
What does averaged over the posterior mean?
Agreeing with Daniel here, I think it’s an interesting exercise, but these data and particularly this model are not really designed to predict individual level behavior out of sample; they are designed to produce good estimates. If limited to having one variable income is not what you would choose and no one really thinks that this is not a situation in which a single variable model is correct and if they had to pick one, income would probably not be it. But who would really think that’s correct? I know we aren’t in OLS world here, but the basic premise that good models should include all relevant variables and exclude irrelevant variables just makes sense especially if we know that they are not independent.
To me this raises an interesting question (somewhat related the the logistic post the other day). On the one hand, I think it’s right to use partial pooling models because they actually substantively capture the way the world is in a better way. Just like I use logistic models because they map better to the reality of 0,1 variables. However, a lot of times, as was mentioned the other day, the results of a logistic analysis are not substantively different and a standard analysis is really good enough for some purposes. Likewise, a lot of times we don’t get that much difference in results by using partial pooling. There is probably some publication bias where if there are big differences people show both and talk about them, but where there are small differences they don’t. So I don’t think I’m that shocked to think that in the normal course of things a lot of times the complete and partial end up pretty close.
>”The above calculations are idealized but they gives a sense of the way in which real differences can correspond to extremely small changes in predictive loss for binary data.”
Reminded me of this:
“We said that the laws of nature are approximate: that we first find the “wrong” ones, and then we find the “right” ones. Now, how can an experiment be “wrong”? First, in a trivial way: if something is wrong with the apparatus that you did not notice. But these things are easily fixed, and checked back and forth. So without snatching at such minor things, how can the results of an experiment be wrong? Only by being inaccurate. For example, the mass of an object never seems to change: a spinning top has the same weight as a still one. So a “law” was invented: mass is constant, independent of speed. That “law” is now found to be incorrect. Mass is found to increase with velocity, but appreciable increases require velocities near that of light. A true law is: if an object moves with a speed of less than one hundred miles a second the mass is constant to within one part in a million. In some such approximate form this is a correct law. So in practice one might think that the new law makes no significant difference. Well, yes and no. For ordinary speeds we can certainly forget it and use the simple constant-mass law as a good approximation. But for high speeds we are wrong, and the higher the speed, the more wrong we are.
Finally, and most interesting, philosophically we are completely wrong with the approximate law. Our entire picture of the world has to be altered even though the mass changes only by a little bit. This is a very peculiar thing about the philosophy, or the ideas, behind the laws. Even a very small effect sometimes requires profound changes in our ideas.”
https://www.feynmanlectures.caltech.edu/I_01.html
Even if the impact on predictive skill is small, considering why the improved model “worked” can have a huge impact on what type of data is collected in the future, etc. That is when some use can come of it.
I think some of Andrew’s point was lost judging by comments. I had the advantage of being there when Wei was going through all of this with him.
The predictive accuracy did improve and predictive accuracy is what we care about. Andrew succinctly summarizes the problem. If the true proportion is 0.4 and you predict 0.38 or 0.44, that seems big as a difference in prediction, but is a puny 0.003 nats in expected log (base e) loss per unit prediced. What’s going on is that the log loss is very flat near the true solution, then really dives when you overpredict or underpredict near 0 or 1. You can exponentiate as the speech recognition people like to do to report perplexity, which is just entropy exponentiated; perplexity has a simple analogue as the number of uniformly uncertain possibilities your choice is equal to. So a coin flip has an entropy of 1 and a perplexity of 2. Ten coin flips have an entropy of 10 bits and a perplexity of 1024 (I don’t think there’s a name for the units).
That almost sounds exactly opposite to what I inferred from Andrew’s post, so thanks for clarifying this.
So what we are saying is that we just need to use the *right* measure for the predictive performance? Apparently the log loss is a very blunt measure.
I am not sure what is the problem, mathematically speaking. If you want to detect difference of 1% (0.41 vs. 0.40) you have to have roughly 2500-strong sample. If the average log-loss is 2e-4/trial, it gives 0.5 improvement for the whole thing. Is it too little? If you want to subdivide the sample then you’ll get more fine-grained information with accuracy of each fitted parameter traded off. Am I wrong in not being surprised?
As a general principle I’d say that if you’re looking at data from counties or census tracts or voting districts, partial pooling should be much better than no pooling or complete pooling. So I’m surprised that isn’t the case when measured in terms of prediction error. Suppose Andrew had written “we compared models with no pooling, complete pooling and partial pooling, and partial pooling performed noticeably better than either of the others.” THAT wouldn’t have surprised me at all, I would have said “Well, of course, it’s a more realistic model (with at least one additional parameter), it’s going to have substantially less prediction error.” And I would have been wrong.
Sometimes when someone says “I have a surprising result…” I’ll stop them and ask for the background, and then see if I can guess what the result is. Once I’ve seen something, it can be hard to imagine what I would have thought if I was still in the state of ignorance I was in before I heard it.
Perhaps you would have guessed, with assurance, “of course the more realistic model is not going to have noticeably lower prediction error.” I wouldn’t have.
Well, first of, it’s not about me personally. The question is objective one — whether it is reasonable to expect 1% discrimination for a parameter that governs less than a thousand or so instances. Second, partial pooling should work best when there is a considerable, but not very large heterogeneity in data. Lack of heterogeneity will make complete pooling reasonable and very large heterogeneity won’t improve on no pooling. So basically my question is whether it is really a bad metrics that does not allow a good method to shine or lack of sufficient data and/or structure in the data that leads to relative irrelevancy of partial pooling. Maybe many years of experience with this kind of data tells you that it is exactly the sort of data where partial pooling is a big winner that led to the surprise, but because I don’t have that kind of experience, I would like to ask what exactly is surprising.
maybe kind of like the home run discussion a couple of days back? On the one hand, lots of interesting considerations as to whether and why 5%, 10% or 20% was the better probability estimate. On the other hand, they were all about equally “wrong” when predicting that night’s event.