Dean Eckles writes:
You might find this paper interesting:
We find a pronounced “hockey stick” pattern: Over the past two decades the textual analogs of cognitive distortions surged well above historical levels, including those of World War I and II, after declining or stabilizing for most of the 20th century.
This is based on Google Books n-gram data, but apparently without much concern for changes in the composition of this corpus over time. This is pointed out by, among others, Ben Schmidt.
The paper discusses some of these problems (“Sampling effects” section), but seems to think that there isn’t a recent increase in fiction (and so posits that any bias would be in the opposite direction). My intuition would be that the effects of interest have to be small compared with the various other factors we would expect to change language use over this period in a corpus with dramatically changing composition.
Also seems like a good example of measurement challenges and their relationship to causal inference for that matter.
Here’s Schmidt’s reaction:
This PNAS article claiming to find a world-wide outbreak of depression since 2000 is shockingly bad. The authors don’t bother to understand the 2019 Google Books “corpus” a tiny bit; everything they find is explained by Google ingesting different books.
The PNAS article in question begins:
Can entire societies become more or less depressed over time?
But they don’t really have any measure of entire societies or depression. The above note by Schmidt discusses why the Google books collection cannot be characterized as a measure of entire societies. There are also problems with the depression measurement. Here’s what it says in the PNAS article:
For example, the 3-gram “I am a” captures a labeling and mislabeling distortion, regardless of its context or the precise labeling involved (“lady,” “honorable person,” “loser,” etc.). These same n-grams were in earlier research shown to be significantly more prevalent in the language of individuals with depression vs. a random sample (17).
Note 17 points to this preprint, which states:
Here, we show that individuals with a self-reported diagnosis of depression on social media express higher levels of distorted thinking than a random sample.
How do they define “distorted thinking”?
[W]e define a clinical lexicon of 241 n-grams that a panel of clinical psychologists deemed to form a schema involved in the expression of a particular type of distorted thinking according to CBT theory and practice. For example, “I will never” would be implicated in the expression of a cognitive distortions such as Catastrophizing or Fortune-telling, whereas “I am a _” would be used to express a Labeling and Mislabeling distortion.
This is like a parody of clinical psychology, reminiscent of those sitcom moments when the busy suburban dad is persuaded to go to a shrink, and everything he says on the couch is interpreted as some sort of neurosis. Only this case, instead of everything being a coded statement about his mother, everything’s a coded statement about a cognitive distortion. “I am a statistician.” “There you go with those Labeling and Mislabeling distortions again!”
There’s a lot of complicated stuff in that linked preprint and I haven’t tried to untangle their statistical analysis. Let me just say that they are making the classic fallacy of measurement of labeling a measurement as X and then writing as if they’ve observed X itself. Just because two things are correlated, it doesn’t mean they can be considered as being the same thing.
To get back to the preprint, no, they offer no evidence of “distorted thinking.” And, to get back to the PNAS article, no, the 3-gram “I am a” does not “capture” a labeling and mislabeling distortion. Or we could take even one more step back to the title of the PNAS article, which states:
Historical language records reveal a surge of cognitive distortions in recent decades
But, as noted above, the paper offers no evidence on cognitive distortions. All this is in addition to any problems with the historical language records.
As Eckles notes, the paper does include a section on limitations, which if taken seriously would require major changes to the article:
We caution that although the Google Books data have been widely used to assess cultural and linguistic shifts, and they are one of the largest records of historical literature, it remains uncertain whether CDS prevalence truly reflects changes in societal language and societal wellbeing. Many books included in the Google Books sample were published at times or locations marked by reduced freedom of expression, widespread propaganda, social stigma, and cultural as well as socioeconomic inequities that may reduce access to the literature, potentially reducing its ability to reflect societal changes. Although CDS n-gram prevalence was shown to be higher in individuals with depression (17) and our composition of CDS n-grams closely follows the framework of cognitive distortions established by Beck (9), they do not constitute an individual diagnostic criterion with respect to authors, readers, and the general public. It is also not clear whether the mental health status of authors provides a true reflection of societal changes nor whether cultural changes may have taken place that altered the association between mental health, cognitive distortions, and their expression in language.
But then they basically ignore these concerns! On one hand, deep in the article, “it remains uncertain whether CDS prevalence truly reflects changes in societal language and societal wellbeing.” On the other had, in the title, “Historical language records reveal a surge of cognitive distortions in recent decades.” A big contradiction!
Social science is difficult. I do survey research, where response rates are well below 10%, but that doesn’t stop us from making strong claims about public opinion. We have to do our best with the data we have, while recognizing our limitations. Here, though, I think the gaps between data and substantive claims are just too much. That’s just my take (and that of Eckles and Schmidt); you can have your own. What bothers me here is the leap from data to underlying constructs of interest that we see in the title, abstract, and claims of the paper.
There are millions of crappy research papers published each year, many that are much worse than this one. The attention came here because the article was published in the Proceedings of the National Academy of Sciences, which I’ve heard publishes good stuff sometimes, when they’re not publishing bogus papers on himmicanes, air rage, and, my personal favorite, ages ending in 9. Papers in the Proceedings of the National Academy of Sciences get attention! The good news is that in this case the attention seems mostly to have been negative.
Student research projects
The general structure of this “Historical language records” project got me thinking. There are enough data sources out there that it seems that all sorts of interesting things could be learned with time trends.
For example:
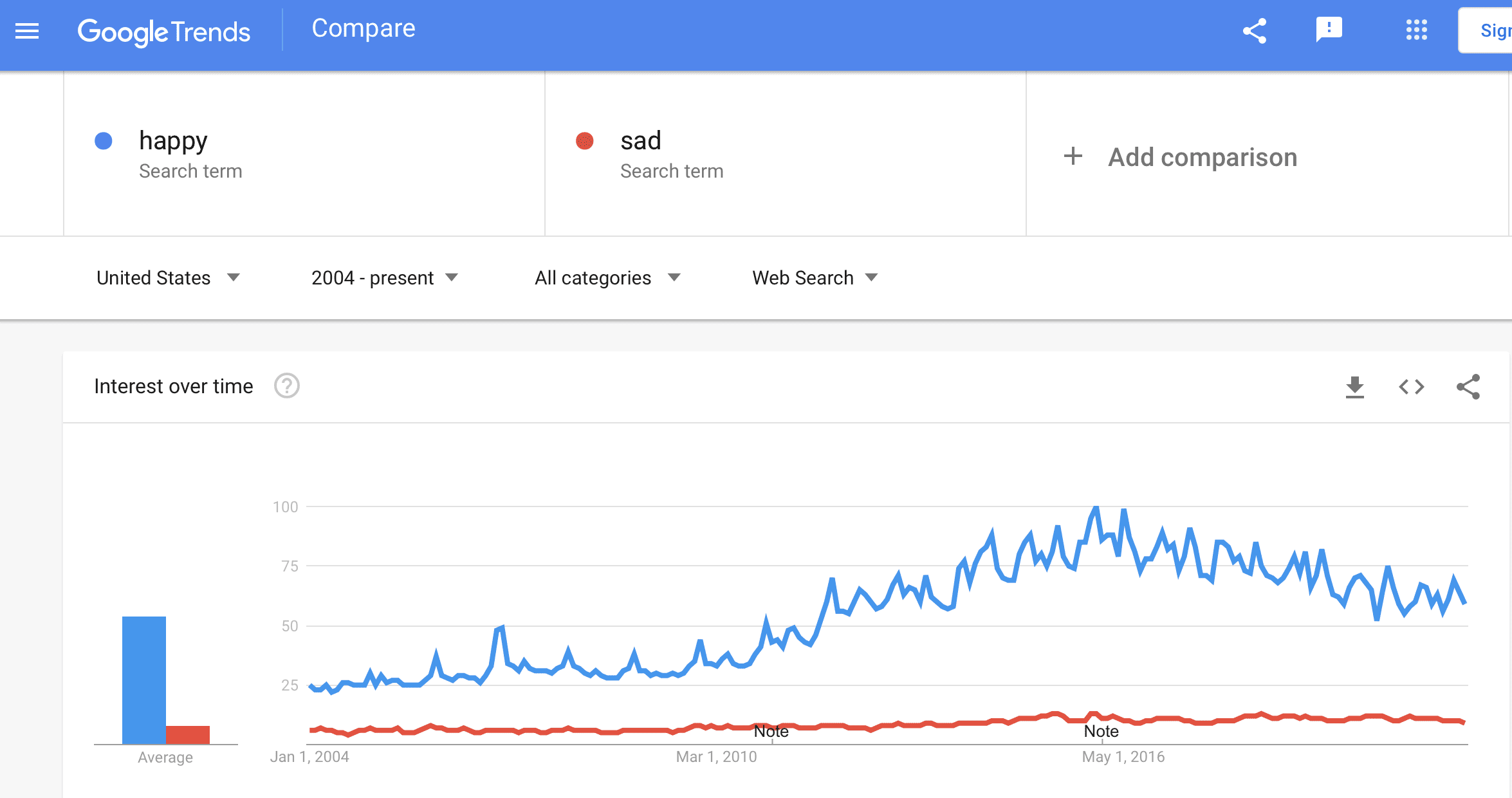

OK, these two don’t seem so exciting. But you get the point. You could keep looking at pairs of words until some interesting patterns come up.
Why would this not get published in PNAS? I guess it’s just too easy. But you could get a good class discussion going on measurement issues with some of these graphs. My guess is that students would behave like the news media, first just taking any pattern they see in the data as representing some important underlying truth, then stepping back and considering what they’re actually trying to measure.
The thing that always boggles my mind with these terrible associations is that they could just *check*. You already have a program that scrapes “I am __” instances, so just draw ~20 of them randomly and see how many of them are in fact instances of the underlying bias you’re trying to capture! It’s completely trivial to get a reasonable estimate of how accurate the proxies are (or at least of false-positive rates), but so many people just don’t bother.
This sounds eminently sensible, however: (1) checking requires some degree of self-awareness, and (2) if you check and find that your measure isn’t valid, you don’t get a paper in PNAS. Therefore, if the goal is a paper in PNAS and rather than scientific insight, you shouldn’t check…
Less cynically: This would be a good exercise for readers of this blog. If ~50 people each look at ~100 “I am a …” statements and tabulate them on a Google form, it would make a nice study, and a useful message to send. It would take someone to organize it — perhaps a psychology grad student who reads this?
Here’s a follow-up letter by Schmidt that PNAS published https://www.pnas.org/doi/10.1073/pnas.2115010118. There is a reply from the authors that is awfully confident that Google does a good job of capturing all and only fiction in its “Fiction” corpus (https://twitter.com/benmschmidt/status/1455585166672400386).
Dean:
Oh yeah, that response by the original authors is terrible. Here’s how it concludes:
It’s a safe bet that whenever someone uses the phrase “overly harsh critique” or “throwing the baby out with the bathwater,” they have no substantive argument to offer.
A Quote from the PNAS article: “For example, “I will never” would be implicated in the expression of a cognitive distortions such as Catastrophizing or Fortune-telling, whereas “I am a _” would be used to express a Labeling and Mislabeling distortion.”
Hmm — What if I said, “I will never be eleven years old again”. Would that be a “cognitive distortion”?