Well can we at least make it look easy?
For the model as given here, there are two parameters Pc and Pt – but the focus of interest will be on some parameter representing a treatment effect
– Andrew chose Pt – Pc.
But sticking for a while with Pt and Pc – the prior is a surface over Pt and Pc as is the data model (likelihood)
In particular, the prior is a flat surface (independent uniforms)
and the likelihood is Pt^1 (1 – Pt)^29 * Pc^3 (1 – Pc)^7 (the * is from independence)
(If I reversed the treatment and control groups – I should be blinded to that anyways)
Since the posterior is proportional to prior * likelihood we take logs and suggest plotting 3 surfaces LogPrior, Loglikelihood, and LogPosterior (i.e. LogPrior + LogLikelihood)
– along with a tracing out of a region of highest posterior probability or some simple approximation of that.
This shows all inference pieces and their sum (summative inference) in this problem.
If researchers could think in clearly in two dimensions we would be done.
Regardless the convention is to think in one dimension so …
Transform Pt and Pc into (Pt-Pc) and Pc; and then focus on just (Pt-Pc)
– now just a curve.
This is (formally) easy to do with the posterior (integrate out Pc from the surface to get a curve for just (Pt-Pc)).
Andrew’s simple method, I believe depends on (knowing) the quadratic curve centered at (Pt-Pc) with curvature = -1/(Pt * (1-Pt)/nt + Pc * (1-Pc)/nc) in the (Pt-Pc) axis but constant in the Pc axis
– approximates the poserior surface well as does going down two units from the maximum to get an interval.
Maybe not all statisticians will immediately get this – on first look.
But it would be nice to still show the pieces and how they add in one dimension.
Fortunately in most Bayesian analyses, this is (formally) possible with no loss (see this paper)
– any posterior curve for a parameter of focus (obtained by integrating out the other parameters from the surface) can be rewritten as
Integrated posterior ~ Integrated prior + Integrated likelihood
The technical problem that arises here is getting the integrated likelihood where the integration has to be done with respect to the prior assumed
(sometime this does not exist but with modifying the prior so that it does – actually doing the integration to get a curve can be very difficult)
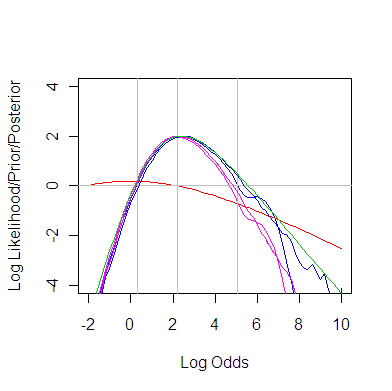
For this problem, using priors and elegant math from here and brute force numerical integration, we can show all inference pieces and their sum in one dimension for the log odds ratio parameterization for treatment effect.
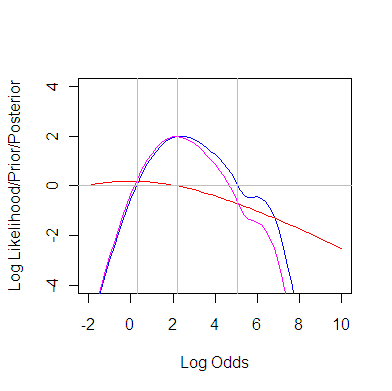
The graph shows the LogPrior (red), LogIntegratedLikelhood (blue) and their sum the LogPosterior (purple) – just for the log odds ratio. Also a green curve for later. Their maximums have been arbitrarily set to 2 so that the horizontal line at 0 provides approximate credible interval.
plot2.pdf
Sorry I have yet to try this for (Pt-Pc) – probably doable by brute force – but log odds is a very convenient parameterization.
Now lets compare and contrast with the frequency approach.
In principle, the same integrated likelihood could be used – now just erase the LogPrior and LogPosterior. Then you go down about 2 units from the maximum of the LogLikelihood to get a approximate 95% confidence interval.
(Yes getting this just right, going down just the right distance and perhaps deviating the horizontal line from 0 degrees – such that it would have 95% coverage and this coverage is a constant function accross Pt and Pc is mathematically impossible but within any reasonable model uncertainty you can usually get close enough and always >= 95%)
The least wrong likelihood – that is just a function of log odds ratio – for this problem is the conditional likelihood (same math that gives the Fisher’s Exact test) and I should add that to the plot (it is not hard but not at hand right now)
The more general though a bit wronger approximation to the least wrong likelihood is the profile likelihood
– for each value of log odds ratio replace the unknown Pc with the mle for it and treat it as known. This traces out the peak over the surface in log odds direction and its known to approximate the conditional likelihood quite well. It is what drives logistic regression software and the _default_ in frequency based modelling.
That is added as the green curve in the plot above. It fails in the paired data case i.e. Neyman-Scott problems but otherwise works fairly generally.
Hopefully this shows why credible and confidence intervals will be very similar – in this problem. Both intervals mostly come from the blue/green curve (where they intersect the horizontal line).
This is a real simple problem – binary outcomes, two groups and randomized. Explaining this to people with little training is statistics – something I need to do soon – will likely be challenging.
Whats nice about the Bayesian approach here is that it can be displayed just using curves – for any parameter / parameterization one wants to focus on
– always using the same method. But there is actually no need to obtain the curves, one can grab a sample from the posterior surface and extract the posterior curve one wants to focus on.
On the other hand, one could use the profile likelihood in leu of the integrated likelihoods to get a approximate display – the error of thie approximation would show up in the difference between the extracted from the posterior surface log curve with the (marginal) LogPrior + LogProfileLikelhood curve.
But its also nice to show that the credible interval mostly comes from the peices that also provide confidence intervals and hence the confidence coverage should be pretty good (or maybe even better as in this example – Mossman, D. and Berger, J. (2001). Intervals for post-test probabilities: a comparison of five methods. Medical Decision Making 21, 498-507.)
Summary of an easy stats problem
Bayes: Grab posterior sample and marginalize to parameter of focus
Frequency: Marginalize the likelihood surface to something that is just a function of the parameter of focus – and do extensive math or simulation to get and prove its a confidence interval
Easy if both intervals mostly come from a log likelihood?
Question: Why don’t we give these picturesque descriptions of the workings of statistics to others?
K