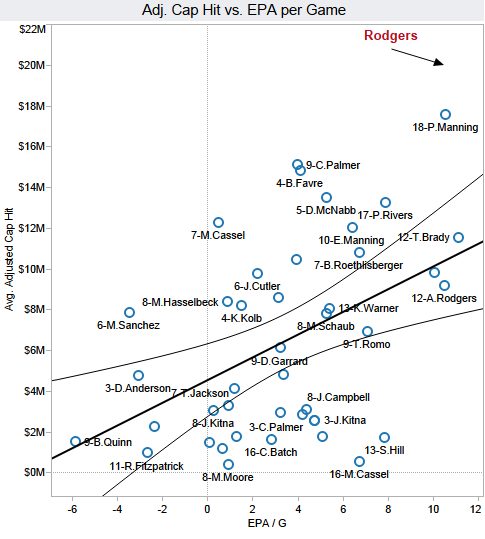
Here’s a political science research project for you.
Joe Biden got about 52 or 53% of the two-party vote, which was enough for him to get a pretty close win in the electoral college. As we’ve discussed, 52-48 is a close win by historical or international standards but a reasonably big win in the context of recent U.S. politics, where the Democrats have been getting close to 51% in most national elections for president and congress. I’m not sure how the congressional vote ended up, but I’m guessing it’s not far from 51/49 also.
Here’s the background. From a combination of geography and gerrymandering, Republicans currently have a structural edge in races for president and congress: Democrats need something around 52% of the two-party vote to win, while Republicans can get by with 49% or so. For example, in 2010 the Republicans took back the House of Representatives with 53.5% of the two-party vote, but they maintained control in the next three elections with 49.3%, 52.9%, and 50.6%. The Democrats regained the House in 2018 with 54.4% of the two-party vote.
And it looks like this pattern will continue, mostly because Democrats continue to pile up votes in cities and suburbs and also because redistricting is coming up and Republicans control many key state governments.
And here’s the question. Assuming this does continue, so that Republicans can aim for 49% support knowing that this will give them consistent victories at all levels of national government, while Democrats need at least 52% to have a shot . . . how does this affect politics indirectly, at the level of party positioning?
When it comes to political influence, the effect is clear: as long as the two parties’ vote shares fluctuate in the 50% range, Republicans will be in power for more of the time, which directly addresses who’s running the government but also has indirect effects: if the Republicans are confident that in a 50/50 nation they’ll mostly stay in power, this is a motivation for them to avoid compromise and go for deadlock when Democrats are in charge, on the expectation that if they wait a bit, the default is that they’ll come back and win. (A similar argument held in reverse after 2008 among Democrats who believed that they had a structural demographic advantage.)
But my question here is not about political tactics but rather about position taking. If you’re the Democrats and you know you need to regularly get 52% of the vote, you have to continually go for popular positions in order to get those swing voters. There’s a limit to how much red meat you can throw to your base without scaring the center. Conversely, if all you need is 49%, you have more room to maneuver: you can go for some base-pleasing measures and take the hit among moderates.
There’s also the question of voter turnout. It can be rational, even in the pure vote-getting sense, to push for positions that are popular with the base, because you want that base to turn out to vote. But this should affect both parties, so I don’t think it interferes with my argument above. How much should we expect electoral imbalance to affect party positioning on policy issues?
The research project
So what’s the research project? It’s to formalize the above argument, using election and polling data on specific issues to put numbers on these intuitions.
As indicated by the above title, a first guess would be that, instead of converging to the median voter, the parties would be incentivized to converge to the voter who’s at the 52nd percentile of Republican support.
The 52% point doesn’t sound much different than the 50% point, but, in a highly polarized environment, maybe it is! If 40% of voters are certain Democrats, 40% are certain Republicans, and 20% are in between, then we’re talking about a shift from the median to the 60th percentile of unaffiliated voters. And that’s not nothing.
But, again, such a calculation is a clear oversimplification, given that neither party is anything close to that median. Yes, the are particular issues where one party or the other is close to the median position of Americans, but overall the two parties are well separated ideologically, which of course is a topic of endless study in the past two decades (by myself as well as many others). The point of this post is that, even in a polarized environment, there’s some incentive to appeal to the center, and the current asymmetry of the electoral system at all levels would seem to make this motivation much stronger for Democrats than for Republicans. Which might be one reason why Joe Biden’s talking about compromise but you don’t hear so much of that from the other side.
P.S. As we discussed the other day, neither candidate seemed to make much of a play for the center during the campaign. It seemed to me (just as a casual observer, without having made a study of the candidates’ policy positions and statements) that in 2016 both candidates moved to the center on economic issues. But in 2020 it seemed that Trump and Biden were staying firmly to the right and left, respectively. I guess that’s what you do when you think the voters are polarized and it’s all about turnout.
Relatedly, a correspondent writes:
Florida heavily voted for 15 minimum wage yet went to Trump. Lincoln project tried to get repubs and didnt work. florida voted for trump because of trump, not because of bidens tax plan.
To which I reply: Yeah, sure, but positioning can still work on the margin. Maybe more moderate policy positions could’ve moved Biden from 52.5% to 53% of the two-party vote, but then again he didn’t need it.
P.P.S. Back in his Baseball Abstract days, Bill James once wrote something about the different strategies you’d want if you’re competing in an easy or a tough decision. In the A.L. East in the 1970s, it generally took 95+ wins to reach the playoffs. As an Orioles fan, I remember this! In the A.L. West, 90 wins were often enough to do the trick. Bill James conjectured that if you’re playing in an easier division, it could be rational to go for certain strategies that wouldn’t work in a tougher environment where you might need regular-season 100 wins. He didn’t come to any firm conclusions on the matter, and I’m not really clear how important the competitiveness of the division is, given that it’s not like you can really target your win total. And none of this matters much now that MLB has wild cards.
P.P.P.S. Senator Lindsey Graham is quoted as saying on TV, “If Republicans don’t challenge and change the U.S. election system, there will never be another Republican president elected again,” but it’s hard for me to believe that he really thinks this. As long as the Republican party doesn’t fall apart, I don’t see why they can’t win 48% or even 50% or more in some future presidential races.
It seems nuts for a Republican to advocate that we “challenge and change the U.S. election system,” given the edge it’s currently giving them. In the current political environment, every vote counts, and the winner-take-all aggregation of votes by states and congressional districts is a big benefit to their party.