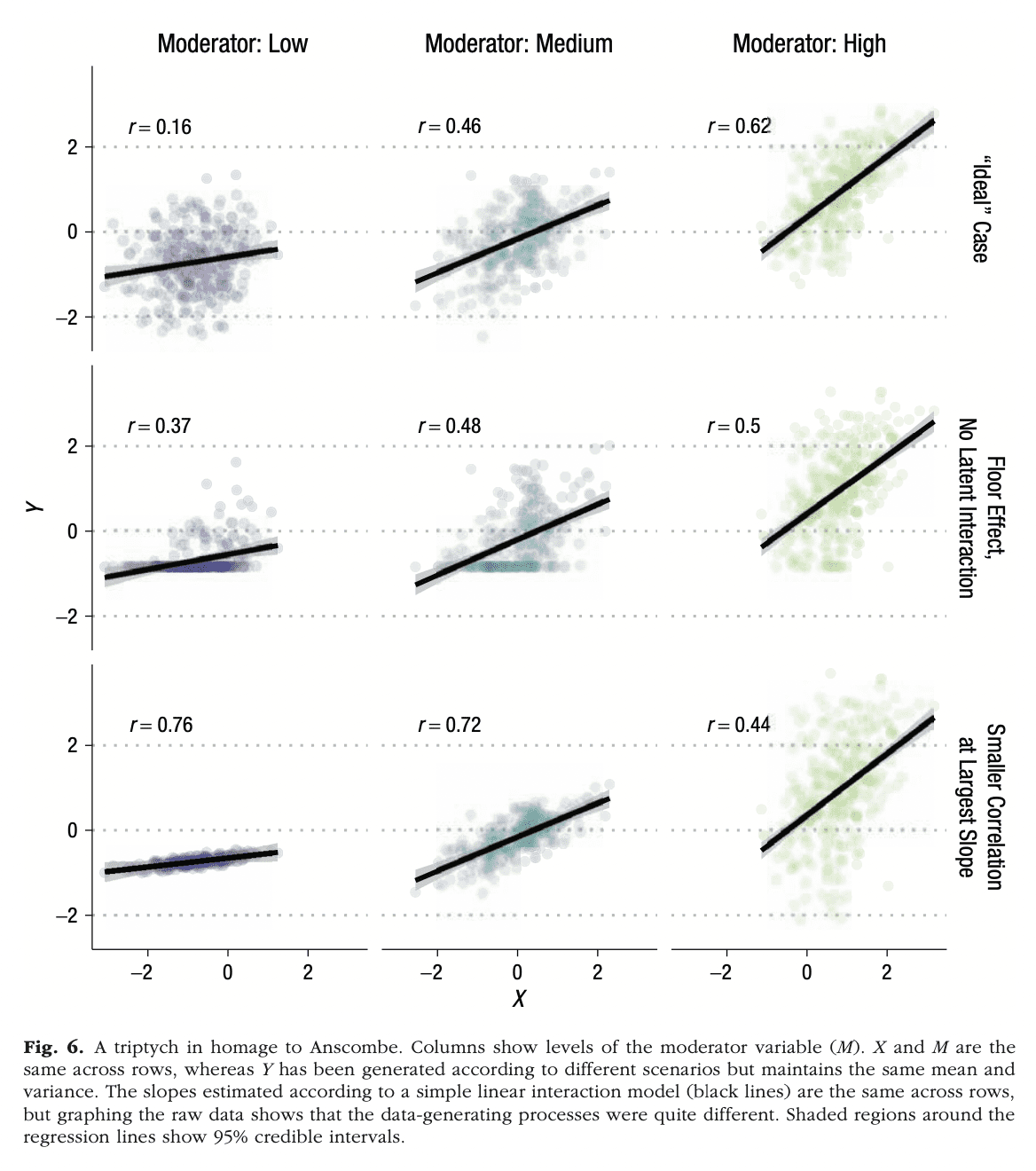
Through an old-fashioned pattern of web surfing of blogrolls (from here to here to here), I came across this post by Bret Devereaux on non-historians’ perceptions of academic history. Devereaux is responding to some particular remarks from economics journalist Noah Smith, but he also points to some more general issues, so these points seem worth discussing.
Also, I’d not previously encountered Smith’s writing on the study of history, but he recently interviewed me on the subjects of statistics and social science and science reform and causal inference so that made me curious to see what was up.
Here’s how Devereaux puts it:
Rather than focusing on converting the historical research of another field into data, historians deal directly with primary sources . . . rather than engaging in very expansive (mile wide, inch deep) studies aimed at teasing out general laws of society, historians focus very narrowly in both chronological and topical scope. It is not rare to see entire careers dedicated to the study of a single social institution in a single country for a relatively short time because that is frequently the level of granularity demanded when you are working with the actual source evidence ‘in the raw.’
Nevertheless as a discipline historians have always11 held that understanding the past is useful for understanding the present. . . . The epistemic foundation of these kinds of arguments is actually fairly simple: it rests on the notion that because humans remain relatively constant situations in the past that are similar to situations today may thus produce similar outcomes. . . . At the same time it comes with a caveat: historians avoid claiming strict predictability because our small-scale, granular studies direct so much of our attention to how contingent historical events are. Humans remain constant, but conditions, technology, culture, and a thousand other things do not. . . .
He continues:
I think it would be fair to say that historians – and this is a serious contrast with many social scientists – generally consider strong predictions of that sort impossible when applied to human affairs. Which is why, to the frustration of some, we tend to refuse to engage counter-factuals or grand narrative predictions.
And he then quotes a journalist, Matthew Yglesias, who wrote, “it’s remarkable — and honestly confusing to visitors from other fields — the extent to which historians resist explicit reasoning about causation and counterfactual analysis even while constantly saying things that clearly implicate these ideas.” Devereaux responds:
We tend to refuse to engage in counterfactual analysis because we look at the evidence and conclude that it cannot support the level of confidence we’d need to have. . . . historians are taught when making present-tense arguments to adopt a very limited kind of argument: Phenomenon A1 occurred before and it resulted in Result B, therefore as Phenomenon A2 occurs now, result B may happen. . . . The result is not a prediction but rather an acknowledgement of possibility; the historian does not offer a precise estimate of probability (in the Bayesian way) because they don’t think accurately calculating even that is possible – the ‘unknown unknowns’ (that is to say, contingent factors) overwhelm any system of assessing probability statistically.
This all makes sense to me. I just want to do one thing, which is to separate two ideas that I think are being conflated here:
1. Statistical analysis: generalizing from observed data to a larger population, a step that can arise in various settings including sampling, causal inference, prediction, and modeling of measurements.
2. Causal inference: making counterfactual statements about what would have happened, or could have happened, had some past decision been made differently, or making predictions about potential outcomes under different choices in some future decision.
Statistical analysis and causal inference are related but are not the same thing.
For example, if historians gather data on public records from some earlier period and then make inference about the distributions of people working at that time in different professions, that’s a statistical analysis but that does not involve causal inference.
From the other direction, historians can think about causal inference and use causal reasoning without formal statistical analysis or probabilistic modeling of data. Back before he became a joke and a cautionary tale of the paradox of influence, historian Niall Ferguson edited a fascinating book, Virtual History: Alternatives and Counterfactuals, a book of essays by historians on possible alternative courses of history, about which I wrote:
There have been and continue to be other books of this sort . . . but what makes the Ferguson book different is that he (and most of the other authors in his book) are fairly rigorous in only considering possible actions that the relevant historical personalities were actually considering. In the words of Ferguson’s introduction: “We shall consider as plausible or probable only those alternatives which we can show on the basis of contemporary evidence that contemporaries actually considered.”
I like this idea because it is a potentially rigorous extension of the now-standard “Rubin model” of causal inference.
As Ferguson puts it,
Firstly, it is a logical necessity when asking questions about causality to pose ‘but for’ questions, and to try to imagine what would have happened if our supposed cause had been absent.
And the extension to historical reasoning is not trivial, because it requires examination of actual historical records in order to assess which alternatives are historically reasonable. . . . to the best of their abilities, Ferguson et al. are not just telling stories; they are going through the documents and considering the possible other courses of action that had been considered during the historical events being considered. In addition to being cool, this is a rediscovery and extension of statistical ideas of causal inference to a new field of inquiry.
See also here. The point is that it was possible for Ferguson et al. to do formal causal reasoning, or at least consider the possibility of doing it, without performing statistical analysis (thus avoiding the concern that Devereaux raises about weak evidence in comparative historical studies).
Now let’s get back to Devereaux, who writes:
This historian’s approach [to avoid probabilistic reasoning about causality] holds significant advantages. By treating individual examples in something closer to the full complexity (in as much as the format will allow) rather than flattening them into data, they can offer context both to the past event and the current one. What elements of the past event – including elements that are difficult or even impossible to quantify – are like the current one? Which are unlike? How did it make people then feel and so how might it make me feel now? These are valid and useful questions which the historian’s approach can speak to, if not answer, and serve as good examples of how the quantitative or ’empirical’ approaches that Smith insists on are not, in fact, the sum of knowledge or required to make a useful and intellectually rigorous contribution to public debate.
That’s a good point. I still think that statistical analysis can be valuable, even with very speculative sampling and data models, but I agree that purely qualitative analysis is also an important part of how we learn from data. Again, this is orthogonal to the question of when we choose to engage in causal reasoning. There’s no reason for bad data to stop us from thinking causally; rather, the limitations in our data merely restrict the strengths of any causal conclusions we might draw.
The small-N problem
One other thing. Devereaux refers to the challenges of statistical inference: “we look at the evidence and conclude that it cannot support the level of confidence we’d need to have. . . .” That’s not just a problem with the field of history! It also arises in political science and economics, where we don’t have a lot of national elections or civil wars or depressions, so generalizations necessarily rely on strong assumptions. Even if you can produce a large dataset with thousands of elections or hundreds of wars or dozens of business cycles, any modeling will implicitly rely on some assumption of stability of a process over time, and assumption that won’t necessarily make sense given changes in political and economic systems.
So it’s not really history versus social sciences. Rather, I think of history as one of the social sciences (as in my book with Jeronimo from a few years back), and they all have this problem.
The controversy
After writing all the above, I clicked through the link and read the post by Smith that Devereaux was arguing.
And here’s the funny thing. I found Devereaux’s post to be very reasonable. Then I read Smith’s post, and I found that to be very reasonable too.
The two guys are arguing against each other furiously, but I agree with both of them!
What gives?
As discussed above, I think Devereaux in his post provides an excellent discussion of the limits of historical inquiry. On the other side, I take the main message of Smith’s post to be that, to the extent that historians want to use their expertise to make claims about the possible effects of recent or new policies, they should think seriously about statistical inference issues. Smith doesn’t just criticizes historians here; he leads off by criticizing academic economists:
After having endured several years of education in that field, I [Smith] was exasperated with the way unrealistic theories became conventional wisdom and even won Nobel prizes while refusing to submit themselves to rigorous empirical testing. . . . Though I never studied history, when I saw the way that some professional historians applied their academic knowledge to public commentary, I started to recognize some of the same problems I had encountered in macroeconomics. . . . This is not a blanket criticism of the history profession . . . All I am saying is that we ought to think about historians’ theories with the same empirically grounded skepticism with which we ought to regard the mathematized models of macroeconomics.
By saying that I found both Devereaux and Smith to be reasonable, I’m not claiming they have no disagreements. I think their main differences come because they’re focusing on two different things. Smith’s post is ultimately about public communication and the things that academic say in the public discourse (things like newspaper op-eds and twitter posts) with relevance to current political disputes. And, for that, we need to consider the steps, implicit or explicit, that commentators take to go from their expertise to the policy claims they make. Devereaux is mostly writing about academic historians in their professional roles. With rare exceptions, academic history is about getting the details right, and even popular books of history typically focus on what happened, and our uncertainty about what happened, not on larger theories.
I guess I do disagree with this statement from Smith:
The theories [from academic history] are given even more credence than macroeconomics even though they’re even less empirically testable. I spent years getting mad at macroeconomics for spinning theories that were politically influential and basically un-testable, then I discovered that theories about history are even more politically influential and even less testable.
Regarding the “less testable” part, I guess it depends on the theories—but, sure, many theories about what have happened in the past can be essentially impossible to test, if conditions have changed enough. That’s unavoidable. As Devereaux replies, this is not a problem with the study of history; it’s just the way things are.
But I can’t see how Smith could claim with a straight face that theories from academic history are “given more credence” and are “more politically influential” than macroeconomics. The president has a council of economic advisers, there are economists at all levels of the government, or if you want to talk about the news media there are economists such as Krugman, Summers, Stiglitz, etc. . . . sure, they don’t always get what they want when it comes to policy, but they’re quoted endlessly and given lots of credence. This is also the case in narrower areas, for example James Heckman on education policy or Angus Deaton on deaths of despair: these economists get tons of credence in the news media. There are no academic historians with that sort of influence. This has come up before: I’d say that economics now is comparable to Freudian psychology in the 1950s in its influence on our culture:
My best analogy to economics exceptionalism is Freudianism in the 1950s: Back then, Freudian psychiatrists were on the top of the world. Not only were they well paid, well respected, and secure in their theoretical foundations, they were also at the center of many important conversations. Even those people who disagreed with them felt the need to explain why the Freudians were wrong. Freudian ideas were essential, leaders in that field were national authorities, and students of Freudian theory and methods could feel that they were initiates in a grand tradition, a priesthood if you will. Freudians felt that, unlike just about everybody else, they treated human beings scientifically and dispassionately. What’s more, Freudians prided themselves on their boldness, their willingness to go beyond taboos to get to the essential truths of human nature. Sound familiar?
When it comes to influence in policy or culture or media, academic history doesn’t even come close to Freudianism in the 1950s or economics in recent decades.
This is not to say we should let historians off the hook when they make causal claims or policy recommendations. We shouldn’t let anyone off the hook. In that spirit, I appreciate Smith’s reminder of the limits of historical theories, along with Devereaux’s clarification of what historians really do when they’re doing academic history (as opposed to when they’re slinging around on twitter).
Why write about this at all?
As a statistician and political scientist, I’m interested in issues of generalization from academic research to policy recommendations. Even in the absence of any connection with academic research, people will spin general theories—and one problem with academic research is that it can give researchers, journalists, and policymakers undue confidence in bad theories. Consider, for example, the examples of junk science promoted over the years by the Freakonomics franchise. So I think these sorts of discussions are important.