Under the subject line, “A potentially dubious study making the rounds, re police shootings,” Gordon Danning links to this article, which begins:
Police use of force is a controversial issue, but the broader consequences and spillover effects are not well understood. This study examines the impact of in utero exposure to police killings of unarmed blacks in the residential environment on black infants’ health. Using a preregistered, quasi-experimental design and data from 3.9 million birth records in California from 2007 to 2016, the findings show that police killings of unarmed blacks substantially decrease the birth weight and gestational age of black infants residing nearby. There is no discernible effect on white and Hispanic infants or for police killings of armed blacks and other race victims, suggesting that the effect reflects stress and anxiety related to perceived injustice and discrimination. Police violence thus has spillover effects on the health of newborn infants that contribute to enduring black-white disparities in infant health and the intergenerational transmission of disadvantage at the earliest stages of life.
My first thought is to be concerned about the use of causal language (“substantially decrease . . . no discernible effect . . . the effect . . . spillover effects . . . contribute to . . .”) from observational data.
On the other hand, I’ve estimated causal effects from observational data, and Jennifer and I have a couple of chapters in our book on estimating causal effects from observational data, so it’s not like I think this can’t be done.
So let’s look more carefully at the research article in question.
Their analysis “compares changes in birth outcomes for black infants in exposed areas born in different time periods before and after police killings of unarmed blacks to changes in birth outcomes for control cases in unaffected areas.” They consider this a natural experiment in the sense that dates of the killings can be considered as random.
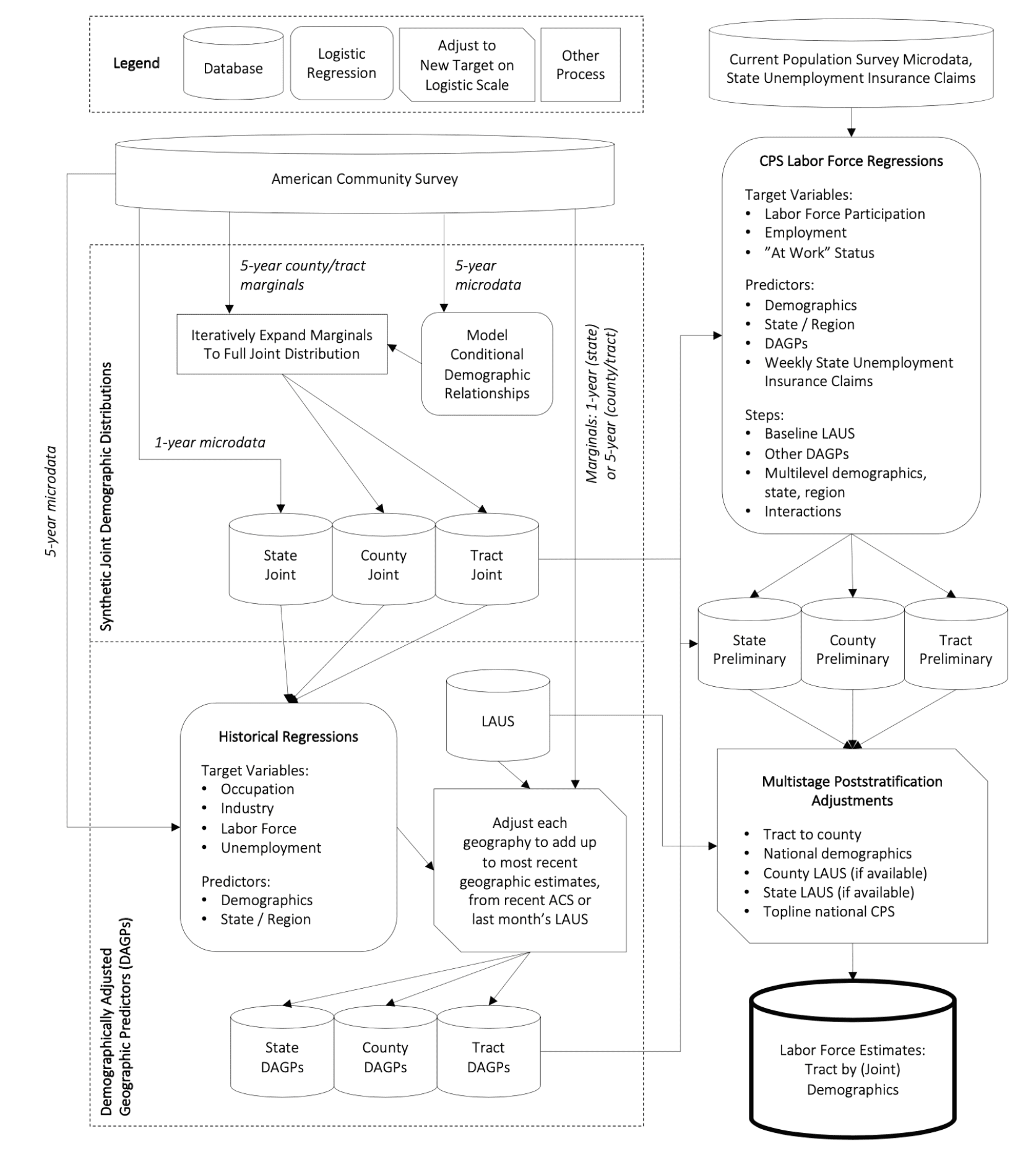
Here’s a key result, plotting estimated effect on birth weight of black infants. The x-axis here is distance to the police killing, and the lines represent 95% confidence intervals:
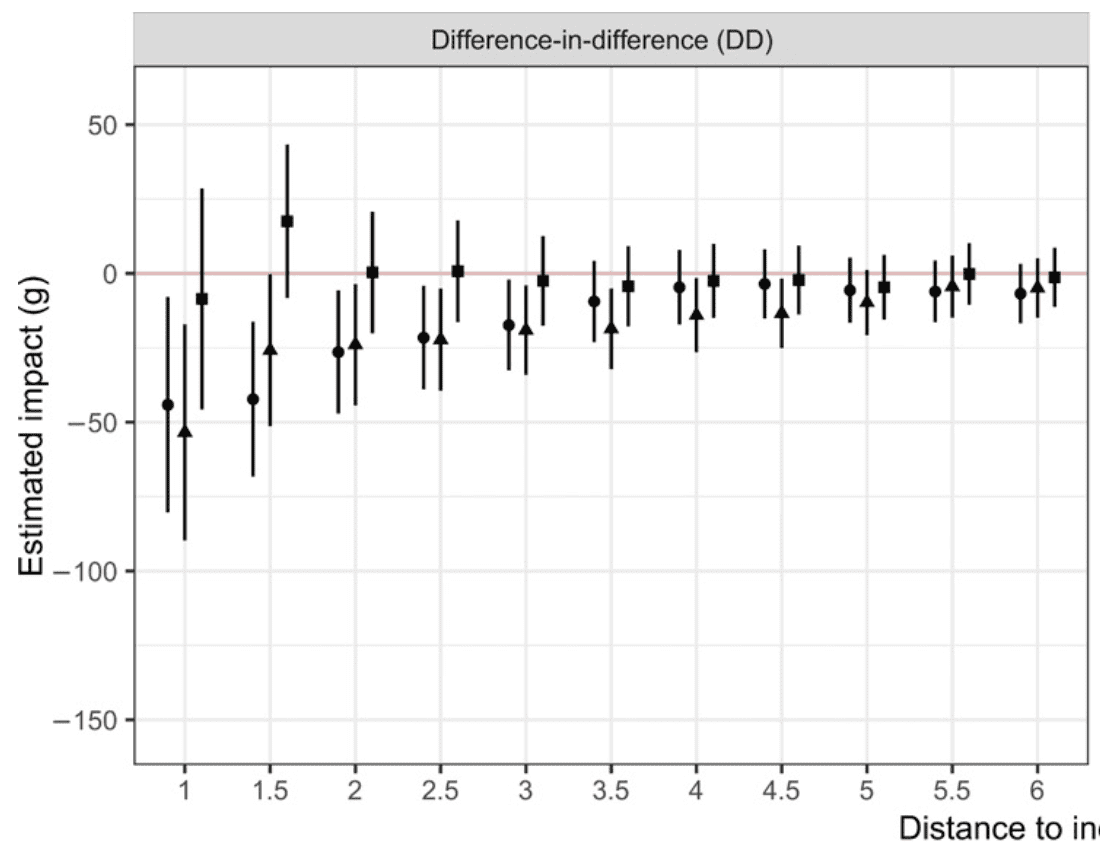
There’s something about this that looks wrong to me. The point estimates seem too smooth and monotonic. How could this be? There’s no way that each point here represents an independent data point.
I read the paper more carefully, and I think what’s happening is that the x-axis actually represents maximum distance to the killing; thus, for example, the points at x=3 represent all births that are up to 3 km from a killing.
Also, the difference between “significant” and “not significant” is not itself statistically significant. Thus, the following statement is misleading: “The size of this effect is substantial for exposure during the first and second trimesters. . . . The effect of exposure during the third trimester, however, is small and statistically insignificant, which is in line with previous research showing reduced effects of stressors at later stages of fetal development.” This would be ok if they were to also point out that their results are consistent with a constant effect over all trimesters.
I have a similar problem with this statement: “The size of the effect is spatially limited and decreases with distance from the event. It is small and statistically insignificant in both model specifications at around 3 km.” Again, if you want to understand how effects vary by distance, you should study that directly, not make conclusions based on statistical significance of various aggregates.
The big question, though, is do we trust the causal attribution: as stated in the article, “the assumption that in the absence of police killings, birth outcomes would have been the same for exposed and unexposed infants.” I don’t really buy this, because it seems that other bad things happen around the same time as police killings. The model includes indicators for census tracts and months, but I’m still concerned.
I recognized that my concerns are kind of open-ended. I don’t see a clear flaw in the main analysis, but I remain skeptical, both of the causal identification and of forking paths. (Yes, the above graphs show statistically-significant results for the first two trimesters for some of the distance thresholds, but had the results gone differently, I suspect it would’ve been possible to find an explanation for why it would’ve been ok to average all three trimesters. Similarly, the distance threshold allows lots of places to find statistically significant results.)
So I could see someone reading this post and reacting with frustration: the paper has no glaring flaws and I still am not convinced by its conclusion! All I can say is, I have no duty to be convinced. The paper makes a strong claim and provides some evidence—I respect that. But a statistical analysis with some statistical significance is just not as strong evidence as people have been trained to believe. We’ve just been burned too many times, and not just by the Diederik Stapels, Brian Wansinks, etc., but also by serious researchers, trying their best.
I have no problem with these findings being published. Let’s just recognize that they are speculative. It’s a report of some associations, which we can interpret in light of whatever theoretical understanding we have of causes of low birth weight. It’s not implausible that mothers behave differently in an environment of stress, whether or not we buy this particular story.
P.S. Awhile after writing this post, I received an update from Danning:
Continue reading →