My own view is that the death penalty makes sense in some settings and not others. To say that “a serious commitment to the sanctity of human life may well compel” the death penalty . . . jeez, I dunno, that’s some real Inquisition-level thinking going on. Not just supporting capital punishment, they’re compelling it. That’s a real edgelord attitude, kinda like the thought-provoking professor in your freshman ethics class who argues that companies have not just the right but the moral responsibility to pollute the maximum amount possible under the law because otherwise they’re ducking their fiduciary responsibility to the shareholders. Indeed, it’s arguably immoral to not pollute beyond the limits of the law if the expected gain from polluting is lower than the expected loss from getting caught and fined.
Sunstein and Vermeule also recommended that the government should fight conspiracy theories by engaging in “cognitive infiltration of extremist groups,” which seemed pretty rich, considering that Vermeule spent his online leisure hours after the 2020 election promoting election conspiracy theories. Talk about the fox guarding the henhouse. This is one guy I would not trust to be in charge of government efforts to cognitively infiltrate extremist groups!
Meanwhile, these guys go on NPR, they’ve held appointive positions with the U.S. government, they’re buddies with elite legal academics . . . it bothers me! I’m not saying their free speech should be suppressed—we got some Marxists running around in this country too—I just don’t want them anywhere near the levers of power.
Anyway, I heard by email from someone who knows Sunstein and Vermeuele. It seems that both of them are nice guys, and when they stick to legal work and stay away from social science or politics they’re excellent scholars. My correspondent also wrote:
– Regarding the disjunction between Vermeule’s scholarly competence and nice-guyness, on one hand, and his extreme political views: I can offer a statistical or population perspective. Think of a Venn diagram where the two circles are “reasonable person” and “extreme political views and actions.” (I’m adding “actions” here to recognize that the issue is not just that Vermeule thinks that a fascist takeover would be cool, but that he’s willing to sell out his intellectual integrity for it, in the sense of endorsing ridiculous claims.)
From an ethical point of view, there’s an argument in favor of selling out one’s intellectual integrity for political goals. One can make this argument for Vermeule or also for, say, Ted Cruz. The argument is that the larger goal (a fascist government in the U.S., or more power for Ted Cruz) is important enough that it’s worth making such a sacrifice. Or, to take slightly lesser examples, the argument would be that when Hillary Clinton lied about her plane being shot at, or when Donald Trump lied about . . . ok, just about everything, that they were thinking about larger goals. Indeed, one could argue that for Cruz and the other politicians, it’s not such a big deal—nobody expects politicians to believe half of what they’re saying anyway—but for Vermeule to trash his reputation in this way, that shows real commitment!
Actually, I’m guessing that Vermeule was just spending too much time online in a political bubble, and he didn’t really think that endorsing these stupid voter-fraud claims meant anything. To put it another way, you and I think that endorsing unsubstantiated claims of voting fraud is bad for two reasons: (1) intellectually it’s dishonest to claim evidence for X when you have no evidence for X, (2) this sort of thing is dangerous in the short term by supplying support to traitors, and (3) it’s dangerous in the long term by degrading the democratic process. But, for Vermeule, #2 and #3 might well be a plus not a minus, and, as for #1, I think it’s not uncommon for people to make a division between their professional and non-professional statements, and to have a higher standard for the former than the latter. Vermeule might well think, “Hey, that’s just twitter, it’s not real.” Similarly, the economist Steven Levitt and his colleagues wrote all sorts of stupid things (along with many smart things) under the Freakonomics banner, thinks which I guess (or, should I say, hope) he’d never have done in his capacity as an academic. Just to be clear, I’m not saying that everyone does this, indeed I don’t think I do it—I stand by what I blog, just as I stand by my articles and books—but I don’t think everyone does. Another example that’s kinda famous is biologists who don’t believe in evolution. They can just separate the different parts of their belief systems.
Anyway, back to the Venn diagram. The point is that something like 30% of Americans believe this election fraud crap. 30% of Americans won’t translate into 30% of competent and nice-guy law professors, but it won’t be zero, either. Even if it’s only 10% or less in that Venn overlap, it won’t be zero. And the people inside that overlap will get attention. And some of them like the attention! So at that point you can get people going further and further off the deep end.
If it would help, you could think of this as a 2-dimensional scatterplot rather than a Venn diagram, and in this case you can picture the points drifting off to the extreme over time.
To look at this another way, consider various well-respected people in U.S. and Britain who were communists in the 1930s through 1950s. Some of these people were scientists! And they said lots of stupid things. From a political perspective, that’s all understandable: even if they didn’t personally want to tear up families, murder political opponents, start wars, etc., they could make the case that Stalin’s USSR was a counterweight to fascism elsewhere. But from an intellectual perspective, they wouldn’t always make that sort of minimalist case. Some of them were real Soviet cheerleaders. Again, who knows what moral calculations they were making in their heads.
I’m not gonna go all Sunstein-level contrarian and argue that selling out one’s intellectual integrity is the ultimate moral sacrifice—I’m picturing a cartoon where Vermeule is Abraham, his reputation is Isaac, and the Lord is thundering above, booming down at him to just do it already—but I guess the case could be made, indeed maybe will be the subject of one of the 8 books that Sunstein comes out with next year and is respectfully reviewed on NPR etc.
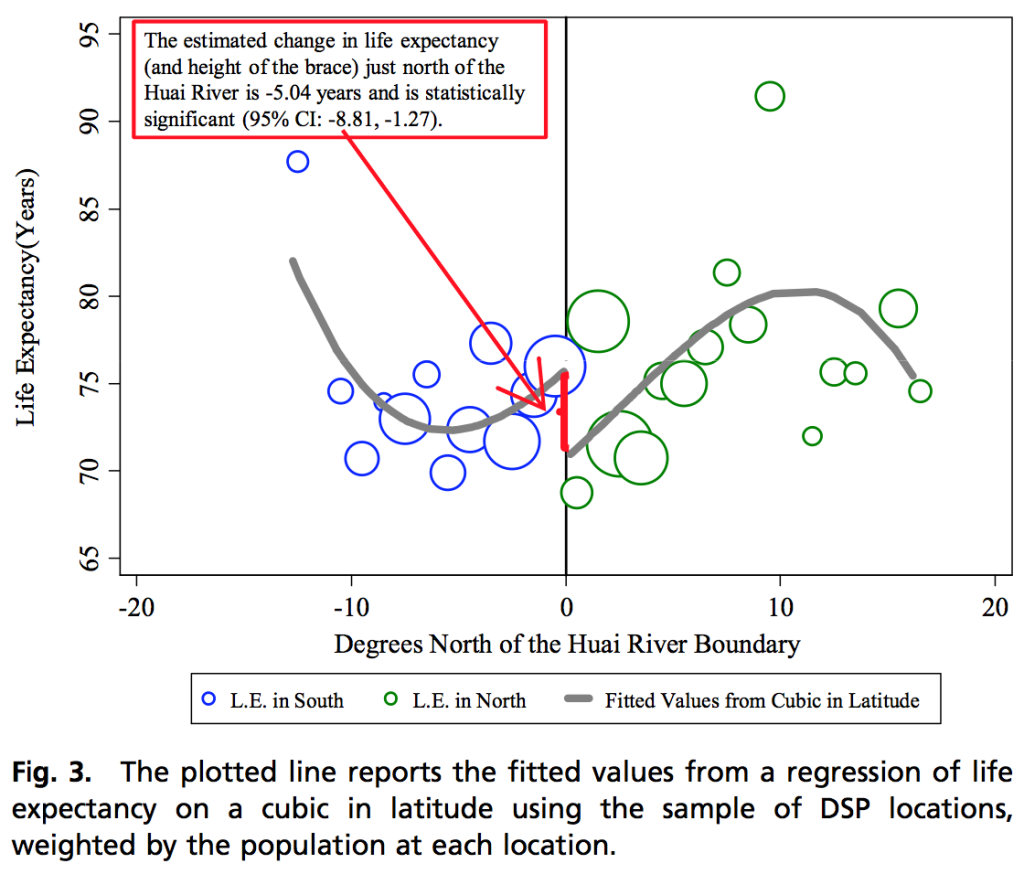
– Regarding the capital punishment article: I have three problems here. The first is their uncritical acceptance of a pretty dramatic claim. In Sunstein and Vermeule’s defense, though, back in 2005 it was standard in social science for people to think that statistical significance + identification strategy + SSRN or NBER = discovery. Indeed, I’d guess that most academic economists still think that way! So to chide them on their innumeracy here would be a bit . . . anachronistic, I guess. The second problem is that I’m guessing they were so eager to accept this finding is that it allowed them to make this cool point that they wanted to make. If they’d said, “Here’s a claim, maybe it’s iffy but if it’s true, it has some interesting ethical implications…”, that would be one thing. But that’s not what I read their paper as saying. By saying “Recent evidence suggests that capital punishment may have a significant deterrent effect” and not considering the opposite, they’re making the fallacy of the one-way bet. My third problem is that I think their argument is crap, even setting aside the statistical study. I discussed this a bit in my post. There are two big issues they’re ignoring. The first is that if each execution saves 18 lives, then maybe we should start executing innocent people! Or, hey, we can find some guilty people to execute, maybe some second-degree murderers, armed robbers, arsonists, tax evaders, speeders, jaywalkers, . . . . shouldn’t be too hard to find some more targets–after all, they used to have the death penalty for forgery. Just execute a few hundred of them and consider how many lives will be saved. That may sound silly to you, but it’s Sunstein and Vermeule, not me, who wrote that bit about “a serious commitment to the sanctity of human life.” I discussed the challenges here in more detail in a 2006 post; see the section, “The death penalty as a decision-analysis problem?” My point is not that they have to agree with me, just that it’s not a good sign that their long-ass law article with its thundering about “the sanctity of human life” is more shallow than two paragraphs of a blog post.
In summary regarding the death-penalty article, I’m not slamming them for falling for crappy research (that’s what social scientists and journalists did back in 2005, and lots of them still to do this day) and I’m not slamming them for supporting death penalty (I’ve supported it too, at various times in my life; more generally I think it depends on the situation and that the death penalty can be a good idea in some circumstances, even if the current version in the U.S. doesn’t work so well). I’m slamming them for taking half-assed reasoning and presenting it as sophisticated. I’d say they don’t know better, they’re just kinda dumb—but you assure me that Vermeule is actually smart. So my take on it is that they’re really good at playing the academic game. For me to criticize their too-clever-by-half “law and economics” article as not being well thought through, that would be like criticizing LeBron James for not being a golf champion. They do what’s demanded of them in their job.
– Regarding Sunstein’s ability to learn from error: Yes, I mention in my post that Sunstein was persuaded by the article by Wolfers and Donohue. I do think it was good that Sunstein retracted his earlier stance. That’s one reason I was particularly disappointed by what he and his collaborator did in the second edition of Nudge, which was to memory-hole the Wansink episode. It was such a great opportunity in the revision, for them to have said that the nudge idea is so compelling that they (and many others) were fooled, and to consider the implications: in a world where people are rewarded for discovering apparently successful nudges, the Wansinks of the world will prosper, at least in the short term. Indeed, Sunstein and Thaler could’ve even put a positive spin on it by talking about the self-correcting nature of science, sunlight is the best disinfectant, etc. But, no, instead they remove it entirely, and then Sunstein returns to his previous credulous self by posting something on what he called the “coolest behavioral finding of 2019.” Earlier they’d referred to Wansink as having had multiple masterpieces. Kind of makes you question their judgment, no? My take on this is . . . for them, everyone’s a friend, so why rock the boat? As I wrote, it looks to me like an alliance of celebrities. I’m guessing that they are genuinely baffled by people like Uri Simonsohn or me who criticize this stuff: Don’t we have anything better to do? It’s natural to think of behavior of Simonsohn, me, and other “data thugs” as being kinda pathological: we are jealous, or haters, or glory-seekers, or we just have some compulsion to be mean (the kind of people who, in another life, would be Stasi).
– Regarding the Stasi quote: Yes, I agree it’s a good thing Sunstein retracted it. I was not thrilled that in the retraction he said he’d thought it had “a grain of truth,” but, yeah, as retractions go, it was much better than average! Much better than the person who called people “terrorists,” never retracted or apologized, then later published an article lying about a couple of us (a very annoying episode to me, which I have to kind of keep quiet about cos nobody likes a complainer, but grrrr it burns me up, that people can just lie in public like that and get away with it). So, yes, for sure, next time I write about this I will emphasize that he retracted the Stasi line.
– Libertarian paternalism: There’s too much on this for one email, but for my basic take, see this post, in particular the section “Several problems with science reporting, all in one place.” This captures it: Sunstein is all too willing to think that ordinary people are wrong, while trusting the testimony of Wansink, who appears to have been a serial fabricator. It’s part of a world in which normies are stupidly going about their lives doing stupid things, and thank goodness (or, maybe I should say in deference to Vermeule, thank God) there are leaders like Sunstein, Vermeule, and Wansink around to save us from ourselves, and also in the meantime go on NPR, pat each other on the back on Twitter, and enlist the U.S. government in their worthy schemes.
– People are complicated: Vermeule and Sunstein are not “good guys” or “bad guys”; they’re just people. People are complicated. What makes me sad about Sunstein is that, as you said, he does care about evidence, he can learn from error. But then he chooses not to. He chooses to stay in his celebrity comfort zone, making stupid arguments evaluating the president’s job performance based on the stock market, cheerleading biased studies about nudges as if they represent reality. See the last three paragraphs here. Another bad thing Sunstein did recently was to coauthor that Noise book. Another alliance of celebrities! (As a side note, I’m sad to see the collection of academic all-star endorsements that this book received.) Regarding Sunstein himself, see the section “A new continent?” of that post. As I wrote at the time, if you’re going to explore a new continent, it can help to have a local guide who can show you the territory.
Vermeule I know less about; my take is that he’s playing the politics game. He thinks that on balance the Republicans are better than the Democrats, and I’m guessing that when he promotes election fraud misinformation, that he just thinks he’s being mischievous and cute. After all, the Democrats promoted misinformation about police shootings or whatever, so why can’t he have his fun? And, in any case, election security is important, right? Etc etc etc. Anyone with a bit of debate-team experience can justify lots worse than Vermeule’s post-election tweets. I guess they’re not extreme enough for Sunstein to want to stop working with him.
– Other work by Vermeule and Sunstein: They’re well-respected academics, also you and others say how smart they are, so I can well believe they’ve also done high-quality work. It might be that their success in some subfields led them into a false belief that they know what they’re doing in other areas (such as psychology research, statistics, and election administration) where they have no expertise. As the saying goes, sometimes it’s important to know what you don’t know.
My larger concern, perhaps, is that these people get such deference in academia and the news media, that they start to believe their own hype and they think they’re experts in everything.
– Conspiracy theories: Sunstein and Vermeule wrote, “Many millions of people hold conspiracy theories; they believe that powerful people have worked together in order to withhold the truth about some important practice or some terrible event. A recent example is the belief, widespread in some parts of the world, that the attacks of 9/11 were carried out not by Al Qaeda, but by Israel or the United States.” My point here is that there are two conspiracy theories here: a false conspiracy theory that the attacks were carried out by Israel or the United States, and a true conspiracy theory that the attacks were carried out by Al Qaeda. In the meantime, Vermeule has lent his support to unsupported conspiracy theories regarding the 2020 election. So Vermeule is incoherent. On one hand, he’s saying that conspiracy theories are a bad thing. On the other hand, in one place he’s not recognizing the existence of true conspiracies; in another place he’s supporting ridiculous and dangerous conspiracy theories, I assume on the basis that they are in support of his political allies. I don’t think it’s a cheap shot to point out this incoherence.
And what the does it mean that Sunstein thinks that “Because those who hold conspiracy theories typically suffer from a ‘crippled epistemology,’ in accordance with which it is rational to hold such theories, the best response consists in cognitive infiltration of extremist groups.”—but he continues to work with Vermeule? Who would want to collaborate with someone who suffers from a crippled epistemology (whatever that means)? The whole thing is hard for me to interpret except as an elitist position where some people such as Sunstein and Vermeule are allowed to believe whatever they want, and hold government positions, while other people get “cognitively infiltrated.”
– The proposed government program: I see your point that when the government is infiltrating dangerous extremist groups, it could make sense for them to try to talk some of these people out of their extremism. After all, for reasons of public safety the FBI and local police are already doing lots of infiltration anyway—they hardly needed Sunstein and Vermeule’s encouragement. Overall I suspect it’s a good thing that the cops are gathering intelligence this way rather than just letting these groups make plans in secret, set off bombs, etc., and once the agents are on the inside, I’d rather have them counsel moderation than do that entrapment thing where they try to talk people into planning crimes so as to be able to get more arrests.
I think what bothers me about the Sunstein and Vermeule article—beyond that they’re worried about conspiracy theories while themselves promoting various con artists and manipulators—is in their assumption that the government is on the side of the good. Perhaps this is related to Sunstein being pals with Kissinger. I labeled Sunstein and Vermeuele as libertarian paternalists, but maybe Vermuele is better described as an authoritarian; in any case they seem to have the presumption that the government is on their side, whether it’s for nudging people to do good things (not to do bad things) or for defusing conspiracy theories (not to support conspiracy theories).
But governments can’t always be trusted. When I wrote, “They don’t even seem to consider a third option, which is the government actively promoting conspiracy theories,” it’s not that I was saying that this third option was a good thing! Rather, I was saying that the third option is something that’s actually done, and I gave examples of the U.S. executive branch and much of Congress in the period Nov 2020 – Jan 2021, and the Russian government in their invasion of Ukraine.” And it seems that Vermeule may well be cool with both these things! So my reaction to Vermeule saying the government should be engaging in information warfare is similar to my reaction when the government proposed to start a terrorism-futures program and have it be run by an actual terrorist: it might be a good idea in theory and even in practice, but (a) these are not the guys I would want in charge of such a program, and (b) their enthusiasm for it makes me suspicious.
– Unrelated to all the above: You say of Vermeule, “after his conversion to Catholicism, he adopted the Church’s line on moral opposition to capital punishment.” That’s funny because I thought the Catholic church was cool with the death penalty—they did the inquisition, right?? Don’t tell me they’ve flip-flopped! Once they start giving into the liberals on the death-penalty issue, all hell will break loose.
1. The mix of social science, statistical evidence, and politics is interesting and important.
2. As an academic, I’m always interested in academics behaving badly, especially when it involves statistics or social science in some way. In particular, the idea that these guys are supposed to be so smart and so nice in regular life, and then they go with these not-so-smart, not-so-nice theories, that’s interesting. When mean, dumb people promote mean, dumb ideas, that’s not so interesting. But when nice, smart people do it . . .
3. It’s been unfair to Sunstein for me to keep bringing up that Stasi thing.
Regarding item 2, one analogy I can see with Vermeule endorsing stupid and dangerous election-fraud claims is dudes in the 60s wearing Che T-shirts and thinking Chairman Mao was cool. From one perspective, Che was one screwed-up dude and Mao was one of history’s greatest monsters . . . but both of them were bad-ass dudes and it was cool to give the finger to the Man. Similarly, Vermeule could well think of Trump as badass, and he probably thinks its hilarious to endorse B.S. claims that support his politics. Kinda like how Steven Levitt probably thinks he’s a charming mischievous imp by supporting climate denialists. Levitt would not personally want his (hypothetical) beach house on Fiji to be flooded, but, for a certain kind of person, it’s fun to be a rogue.