Regression coefficients are not very pleasant to look at when listed in a table. Moreover, the value of the coefficient is not what really matters. What matters is the value of the coefficient multiplied with the value of the corresponding variable: this is the actual “effect” that contributes to the value of the outcome, or with logistic regression, towards the log-odds ratio. With this approach, it is no longer necessary to scale variables prior to regression. A nomogram is the visualization method based on this idea.
An example of a logistic regression model of credit risk, visualized with a nomogram is below:
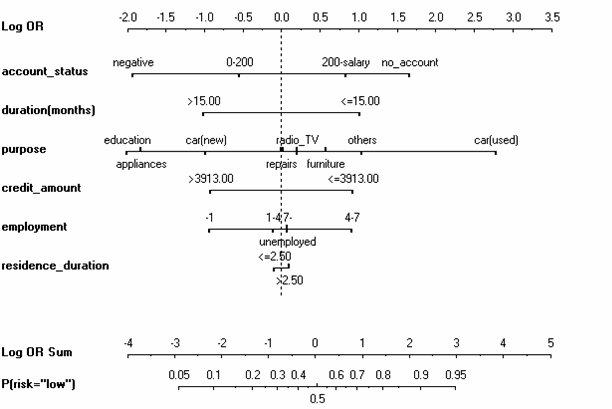
We can see that the coefficients for the nominal (factor) variables are grouped together on the same line. The intercept is implicit through the difference between the dashed line and the 0.5 probability axis below. The error bars for individual parameters are not shown, but they could be if we desired. We can easily see whether a particular variable increases or decreases the perception of risk for the bank.
It is also possible to display similar effect functions for nonlinear models. For example, consider this model for predicting the survival of a horse, depending on its body temperature and its pulse:

As soon as the temperature or pulse deviate from the “standard operating conditions” at 50 heart beats per minute and 38 degrees Celsium, the risk of death increses drastically.
Both graphs were created with Orange. Martin Mozina and colleagues have shown how nomograms can be rendered for the popular “naive” Bayes classifier (which is an aggregate of a bunch of univariate logistic/multinomial regressions). A year later we demonstrated how nomograms can be used to visualize support vector machines, even for nonlinear kernels, by extending nomograms toward generalized additive models and including support for interactions. Frank Harrell has an implementation of nomograms within R as a part of his Design package (function nomogram).