A new paper in Nature communications, The association between early career informal mentorship in academic collaborations and junior author performance, by AlShebli, Makovi, and Rahwan, caught my attention. There are a number of issues but what bothered me the most is the post-hoc speculation about what might be driving the associations.
Here’s the abstract:
We study mentorship in scientific collaborations, where a junior scientist is supported by potentially multiple senior collaborators, without them necessarily having formal supervisory roles. We identify 3 million mentor–protégé pairs and survey a random sample, verifying that their relationship involved some form of mentorship. We find that mentorship quality predicts the scientific impact of the papers written by protégés post mentorship without their mentors. We also find that increasing the proportion of female mentors is associated not only with a reduction in post-mentorship impact of female protégés, but also a reduction in the gain of female mentors. While current diversity policies encourage same-gender mentorships to retain women in academia, our findings raise the possibility that opposite-gender mentorship may actually increase the impact of women who pursue a scientific career. These findings add a new perspective to the policy debate on how to best elevate the status of women in science.
To find these mentor-protégé pairs, they first do gender disambiguation on names in their dataset of 222 million papers from the Microsoft Academic Graph, then define a junior scholar as anyone within 7 years of their first publication in the set, and a senior scholar as anyone past 7 years. They argue that this looser definition of mentorship, as anyone that a junior person published with who had passed the senior mark at the time, is okay because a lot of time there is informal mentorship from those other than one’s advisor, in the form of somehow helping or giving advice, and one could interpret the co-authorship of the paper itself as helping. It seems a little silly that after saying this they present results of a survey sample of 167 authors to argue that their assumption is good. But beyond the potential for dichotomizing experience to introduce researcher degrees of freedom I don’t really have a problem with these assumptions.
To analyze the data, they define two measures of mentor quality as independent variables. First the “big shot” measure, which is the average impact of the mentors prior to mentorship, operationalized as “their average number of citations per annum up to the year of their first publication with the protégé.” Then the hub experience, defined as the average degree of the mentors in the network of scientific collaborations up to the year of their first publication with the protégé.
They measure mentorship outcome, conceptualized as “the scientific impact of the protégé during their senior years without their mentors”, by calculating the average number of citations accumulated 5 years post publication of all the papers published when the academic age of the protégé was greater than 7 years which included none of the scientists who were identified as their mentors.
I have some slight issues with their introduction of terminology like mentorship quality here…. Should we really call a citation-based measure of impact mentorship quality? Yes, it’s easy to remember what they are trying to get at when they call average citations per year “big shot” experience, but at the same time, gender is known to have a robust effect on citations. So defining mentorship quality based on average citations per year essentially bakes gender bias into the definition of quality – I would expect women to have lower big shot scores and lower mentorship outcomes on average based on their definitions. But whatever, this is mostly annoying labeling at this point.
They then do ‘coarsened exact matching’, matching groups of protégés who received a certain level of mentorship quality with another group with lower mentorship quality but comparable in terms of other characteristics like the number of mentors, year they first published, discipline, gender, rank of affiliation on their first mentored publication, number of years active post mentorship, and average academic age of their mentors, and hub experience or big shot experience, whichever one they are not analyzing at the time. To motivate this, they say “While this technique does not establish the existence of a causal effect, it is commonly used to infer causality from observational data.” Um, what?
They compare quintiles separately for big shot and hub where treatment and control are the Qith+1 and Qith quintile. They do a bunch of significance tests, finding “an increase in big-shot experience is significantly associated with an increase in the post-mentorship impact of protégés by up to 35%. Similarly, the hub experience is associated with an increase the post-mentorship impact of protégés, although the increase never exceeds 13%”. They conclude there’s a stronger association between mentorship outcome and big-shot experience than with hub experience since changes to big shot experience have more impact given their quintile comparison approach.
Their main takeaways are about gender though, which involves matching sets of protégés where everything is comparable except for the number of female mentors. They present some heatmaps, one for male protégés and one for female protégés, where given a certain number of mentors, one can see how increasing the proportion of female mentors generally decreases the protégés’ outcomes (recall that’s citations on papers with none of the mentors once the protégé reaches senior status). Many “*” for the significance tests. Graph b is more red overall, implying that the association between having more female mentors and having less citations is weaker for males.
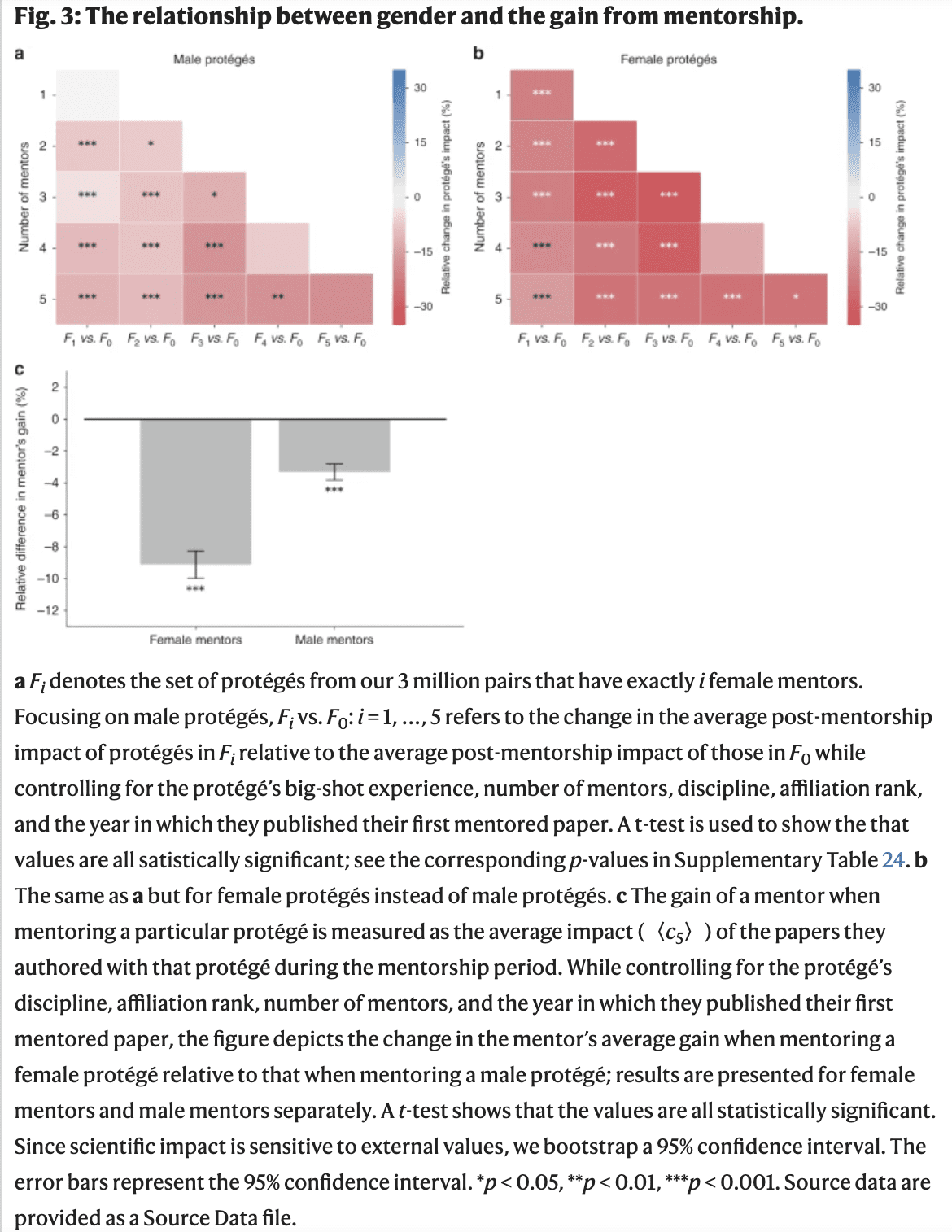
They also look at what mentoring a particular protégé does for the mentor, captured by the average impact (citations 5 years post publication) of the papers the mentor and protégé co-authored together during the mentorship period. They match male and female protégés on discipline, affiliation rank, number of mentors, and the year in which they published their first mentored paper, then compare separately the gains from male versus female protégés for male and female mentors. The downward extending bar chart shows that mentors of both genders see less citations for papers with female proteges, and would seem to suggest there’s a bigger difference between the citations a female mentor gets for papers with a female versus male protégé than that which a male mentor gets for papers with female versus male protégés.
These associations are kind of interesting. The supplemental material includes a bunch of versions of the charts broken down by discipline and where the authors vary their definitions of senior versus junior and of impact, by way of arguing that the patterns are robust. Based purely on my own experience, I can buy that there’s less payoff in terms of citations from co-authoring with females; I’ve come to generally expect that my papers with males, whether they are my PhD students or collaborators, will get more citations. But to what extent are these associations redundant with known gender effects in citations? Could, for example, the fact that someone had a female mentor mean they are more likely to collaborate later in their career with females who, according to past studies, tend to receive less citations on papers where they are in prominent author positions? The measures here are noisy, making it hard to ascertain what might be driving them more specifically.
However, that doesn’t stop the authors from speculating what might be going on here:
Our study … suggests that female protégés who remain in academia reap more benefits when mentored by males rather than equally-impactful females. The specific drivers underlying this empirical fact could be multifold, such as female mentors serving on more committees, thereby reducing the time they are able to invest in their protégés, or women taking on less recognized topics that their protégés emulate, but these potential drivers are out of the scope of current study.
Seems like the authors are exercising their permission to draw some causal inferences here, because, hey, as they implied above, everybody else is doing it. Serving on more committees seems like grasping for straws – I have no reason to believe that women don’t get asked to do more service, but it seems implausible that inequity in time spent on service could be extreme enough to affect the citation counts of their mentees years later, given all the variation in a dataset like this. The possibility of “women taking on less recognized topics“ seems less crazy implausible (see for instance this linguistic analysis of nearly all US PhD-recipients and their dissertations across three decades). Though I’d prefer to be spared these speculations.
Our findings also suggest that mentors benefit more when working with male protégés rather than working with comparable female protégés, especially if the mentor is female. These conclusions are all deduced from careful comparisons between protégés who published their first mentored paper in the same discipline, in the same cohort, and at the very same institution. Having said that, it should be noted that there are societal aspects that are not captured by our observational data, and the specific mechanisms behind these findings are yet to be uncovered. One potential explanation could be that, historically, male scientists had enjoyed more privileges and access to resources than their female counterparts, and thus were able to provide more support to their protégés. Alternatively, these findings may be attributed to sorting mechanisms within programs based on the quality of protégés and the gender of mentors.
So, again we jump to the conclusion that because there are associations with lower citations and working with female mentors or protégés, women must be doing a worse job somehow? What set of reviewers felt comfortable with these sudden jumps to causal inference? The dataset used here has some value, and the associations are interesting as an exploratory analysis, but seriously, I would expect more of undergrads or masters students I teach data science to. I’m with Sander Greenland here on the fact that what science often needs most from a study is its data, not for the authors to naively expound on the implications.
Jessica:
Yeah, the correlation-causation thing is annoying. As you say, it’s frustrating that authors can’t just present their data; instead they have to tie it to a problematic analysis.
It would be like if you went to the farmer’s market to buy some apples, and they said: “Sorry, no apples. If you want an apple, you have to buy our apple pie.” But then their apple pie tastes horrible. Why can’t you just sell me the damn apples???
A few years ago in an article called, “They’d rather be rigorous than right,” I wrote about a case of researchers noticing an interesting data pattern but then going over the top in their speculative intepretations:
To return to the paper you discuss in your above post: it was published in Nature, a well known tabloid-style journal. Yes, the authors could’ve just published their data and presented it as exploratory . . . but then no Nature publication, no headlines, indeed we probably wouldn’t be talking about it at all!
To get to specifics: having skimmed the paper in question, I wouldn’t say that it’s epically bad—nothing on the scale of some of those self-refuting regression discontinuity papers or the beauty-and-sex-ratio paper or the ages ending in 9 or himmicanes or ovulation and voting or the collected works of the pizzagate guy or that disgraced primatologist or Weggy or various other published research we’ve discussed in this space over the years. It’s more like run-of-the mill, push-button mediocre push-button social science, a mix of bad decisions (for example, discretizing based on 7 or more years post-PhD, or their claims about “those who do not have a mentor at all”), inappropriate technology (“204 different Coarsened Exact Matchings”), and the sloppiness regarding causal attribution and storytelling that you note above.
One difficulty in research criticism is that there can be pressure from supporters of the work being criticized. Sometimes there’s an attitude that if the research is published in a top journal, that it should be trusted. Or that a criticism is only valid if it supplies a “smoking gun.” But I think that attitude is mistaken. Sure, the “smoking gun” rule allows us to dismiss the examples I listed in the first section of the previous paragraph, and many more. But it’s not just epically bad research that needs to be criticized. There’s also a problem with all the mediocre work that makes bold claims. And it’s a problem with the tabloids that they go for this sort of thing.
Yeah, I agree its not epically bad, hopefully that’s not what comes across from the post! More just irresponsible with the speculation and a bit rough around the edges. It’s mainly the jump from associations between female collaborators and lower citations to listing reasons why women are worse mentors that stands out, given all the prior stuff out there on gender and citations. It’s weird to think that this might be what sold the paper, since it would seem, at least to me, that it would have been relatively easy to do write a more productive discussion section, e.g., talking about how future work might try to disambiguate what they find about prior collaborations seeming to be predictive from what’s been found in other gender and citations research.
I also agree, things don’t need to be epically bad to be criticized! In fact I think sometimes it’s more helpful to see the non-epically bad stuff criticized.
Thanks for the post; yours are all good points related to the authors’ speculations. However an arguably bigger problem I have with the paper occurs much earlier: the identification of “quality” with “number of citations.” This focus on citation metrics, widespread and getting worse, is immensely frustrating. Here, the authors use routinely the word “quality,” rather than simply stating “number of citations,” subtly but forcefully getting the reader to accept that quality is what’s being measured. Your point that the data should be stated without needing weird speculations is good, but also the data should be stated for what it is. Really, this is a paper about how citations correlate with the gender compositions of authors, nothing more (or less).
“However an arguably bigger problem I have with the paper occurs much earlier: the identification of “quality” with “number of citations.””
+1
If you replace the term “quality” with “big shot experience” and “network experience” both of which are variation on citation count throughout the whole paper becomes about the disparity of citations. And then it becomes about a self-fulfilling prophecy or vicious cycle in which students see this and therefore have a preference for male mentors. Though I would also replace the term mentor with the term co-author throughout. By using more neutral terms the paper could become an interesting analysis of citation patterns and their consequences. But by talking about things like “quality” — of course low quality is fundamentally a bad thing while variation in citation count is an interesting thing.
Also they make claims about “While current diversity policies encourage same-gender mentorships to retain women in academia” with no citation.
Using the terms treatment and control is also highly misleading.
Yes, that terminology is annoying, and it surprised me to see them use it throughout without ever mentioning the various reasons to question citations as an unbiased measure. I didn’t read too much into it though, since I often see authors labeling some set of measures or conditions by some property they are believed to be associated with, and I don’t know that its wrong to think that higher citations and degree in the author network wouldn’t be correlated with quality. Still, something like ‘centrality’ for degree centrality in the citation and author networks would’ve been less offputting.
I was just wondering this morning, what would be Andrew Wakefield’s citation index.
Jkrideau:
I looked Andrew Wakefield up on Google scholar. I couldn’t figure out how to list the articles in decreasing order of citation numbers, but a quick glance revealed the famous retracted article with 3600 citations and then others with 482, 369, 232, 213, 211, 208, and 204. So, yeah, dude’s pretty well cited, even accounting for the fact that medical papers get tons of citations.
Then I was curious about other scientists who retired after research irregualarities:
Diderik Stapel has articles with 525, 456, 399, 287, 262, 212, and 209 citations. Pretty good, but then again here we’re talking about fiction, in which case maybe we should be comparing his sales to Agatha Christie, Earl Stanley Gardner, etc.
Edward Wegman has articles with 964, 446, and 296 citations. Not bad, but if here the fair comparison is to Wikipedia, which must have literally millions of citations at this point. From that perspective, Weggy isn’t looking so hot.
Marc Hauser has 72,000 citations. Actually, that’s screwed up, as 24,000 appear to be to a book by Noam Chomsky that Hauser is not a coauthor of. Take that one away and he only has 48,000 citations. Still, that’s a pretty good haul for someone who wouldn’t let his coauthors see his data.
Brian Wansink has 34,000 citations, which is pretty impressive too, but we should really be comparing him with other authors of children’s fiction, in which case J. K. Rowling has him beat.
It’s the case of no publicity being bad publicity if they spell your name right. It would be interesting to see how many of the Wakefield citations are near the words “discredited” and “retracted.”
As I read this and then skimmed the article itself, the thought recurring in my head was: how incredibly sexist to take results known to be confounded by bias and push that uphill to be a measure of quality as though lower quality generates the biased citation results. Imagine if this were about race: having a mentor of this or that race means a lower quality result or experience because citations. It wouldnt get in print because it would reek of racism. This reeks of sexism.
Regarding “What set of reviewers felt comfortable […]”, reviews are actually attached. I understand that Nature is now asking reviewers and authors if they are happy with reviews to be public and if all agree they are attached, so this might become more common. They can be found in the Supplementary information section or direct link to pdf
https://static-content.springer.com/esm/art%3A10.1038%2Fs41467-020-19723-8/MediaObjects/41467_2020_19723_MOESM2_ESM.pdf
That’s a very interesting review history. Would be interested to know the gender of the reviewers! But also something I think that can happen is that when there are so many issues with a paper. The reviewers hesitate to bring up the second level issues once the top level issues (using causal language, problems with the data etc) are dealt with. With so many problems it seems like a situation where bringing in a new reviewer would be good.
How does forming lasting academic partnerships affect the analysis?
If I understand correctly, mentor/mentee co-authored papers are excluded from the analysis of a mentee’s senior-year impact? Then, if females tended to have more long-term co-operations, wouldn’t that exclusion affect their score?
> Serving on more committees seems like grasping for straws.
I recall Nancy Reid identifying this as a risk to her and other female faculty at the University of Toronto around 2000 -“Every other day I am asked to on be another committee and I may already be on too many to the disadvantage of my academic productivity [from memory]”
So this has changed, perhaps given a higher percentage of female faculty today?
(The similar concerns arose the other day here with regard racial minorities where the percentages are low.)
Hi Keith,
I edited that part just now to make clearer why I said grasping for straws – not because I think its implausible that women might do more service, but because even if that’s true, it seems unlikely that it could be a big part of explaining the citation differences in mentees years later that this paper is showing.
Thanks, you are likely right but I am still worried about there being less time to promote a paper by presenting it at many conferences and seminars. That also raises issues regarding the ability to travel.
I think it is still overall a lower representation of women among US full professors so for those kind of committees that are made up of a lot of senior faculty (search for senior administrators, strategic planning, major policy committees) there is still some “oops this looks bad, we better get a woman on there.” Less so for juniors, but still very much an issue for racial and ethnic minorities.
Thanks.
Keith said,
“I recall Nancy Reid identifying this as a risk to her and other female faculty at the University of Toronto around 2000 -“Every other day I am asked to on be another committee and I may already be on too many to the disadvantage of my academic productivity ”
I recall that in the mid 1970’s I was put on a committee that required members to have tenure, but I didn’t have tenure yet.
And I recall a friend once mentioning that she had recently met a woman mathematician who was also black, and “got asked to serve on n –> infinity committees”. Such was (maybe still is?) life.
When I saw that this was blowing up on twitter I hoped that there would be a write up here.
I haven’t read the paper so I’m going completely on your summary and critique of it here. I feel as though there is a slight mismatch between the extent of your critique and the extent of your negative overall assessment of the paper. I know you said it isn’t “epically bad” but at least compared to the majority of what I read (criminology) the flaws of the paper would put it in the average or maybe even above average quality (although I guess that says a lot about average paper quality). The social science papers I read are usually more blind to confounds and bias, more speculative in terms of causation and especially more overreaching in policy proposals.
My hypothesis is that the controversy this paper is causing is largely because it conflicts with the political views of many on twitter, not because of its methodological shortcomings. In the tweet promoting the paper from the lead author, it has been called “unethical”, “disgraceful” and “dangerous” seemingly not by random trolls either but by academics.
I also think it’s a bit sad that there is this minor twitter storm going around and calls to retract the paper given that two of the three authors are women, in STEM and early career academics. Obviously if the paper was a total disaster that could make sense (depending on your view on retractions) but based on your critique I wouldn’t think it reached that level.
Cj:
I hate twitter, in large part because the style there is for people to make strong statements without backing up by fact or argument.
Regarding the quality of the paper: a lot of science is done in the world and it would not be practical to require it to all be of high quality. Mediocre researchers need to publish too! Also, we can sometimes learn useful things from mediocre work. The problem is when inappropriately strong claims are being made. My take on Jessica’s post was that she was annoyed not so much at the poor choices in the data coding and analysis, as at the strong claims that were made and at the general approach of effortlessly sliding from data to causal claims.
Seconding Andrew, your comment seems more about what people are saying on twitter, rather than what OP said in her post.
I agree that to the extent that this paper is “average”, it is a sign of how crummy most papers are. After all, Bem’s ESP paper was “average” for JPSP, in the sense that it contained many features common to papers published in that journal. Poor operational definitions and unsupported causal speculation from correlational data with unexplored biases are also common features of many papers published these days.
Finally, I love the faint praise that the paper hasn’t “reached that level [of a total disaster]”. I love a good partial disaster myself!
I mean, does anyone who follows these things really not think that papers that take controversial or unpopular positions tend to get more scrutiny than papers that make popular claims and don’t rock the boat? One of my most-cited publications is on the “bad” side of mediocre, but it was on a popular topic and it mostly agreed with the general trend of claims in the literature. No one has ever publicly criticized that paper even though it really is not very good, with the benefit of hindsight. If I’d found the opposite of what I found, it would have gotten torn apart, if I could even have gotten it published in the first place.
Your candor is appreciated.
I complement anon e mouse on insight rather than candor.
Very few people have the objective insight into their own work expressed in anon-e-mouse’ post. If you can’t see it, it doesn’t matter how honest you are.
Unfortunately humans’ lack of insight – their inability to distinguish what’s best for them from what’s objectively true – is a much bigger problem than honesty.
I saw those twitter posts too. I think in some way the paper is “dangerous” in the sense that even if the authors were right, we probably still don’t want to discourage women (or anyone) to have female mentors. There are a lot of other things that make a good mentor besides increasing future citation counts.
The next question is, do we want to apply a higher threshold of quality for these “dangerous” or politically unpopular papers? Maybe? It kind of makes sense that the more impact something can have on the world the more we would want to get it right. And people’s time is a scarce resource too so in terms of post-publication review it makes total sense that this paper would get railed on more than another paper with similar methodological issues. On the other hand, there’s obvious problems about gatekeeping and who gets to do it. And many times we do want to challenge popular opinion. Like Andrew said, mediocre papers should have their place too. They can be building blocks for good papers down the line.
While the various jumps to causality do annoy me, I don’t think retraction is the right response here. If we retracted every paper where there’s some misplaced speculation about what the results mean, we wouldn’t be left with much! Not clear how we would ever draw the line on what is potentially too harmful or offensive. The main contribution is the analyis of associations, and there’s no reason to believe that that is fabricated or that major errors were made that change the results.
They actually use the term “treatment” for observational data.
I appreciate what you’re getting at here, but this is the kind of tone policing that distracts from the real question whether or note the analysis and the data help us understand variation in the consequences of mentoring.
It’s not tone policing to say that I expect professionals to use vocabulary from undergraduate research methods correctly. The tone policing I see in these comments is mainly people accusing people criticizing an article’s methods (something that happens every day on this site) of having some kind of agenda. It’s very passive aggressive — if you want to defend this research defend it, don’t go after the motives of the critics because they might disagree with you on some issue.
+1
I remember getting some of this a few years ago after criticizing that silly ovulation-and-clothing paper. A prominent psychology professor whom I’ve never met sent me an angry email criticizing me for saying mean things about that paper. We had a brief email exchange where more than once I asked him if he really believed that women were three times more likely to wear red or pink during certain times of the month, and amid all his bluster and tone policing he never got around to answering that simple question. Or when that nudgelord went around calling people Stasi for daring to express public disagreement with him . . . again, he didn’t actually defend his claims, he just went on about tone. In these discussions I often want to just get to the scientific questions, but the defenders of the criticized published work find it more comfortable to bring up these meta-arguments.
It’s not unusual to see references to “treatment group” and “control group” in observational studies.
One thing I’ve wondered about this paper: to what extent is it an ideological document? The authors are at NYU Abu Dhabi, and the UAE is not known for it’s progressive gender politics; to some extent this paper could be used to justify not hiring women/including women in professional fields.
Good point.
Doesn’t seem so, the Vice Chancellor of NYU Abu Dhabi is a woman, the Dean of Science is a woman, etc.
Thanks for the write-up, Jessica. Have you had a chance to read through the reviewers’ exchange[1] with the authors? It seems that some of the speculations were actually added to satisfy the reviewers. For example, the entirety of the last paragraph you quoted above was inserted to satisfy Reviewer #1.
With regard to the causal claims, Reviewer #2 was emphatic that they were overstated in the paper and must be removed as a condition to his/her approval. The reviewer even went so far as to provide a list of forbidden words. Now, this is where it gets weird: The authors agreed — and claimed to have removed them from the text — but in fact some causal language remains. (For instance, the forbidden word “impact” is used throughout the text.) Did the editor not notice? Or did they simply decide to publish with the approval of 3/4 of the reviewers?
As a non-statistician, it looks to me like the authors did a tremendous amount of work to satisfy the reviewers. (For instance, the survey was not present in the first draft of the paper. Same for a lot of the supplemental analysis.) Does that necessarily make it correct? No. But it’s not as shoddy as the Twitter Mob would have us believe.
[1]: https://static-content.springer.com/esm/art:10.1038%2Fs41467-020-19723-8/MediaObjects/41467_2020_19723_MOESM2_ESM.pdf
I skimmed them when Konrad posted above. That would not surprise me; the 167 person survey seems like exactly the kind of thing a reviewer might suggest, thinking they are making the paper more rigorous, though in the end it reads more as though the authors are contradicting their own logic. And I’ve been asked in my own work to add speculation about causes to results where we were explicitly being careful not to do that.
I like the idea of sharing all reviews with papers, though maybe we also should get access to the rationale behind editors’ decisions so its clearer what was overridden. Also like the idea suggested above to bring another reviewer in cases when there’s already been a lot of back and forth between reviewers, since I think people get tired sometimes and just want the review process to be over so they give up, or the majority wins.
They added the survey post-review which is crazy to me. It wasn’t suggested, they came up with it as a way to address a very serious issue of measurement. It’s not well thought out, the design is poor and they don’t seem to have much expertise in survey research (even in how they present the results). Rather than really engaging with the critiques they confused the issue by adding something new. I read all the rounds of reviews and I don’t understand either how this was accepted without further revision. I’m sure the reviewers were tired. Bad papers are so much harder to review than good ones.
I think methodology-wise, using matching to derive some correlation is likely a partially sensible routine. But in terms of causal claims, “gender effects” are almost always ill-defined under a potential outcome framework, despite their attraction to twitter.
I am most definitely not a statistician and I am confused by Jessica Hullman’s post in which she argues for a just the facts, ma’am approach. It seems to me that, just as there is no intrinsic meaning of literary texts outside of the interpretation of them, it appears to me that there is no intrinsic meaning to data outside of the interpretation of said data.
I understand that there are problems with the research Hullman is vetting and that the conclusion the researchers drew is not warranted by the data. Andrew seconds her sentiment in his comment. But Hullman does not just say that the researchers’ conclusion is wrong but she seems to be arguing for letting the data speak for data.
So who gets to interpret the data, Jessica Hullman? I must be missing something here. I wonder if males had been found to be worse mentors, if anyone would raise a ruckus? I am on the left but I see and don’t like that there is a lot of pc in the social sciences.
Gordon:
I can’t answer for Jessica, but very quickly I would say that anyone has the right to draw interpretations from the data. The original authors can do so, and so can others. But when the original authors do a bad job of interpretation, this suggests that they could’ve made a better scientific contribution (although without the publicity and the publication in a Nature-branded journal) by posting their data and doing some more straightforward analysis without the questionable storytelling.
Data can’t speak for themselves; data need to be analyzed. That’s one reason for posting data, so that different people can try their analyses.
Interpretation of data is not equivalent to causal analysis. This is made quite explicit above
> What set of reviewers felt comfortable with these sudden jumps to causal inference? The dataset used here has some value, and the associations are interesting as an exploratory analysis
Hullman wrote thie post here and has been commenting actively, why don’t you ask her directly instead of talking about her in the third person?
I’ll respond without being asked :-) Anyone has a right to interpretation, just like anyone has a right to point out the problems with someone else’s published interpretation. I’m not arguing that we do away with all interpretation in scientific work, that’s basically impossible. I’m saying in this case, given the tenuous relationship between what they want to comment on (mentorship quality) and what they measure, not to mention known biases in citation data and how these would seem hard to separate from their findings (which they fail to mention, but there’s quite a bit of work), any interpretations of what’s going on are unlikely to provide much useful information. So when they not only interpret but appear to default to a causal interpretation, it seems we would have been better off without the additional discussion.
This paper could be completely wrong for some of the reasons you mention, but I don’t know understand why some of the speculative causal mechanisms irritate you so much. Based on your tone, I was expecting to see something really sexist in the paper, but instead even the sections you quoted just have a fairly careful and modest discussion of some possible mechanisms, without any strong attachment ot defense of any of them. Compared to some of the things Andrew posts, this is really on the opposite end of the causal inference overreach spectrum. It seems like a violation of taboos in the results themselves is leading some to impute interpretation or tone offenses in the text that are not actually present.
Sara:
See here. Nobody here is saying that this paper is epically bad, but that’s part of the point: leading academics do publish really bad papers in top journals, and it’s worth criticizing that work, but this should not stop us from criticizing mediocre work done by less famous researchers in less prestigious journals.
Thank you for your reply, Andrew. I certainly have always thought that anyone has the right to her/his interpretation. That is a highly defensible position. But Jessica, you invoked Sander Greenland and then wrote “what science often needs from a study is its data.” You did not write “what science often needs from a study is for defensible interpretations to be drawn from it.”
So it looks like your musing near the end of your post is a shot across the bow of the researchers you took on and their like. Cough up the data and we will do the interpreting, could be the subtext. Would you have written what I cited here if the conclusion of the paper had been congenial to you? You repeated Andrew’s phrase almost word for word, without acknowledging that you are valorizing raw data sans interpretation.
I much like your comment, Sara G, your “violation of taboos” is dead on, I detect an ideological agenda. One sees this everywhere these days. I am not defending the sloppy conclusion of these researchers whatsoever but I see a double standard at work. You benighted researchers get to provide the raw data, the data is what science needs from a study. But when I made my comment, then the narrative becomes “anyone has a right to her/his interpretation.” This is I believe what philosophers call an aporia.
You can never prove a counterfactual but I strongly suspect that if this study found that men were worse mentors, there would be no post about it here. Either the data speak for themselves or we need interpretations but you cannot have it both ways. All researchers, bad and good, should have the same standards applied to them and their research should be vetted on empirical and statistical grounds, not ideological ones. I suspect the objections here are more about ideology than sloppiness.
Gordon:
I don’t understand what you’re saying. There’s no “shot across the bow” in the above post. The paper in question is mediocre, but their data are potentially interesting. This happens a lot. The authors of the paper aren’t doing themselves the rest of us else a service by publishing a weak analysis and drawing inappropriate causal conclusions. Never in Jessica’s post or my comment did we suggest that the authors do not have a right to their interpretation. But their interpretation is sloppy and not backed up by their data. That happens.
Also, as I wrote in one of my comments above, the data do not “speak for themselves.” Again, neither Jessica nor I ever said that. Data need interpretation. The authors of this paper are not “benighted”; they just did a mediocre analysis. As we’ve discussed many times on this blog, statistics is hard, like basketball or knitting. It’s not an insult to researchers to say that they didn’t analyze their data well, any more than it’s an insult to me to say that I’m a crappy free throw shooter and I can’t knit a serviceable sock, let alone a sweater.
Regarding your last sentence: you can suspect whatever you want. Regular readers of this blog know that we discuss, positively and negatively, research supporting all sorts of ideologies.
Andrew, I think you do a tremendous job and you are amazingly even-handed. But the manner in which you replied to me seems almost as if you wrote this post. The standards here are very high, I only saw one other post in recent memory that I thought was not up to the usual standards. I have learned a huge amount from reading your blog. I thought it might be okay to dissent but now I am not so sure. Best to everyone, including you, Jessica.
Gordon:
Feel free to dissent! I’m just sharing my views here. I’m not always right.
didn’t read the paper. Just the same, there are so many other glaring potential explanations for this result – including significant methodological problems – that it’s a ridiculous claim to make. *head shake*
Jack Dorsey must love shit like this. Twitter’s financial results suck, so anything that promotes twitter is a godsend for Dorsey. And that just feeds right back into the tabloid loop, right? Corporate support for tabloid science.
It’s interesting to compare Twitter’s treatment of this stuff vs Trump’s incessant lying. This claim is no more true than Trumps ranting about voter fraud. The only difference is that there’s no data to *disprove* it, however ridiculous it might be; and that it’s a ridiculous claim made by people who are widely believed – rightly or otherwise – to not be ridiculous.
I think there are a number of problematic aspects with the data used in this paper.
See Section 13 ‘Summary’ of https://danieleweeks.github.io/Mentorship/#summary
How can one have a set of mentors with an average age > 200? How can one have 91 mentors?
Always always graph your data!
Dan:
Laplace is my mentor. Average age > 200.
Excellent mentor:
Laplace, in 1814, said “we ought to examine [seemingly inexplicable phenomena] with an attention all the more scrupulous as it appears more difficult to admit them“
https://en.m.wikipedia.org/wiki/Sagan_standard
Well that explains it. With all those suffrage committees, how could they be good mentors?
Good idea to check the data. Before reading your comment I went to the Nature page for the paper and downloaded the source data with the intention of producing a better version of the Figure 3 Jessica took from the paper. The data are provided by Figure (so they are different files to the GitHub ones you checked) and the dataset for Figure 3 is in a strange format, one row for each comparison. After discovering that the first row had some 200,000 numbers I decided to drop my plan. Maybe it is to do with the software they used (they do not appear to say what they used), maybe there are other reasons. The value of a work of art depends greatly on its provenance, the same should be true of datasets and the results based on them. The provenance here is murky.
A better version of Figure 3 would be welcome – as a visualization person I had to exercise some self-control not to remark on the figure shortcomings. Never use color channels for quantitative data when position encodings would’ve worked.
Yes, I also observed that the authors provided the data behind some of their Figures in an unwieldy and difficult to use format.
Wish they had shared their analysis code – very curious as to what software they used, and how they actually did their data QC and analyses.
The Journal of the American Statistical Association requires sharing of code and has a Reproducibility Reviewer check what the authors have done. More journals should do the same. While we should all write well-documented code as we work, preparing and documenting code to be shared publicly invariably takes extra time.
As others said above, methodologically speaking, this article isn’t nearly as bad as most others that get shared/published every day. You may argue that this article’s claim can lead to particularly bad consequences, but I don’t buy that necessarily. There was a lot more hate than support for it.
Other apparently innocuous claims such as “this ‘grit’ intervention will solve all education’s problems” waste millions of dollars that could be spent feeding people and saving a few lives — much more important than the tiny impact that this Nature Comm study could cause given how people in academia wouldn’t buy it, even if there was good evidence for it.
A last point: these are scientists, not uninformed rednecks with guns. If there is an issue with the article, we can discuss it rationally, and take it down intellectually instead of by coercion.
> If there is an issue with the article, we can discuss it rationally, and take it down intellectually instead of by coercion.
public discussion of research that isn’t uncritical praise = coercion
or “bullying.”
Yeah, I would appreciate any public discussion of writing as opposed to the usual, ignorance of pull requests, refusal to communicate about what’s written/what’s wrong, trying to cover up work that’s been done, etc.
Definitely I agree.
> public discussion of research that isn’t uncritical praise = coercion
I assumed that David was talking about the efforts of people like Leslie Vosshall. A lot of responses were visceral instead of critical. Yes, there was coercion in play towards getting the article retracted.
In contrast, Jessica Hullman provides a genuine critical approach. The value of doing so – of being capable of doing so – should not be underestimated. I’d like to think I could do the same thing, but that is almost certainly biased thinking on my behalf. I’ve come to the belief that we may need to rely on machine learning to get to neutral truths whenever socially sensitive topics are being investigated.
It seems to me that most of the criticisms I’ve seen online get caught up looking into great detail at the decisions made on definition of impact, estimation of gender from name, and so forth, but miss the elephant in the room which is the role of selection bias in shaping the observed associations. Only researchers who remained in academia to n years after PhD are contained within the sample studied; the large fraction of PhD graduates who never pursue academic careers or who leave the field each year post PhD are lost from follow up. One can imagine many possible pathways of confounding via selection bias that would produce the observed associations. The authors deflect this idea by writing that “our study complements the literature on the relationship between mentorship and attrition from science [39], as we consider protégés who remain scientifically active after the completion of their mentorship period”, as if we could just stick two results from modular analyses together in some way.
Good point.