This is Jessica. Earlier this year, I was reading some of the emerging work on AI bias and fairness, and it got me thinking about the nature of claims (and common concerns about them) in AI/ML research compared to those in empirical social science research. In a social science like psych, one could characterize researchers as often aiming to learn a function from (often small) data so they can interpret parameter values to make claims about the real world referents they are thought to summarize. Whereas in In AI/ML, the goal is more to learn a function from large data in order to make claims about its performance on unseen data. So how much do the types of reproducibility concerns that arise in AI/ML work resemble those in the social sciences?
Discussions of reproducibility, replicability, and robustness of claims made in ML-oriented research appear more nascent than in social science methods reform, but are cropping up and (I hope) will eventually become more mainstream. I say ML-oriented research to include both research aimed at producing new ML techniques and more applied ML research where claims about performance tend to be more domain-specific. The idea of a reproducibility crisis affecting ML research has been around for a few years; Joelle Pineau started talking about this a few years ago, initially about problems reproducing results in deep reinforcement learning (though there are earlier papers on reinforcement learning claims being vulnerable to overfitting to the evaluation environment). Pineau led the ICLR 2018 reproducibility challenge and there have been subsequent ICLR challenges and NeurIPS reproducibility programs among others. The initial ICLR challenge found only 32.7% of reported attempts to reproduce 95 papers were successful in reproducing most of the work in the paper given whatever materials the authors provided.
Most of the work I’ve seen focuses on reproducibility over replication or robustness, which makes sense as if you can’t reproduce the results in the paper on the same data, you shouldn’t expect that you’ll be able to replicate them on new data, or that they’ll be robust to different implementations of the learning methods.
Some of the reasons for non-reproducibility are obvious, like not being able to obtain either the code or training data, which I would assume is less common than it is social science, but still apparently doesn’t happen at times. And as described here, some of the problems may be due simply to bad or incomplete reporting, given that another study found that over half of 255 papers could be successfully independently reproduced (successfully reproduced meaning that 75%+ of the claims made could be reproduced) and this number increased when the original authors were able to help, unlike examples of adding the original authors in psych reproduction attempts.
But then there’s the more interesting reasons. How different is “the art of tweaking” in AI/ML oriented research relative to empirical psych, for instance? There’s the need to tune hyperparameters, the inherent randomness in probabilistic algorithms, the fact that the relationships between model parameters and performance is often pretty opaque, etc., all of which may contribute to a lack of awareness that one is doing the equivalent of cherrypicking. I’ve done only a little applied ML work but the whole ‘let’s tweak this knob we don’t fully understand the implications of and try rerunning’ which Pineau implies in the talk linked above seems kind of like par for the course from what I’ve seen. Among researchers I would expect there is often some attempt to understand the knob first, but with deep models there are design choices where the explanations are still actively being worked out by the theorists. I guess in this way the process can be similar to the process of trying to get a complex Bayesian model to fit, where identifying the priors for certain parameters that will lead to convergence can seem opaque. In the conventional empirical psych study analyzed using NHST, I think of researcher “tweaking” as being more about tweaking aspects of the data collection (e.g., the set of stimuli studied), of the data included in analysis, and of how parameters of interest are defined. There’s also an asymmetry in incentives in ML research to hyper-tweak your model and not the baseline models you’re benchmarking against, which you want to look bad. Maybe there’s an analogue in psych experiments where you want your control condition to perform badly.
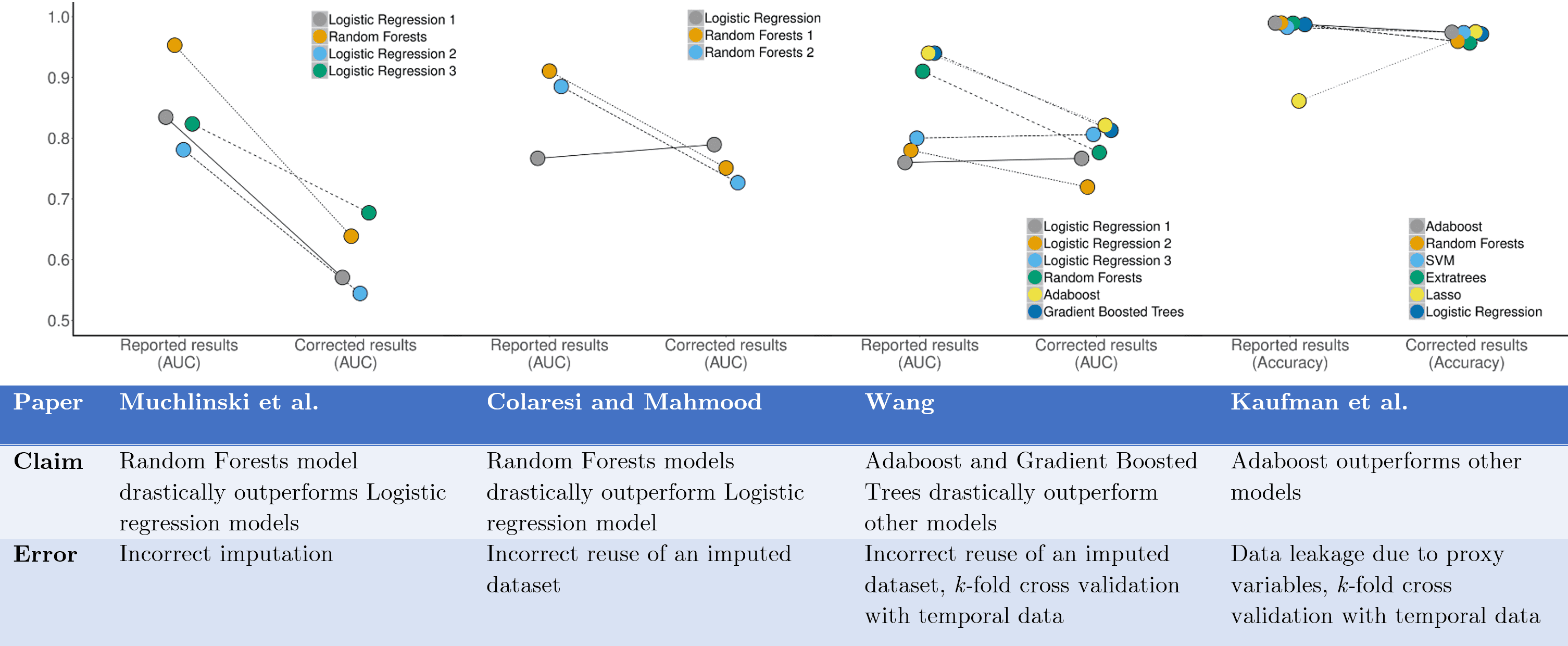
“Leakage” is another point of comparison. In reform discussions affecting empirical psych, pre-registration is framed as a way to prevent researchers from making analysis decisions conditional on the specific data that was collected. In applied ML, leakage can seem less human-mediated. In a recent paper, Kapoor and Narayanan describe a case study on applied ML in political science (see also this project page), where the claims are about out-of-sample performance in predicting civil war onset. They identified recent civil war related studies published in top poli sci journals claiming superior performance of ML models over logistic regression, and ultimately found 12 that provided code and data and made claims about ML model performance using a train-test split. Four papers in this set claimed an ML model outperformed logistic regression, and they tried to reproduce these results. For all four, they were able to reproduce the rankings of models, but they found errors in all four analyses stemming from leakage, none of which were discoverable from the paper text alone. When they corrected the errors, only one of the cases resulted in the ML model actually performing better than logistic regression models.
The types of leakage Kapoor and Narayanan found included imputing test and training data together, such that the out-of-sample test set captures similar correlations between target and independent variables as observed in the training data. The paper that did this was also not just imputing a few values, but 95% of the missing values in the out-of-sample test set. Yikes! Also, interestingly, this paper had already been criticized (in political science venues), and their code revised, but the imputation leakage had not been pointed out. And then other papers were re-using inappropriately imputed data, which as Kapoor and Narayanan point out, can then “lend credibility to exaggerated claims about the performance of ML models by ‘independently’ validating their claims. Other examples just in this set of four papers include data leakage due to using variables that are proxies for the dependent variable; when they removed these and reran the models, they found not only did the ML models no longer beat logistic regressions, but they also all failed to outperform a baseline that predicts war when war occurred in the previous year and peace otherwise. Finally, several of the papers did k-fold cross validation on temporal data without using procedures like forward chaining to prevent leakage from the future data.
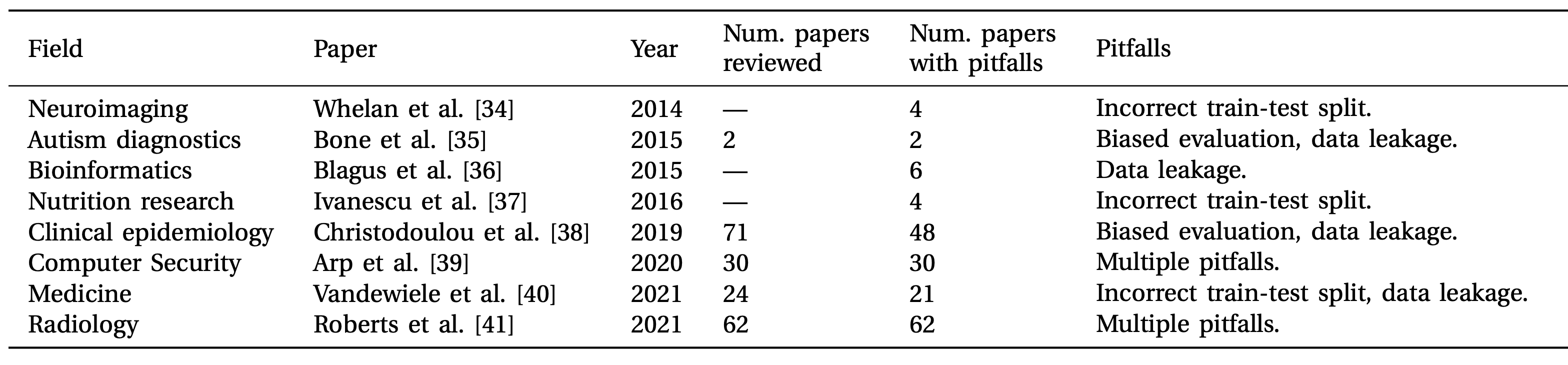
They also include a table of results from other systematic evaluations of applied ML in quantitative fields, as evidence that there’s potentially a reproducibility crisis in research fields that use ML methods:
It almost makes you think watching a few random videos, finding the appropriate python libraries, and pumping out some useful classification models isn’t as easy as thousands of tutorials, blog posts, certificate programs, etc. make it out to be.
One other class of reproducibility issues in ML oriented research that Kapoor and Narayanan address, which also comes up a little in some of the earlier reports, is insufficient uncertainty quantification in these model comparisons. Perhaps my favorite sentence from the 2019 NeurIPS report is this one: “Thirdly, as opposed to most scientific disciplines where uncertainty of the observed effects are routinely quantified, it appears like statistical analysis is seldom conducted in ML research (Forde and Paganini, 2019; Henderson et al., 2018).” Nine of the 12 papers Kapoor and Narayanan obtained data and code for included no form of uncertainty quantification (including reporting any kind of significance testing or CIs on performance) for the out-of-sample model performance comparisons. The size of the test set in some of the papers they reviewed was a source of variance (one of the papers had only 11 instances of civil way onset). That same paper compared performance based on smoothed ROC curves rather than the empirical curves, and the difference in performance associated with this choice is as big as the best minus the worst performance metric reported. Again, yikes. I imagine there’s probably lots more to say with regard to how unaddressed uncertainty affects claims made in ML papers.
Jessica,
Fine commentary. I am neither a social science nor a statistics expert, but your main points I do comprehend. From my observation, the even broader challenge is to translate such good analysis for the general public and subject matter experts b/c that, im my view, is where the value can best be assessed.
The failure to do uncertainty quantification in ML is a huge problem. Back in the 1990s and 2000s, when the ML field was much smaller, several methodological papers were published and methodological standards were much higher. But the rapid growth of the field and the computational cost of deep learning mean that several experiment designs (e.g., with cross-validation) are no longer feasible. I would be interested in teaming up with some statisticians to write a paper on evaluation methodology for deep learning that would give guidelines for how to capture and analyze more of the sources of variability in modern machine learning methods. I think journal and conference reviewers are lacking such guidelines today.
+1. It seems needed; after reading Kapoor and Narayanan and looking at some of the other work mentioned above, on top of learning more about UQ in ML, I am inspired to spend more time thinking about ML uncertainty.
I worry a little that compared to a field like social psych, the interest/criticism of field outsiders, journalists, etc. that helped motivate efforts around reproducibility/replication will be harder to generate around ML work, since the bad claims are more about unreliable performance comparisons than they are about inherently interesting statements as ‘agreeing to be honest before you check your odometer makes you honest!’
Also, some of the more visible concerns in media, to humanists, etc have tended to be about the more socially-oriented concerns with the claims (fairness/bias, ability to be adversarially tricked, etc), maybe because of the novelty relative to other types of data-driven science. So this may detract attention somewhat from the reproducibility concerns.
Well, one promising approach to quantifying uncertainty in classification ML models is conformal prediction, which we discussed the other day. I’ve come to the conclusion that it is a great start, and that we all seem to agree that uncertainty quantification in ML models is important and underdeveloped. I’ve also come to the conclusion is that the primary reason it is not well known (conformal) is that it is presented in a much more complex manner than necessary. Many readers on this blog will find the “gentle” introduction to conformal prediction and other descriptions of the technique satisfying, but I do not. The mathematical descriptions seem almost totally unnecessary for understanding the technique and learning how to implement it. I’m not denying the usefulness and necessity of formalizing the concepts used in conformal prediction, but when you compare it to the ease with which people can run ML models, it does not surprise me that many ML practitioners just don’t know it exists and/or don’t feel it desirable to use.
> presented in a much more complex manner than necessary
After you pointed this out (I think in Jessica’s post) I went and dug and wooof, agreed 100%. Difficult to understand, and lots of emphasis on the math properties early (which I find hard to appreciate).
The Angelopoulos and Bates tutorial seems simpler (I like the 3 line python example near the start), but by the time I got to it I was tired.
Imagine an AlphaGo type system that only trains successfully for one magic value of the random seed. But it does actually work — using that random seed, you end up with a neural network policy that can actually play Go.
To me, that’s not exactly satisfactory and probably shouldn’t be published. But I’m not totally sure, if the task is hard enough (like beating humans at Go) maybe it’s still of interest.
I think this gets at two distinct issues: did you correctly measure the generalization of your learned models on the task, and then on top of that, can you argue your training algorithm also works in general on the meta-task of spitting out good models. Both are at risk of distortion from hyperparameter tweaking.
This reminds me of something I’ve been thinking about lately, which didn’t make it in the post: how ML can be used to make possibilistic arguments, like your AlphaGo example. I had a paper recently where we trained and tested a suite of ML models to evaluate some measures we had devised to approximate a form of judgment (specifically, different ways in which a transformed visualization could be said to retain the important ‘message’ of the original). ML wasn’t really part of the paper’s contribution, but we used it to get a sense of the upper bound on performance if you use our measures to approximate human rankings. I haven’t dug into the civil war prediction papers that Kapoor and Narayanan looked at, and it wouldn’t affect their results, but I’m curious how the claims there are presented – more like ‘look, we can find an ML model that beats logistic regression for this dataset’ or ‘this type of ML model beats logistic regression for this type of task.’ They are different.
It also occurs to me in cases where the claim is more possibilistic, and various models or parameterizations are tried and reported on, at least some sense of uncertainty relevant to generalization is conveyed, because you’ve alluded to how accuracy is sensitive to the fit between the model type, the parameters, and the specific data.
Also makes me wonder, is anybody multiversing over hyperparameters or opaque architecture decisions and reporting on that? Or does that only happen in papers that are explicitly trying to understand the effects of certain decisions?
If I had stayed at Columbia, the next grant I was planning to write was in applying statistics to evaluating ML to highlight the reproducibility crisis there. One of my friends in ML couldn’t understand why I thought there was a problem, because he said nobody believed any ML claims until they’d been reproduced in multiple labs! I’d be happier with that answer if tenure and promotion committees didn’t care more about publication than reproduction or replication.
The “art of tweaking” is often called “graduate student descent” in ML circles. In my old field of natural language processing, it was grounds for rejection to report anything other than an officially sanctioned train/test split. What we saw over 10–20 years was massive overfitting of those test sets. In particular, researchers published paper after paper, many in the top journals and conferences for the field, showing small improvements on the official train/test split that didn’t hold up under cross-validation. For all I know, they’re still doing that.
Another common error leading to irreproducible algorithms is showing simplified pseudocode. This is a problem that wastes years of researchers lives trying to replicate ideas from other labs. Only after you can’t reproduce that you find out the actual algorithm used didn’t match the pseudocode in the paper. And surprise, surprise—it almost always is tweaked to overfit the test data in the paper. I spent more than a couple months at one point doing just this and have been wary every since.
@cs student: Nice response! I think it’d still be an amazing result to have an algorithm that beats humans at Go when trained on a single magic pseudorandom number generator seed. I don’t actually know how robust the AlphaGo training was. The relevant reproduction for the claim “we built a computer program that beats top humans at Go” is in the playing. I’m happy to treat the reproduction there as taking on humans in new matches. What being seed dependent means is that the algorithm used to fit the model is not robust to choice of seed, but that’s a different claim that could perhaps be dealt with by having the algorithm try multiple seeds.
@Jessica: I don’t understand why you imply that “75% of the claims were good” follows from “over half of 255 papers could be independently reproduced”. It feels to me like the claims being made about the results are rather different than the ability to reproduce their model fits. The claims are often the result of what Andrew has called “story time.”
The “asymmetry in incentives in ML research to hyper-tweak your model and not the baseline models you’re benchmarking against” isn’t just ML—you see it in comp stats, too, where weak baselines of random walk Metropolis or weakly tuned standard HMC still seem to be the norm.
Sadly, I’ve seen far too much of “data leakage due to using variables that are proxies for the dependent variable”. And not just the rookie mistake of random cross-validation with temporally sequenced data. I once saw an ML talk on finance use the S&P 500 (American large cap market index) performance for the entire year to predict individual stock performance within the year. What was surprising is that none of the CS folks in the audience saw the problem even after I tried to explain. Yikes, indeed! I also hear that vision algorithms can be misled into fitting color balance or artifacts added to x-rays, but I have no idea how much of a problem that really is or if the stories are just apocryphal.
Hi Bob,
‘meaning 75% of the claims were good’ was just meant to refer to how that paper defined a paper that was reproducible. I need to take a closer look at that paper before commenting on the extent to which the claims they were talking about were about model fit rather than statements based on performance comparisons; not sure what the breakdown is.
I’ve also heard graduate student descent applied to cases where graduate students are the labelers.
Brutal. My decision not to train in Machine Learning was mainly due to lack of free time, but I still feel vindicated.
The glass is half full in the sense that there’s a lot of work for academics to understand how ML works. It clearly works in the sense that it’s pretty much the only game in town these days if you want to do speech recognition, image recognition, or play Go.
Very interesting post. A comment on something Jessica wrote:
“Most of the work I’ve seen focuses on reproducibility over replication or robustness, which makes sense as if you can’t reproduce the results in the paper on the same data, you shouldn’t expect that you’ll be able to replicate them on new data, or that they’ll be robust to different implementations of the learning methods.”
I don’t work in ML or AI (at least, not in the conventional sense), but rather at the interface of psychology/linguistics/cognitive science.
For me, the issue of reproducibility of a published set of summary statistics (these are usually F-, t-, p-values) seems orthogonal to whether the claim made based on the published summary statistics is replicable or robust. The fact that I can almost never reproduce a published claim (e.g., once I get the data from the authors) doesn’t tell me anything at all about whether the result will be replicable or robust. Fake data simulation helps here a lot. So I wouldn’t go as far as Jessica to link the two things. Maybe there is a link, but there seems to be no way to draw any inference about such a link.
Hi Shravan,
In that sentence I’m saying that if there were problems in a paper such that even the original performance related claims don’t hold (for example, claims like Kapoor and Narayanan’s work identifies in applied ML, about the superiority of ML approaches over simpler models), then there’s no ground for investigating if the claimed result persists upon switching to a different dataset, or a different implementation of the algorithm. So I had in mind comparative claims about performance, not so much summary statistics or specific measures of fit.
I often find that papers can have good ideas without my being able to reproduce their results. Lack of reproducibility is usually just because the original developers didn’t follow good software development practices, because they used proprietary data, or because they used more or different computing than I have.
In terms of proprietary data, we can’t even get Covid sensitivity data out of government funded studies in the UK because universities are hoarding the data under contracts unfavorable to science and public health. So I’m faced with a dilemma: do I trust their results or do I just take a much cruder model like most other studies use?
In terms of just can’t reproduce it even with original developers help, it took person months to conclude we couldn’t reproduce the Gelman and Bois JASA paper results from what’s written in the paper. In their defense, it was a 25 year old paper and things were different then, especially outside of CS. We could reproduce some follow-on results from a different data set and slightly different model. We still don’t know if the issue is data, computation, or what. But that doesn’t mean the ideas in the paper weren’t good. We were able to apply those in other settings and they worked. Would we have done that without Andrew collaborating? Probably not.
Kind of a technical question: what’s your stance on containerizing one-off analysis? For a while now, any analysis I’ve done has been bundled into a docker image, such that reproducibility is as simple as spinning up a jupyter container and hitting “Run All”.
While virtualization and containerization seems inherently more transparent and reproducible to me in theory, I’ve seen people go back and forth on this mainly because the containerization platforms like docker are too new to be lindy-effect tested. If docker-hub goes down in the next 5 years, all that reproducibility is moot
Hi, Shravan. Maybe you don’t work in ML or AI by your own definition, but you do by the definition of ML powerhouses like Google. They classify ML as being part of AI. Then they will call “logistic regression” a form of ML. After all, a neural network is nothing more than a structured non-linear regression, often in the form of a latent representation generator that is followed by a GLM layer for predicting numerical values or categories. “Statistics” is just a word us old-timers throw around for nostalgia’a sake.
Your definitions of “reproducibility” and “replicability” are the same as mine. As is your finding that even some replicable work wasn’t done carefully enough to be reproducible. The big deal for me is that I can’t usually even understand what someone’s proposing without reproducible code. Otherwise, it’s just frustrating guesswork. Blame the concision of ML conference papers combined with no standards for reproducibility (not that I have any such standards in mind to suggest).
For future ref this preprint seems to be (one of) the papers coming out of this post: https://arxiv.org/pdf/2203.06498.pdf (nice work!)