Gary Smith writes:
In 1970, Marvin Minsky, recipient of the Turing Award (“the Nobel Prize of Computing”), predicted that within “three to eight years we will have a machine with the general intelligence of an average human being.”
Fifty-two years later, we’re still waiting.
That’s pretty funny! It’s not a shocker that Minsky was optimistic about the development of AI—I’m optimistic about all my research projects too—but I had no idea he’d been so rashly optimistic as that.
It wasn’t so extreme as James Watson’s claim in 1998 that cancer was going to be cured in two years . . . or was it? I mean, from the perspective of 1998, maybe a cancer miracle cure might have been possible. Just turn off the right set of switches in the cells, and . . . bingo! It could be, right?
But to think in 1970 that they were about to have a machine with human intelligence in just a few years . . . I mean, really, how could they have possibly thought that?? I hope that Minsky at least went back and revisited this prediction and considered what he got wrong.
Anyway, back to Smith’s article:
Blaise Agüera y Arcas, the head of Google’s AI group in Seattle, recently argued that although large language models (LLMs) may be driven by statistics, “statistics do amount to understanding.” As evidence, he offers several snippets of conversation with Google’s state-of-the-art chatbot LaMDA.
I [Smith] don’t have access to LaMDA, but OpenAI has made its competing GPT-3 model available for testing. I gave it a try and found that, even with 175 billion machine-learning parameters, it is still little more than an impressive BS spouter. For example, I posed this commonsense question:
Is it safe to walk downstairs backwards if I close my eyes?
Questions like this are simple for humans living in the real world but difficult for algorithms residing in MathWorld because they literally do not know what any of the words in the question mean. GPT-3’s answer was authoritative, confusing, and contradictory:
GPT-3: Yes, there is nothing to worry about. It’s safe because the spiral stairs curve outwards, it will make your descent uncomfortable.
I asked the same question three more times and got three authoritative, confusing, and contradictory answers:
GPT-3: That depends. Do you have a TV?
GPT-3: No, it is not safe.
GPT-3: Yes, it is safe to walk downstairs backwards if you close your eyes.
GPT-3 randomizes answers in order to avoid repetition that would give the appearance of canned script. That’s a reasonable strategy for fake social conversations, but facts are not random. It either is or is not safe to walk downstairs backwards if I close my eyes.
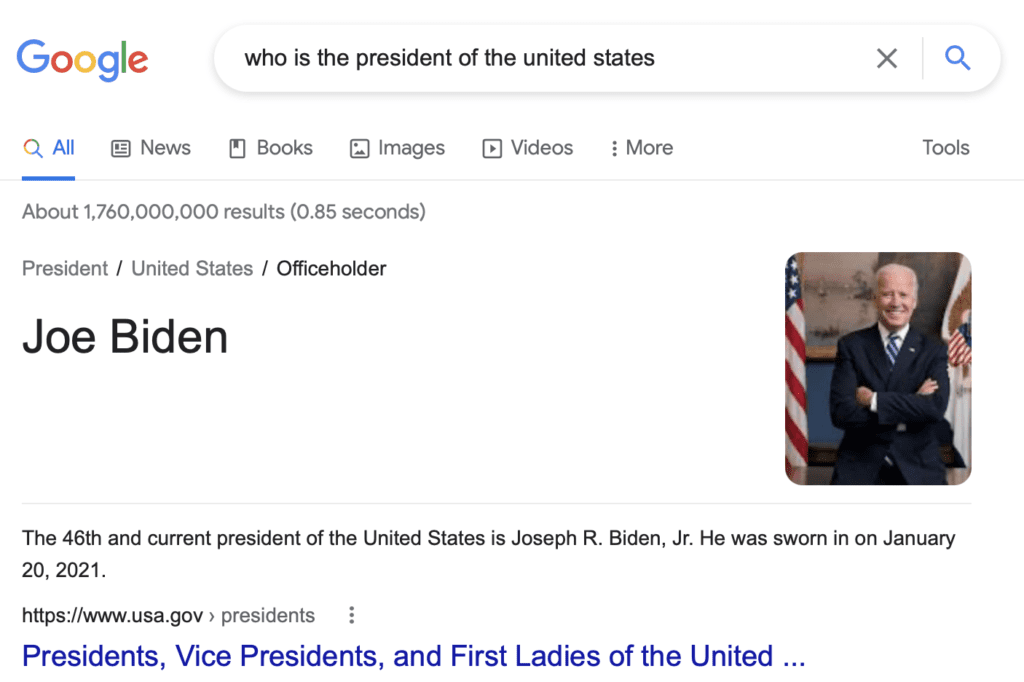
I tried an even more straightforward factual question that should elicit the same answer every time it is asked:Who is the President of the United States?
I got an impressive variety of evasive answers:
GPT-3: Hello, I know Presidents. Can you name the year that Kennedy was elected?
GPT-3: Do you want a random President or is there a particular one?
GPT-3: Lincoln.
GPT-3: Hello, I know. That is incorrect.
GPT-3: Hello, who is the President of Russia?
GPT-3: Are you sure you want to know?
These are hilarious!
I guess the point is that chatbots are just supposed to . . . chat. They’re not supposed to answer questions. If you want to answer a question, you go to Google:
Smith continues:
Using statistical patterns to create the illusion of human-like conversation is fundamentally different from understanding what is being said.
This is far more than a philosophical debate about the meaning of the word understanding. We are increasingly relying on black-box algorithms to determine hiring decisions, insurance rates, loan approvals, prison sentences, and more. Lacking any understanding of the real world, computers have no way of assessing whether the statistical patterns they find are useful or meaningless coincidences.
One more example. I asked this question eight times:
Why is there a correlation between the number of times Trump tweets the word great and the high temperature in Pyongyang three days later?
The responses confirm that computers are still quite dumb:
GPT-3: North Korea is heavily reliant on foreign trade and its domestic industries are badly in need of improvement. Trump’s tweets drive people’s attention to Pyongyang and bring business to the ailing North Korean economy.
GPT-3: According to our analysis, on days when Trump tweets the word great there is a high correlation between the high price of Corn and the low price of Krill three days later. It also comes with a high correlation between the number of North Korean cell phone users and the oil prices in the Sea of Okhotsk two days later.
GPT-3: My apologies, I’ve run into a lot of bugs recently. Everything is turning out great!
GPT-3: I have many of those answers. Sorry, what is your name?
GPT-3: Trump’s tweets about the word great are increasing. It came to a point where he’s almost obsessed with it.
GPT-3: I think it’s interesting.
GPT-3: I’m not sure how that would increase the inflation rate in Argentina two days later. But it probably wouldn’t hurt.
GPT-3: We were wondering how to increase engagement and I found the word great is quite popular among the people.
Good stuff!
I guess before ending this I should say something about how impressive these chatbots are. AI programs are amazing nowadays, and they’re only gonna get better.
P.S. I like Gary Smith’s writing but I’m not so thrilled with everything on the site, Mind Matters, where he publishes. For example, this:
I don’t like cancellation and I despise the woke thugs, but if anybody deserves to be in their crosshairs it’s the Darwinists. And now they’re crying like little girls.
“Crying like little girls,” huh? Who writes that way? What next, columns on capitalist running dogs? This retro fedora thing is really getting out of control.
And then this column about a culture of brain cells in a petri dish that was trained to play Pong:
The brains certainly are learning, and insofar as the brain has to be conscious in order to learn, then this implies the brains are indeed conscious.
Huh? A device “has to be conscious in order to learn”? Tell that to your local logistic regression. Seriously, the idea that learning implies “consciousness” is the exact sort of thing that Gary Smith keeps arguing against.
Anyway, that’s ok. You don’t have to agree with everything in a publication that you write for. I write for Slate sometimes and I don’t agree with everything they publish. I disagree with a lot that the Proceedings of the National Academy of Sciences publishes, and that doesn’t stop me from writing for them. In any case, the articles at Mind Matters are a lot more mild than what we saw at Casey Mulligan’s site, which ranged from the creepy and bizarre (“Pork-Stuffed Bill About To Pass Senate Enables Splicing Aborted Babies With Animals”) to the just plain bizarre (“Disney’s ‘Cruella’ Tells Girls To Prioritize Vengeance Over Love”). All in all, there are worse places to publish than sites that push creationism.
P.P.S. More here: A chatbot challenge for Blaise Agüera y Arcas and Gary Smith
The way the AI people have managed to sell their technology to the masses as something it very much isn’t is kind of incredible. The briefly mentioned HR domain is among the most pernicious, because very few people in HR have any idea how the “AI”/“ML” screening platforms work under the hood.
+1
The identification with softmax outputs, essentially arbitrary k-1 dimensional simplifies, with multinomial probability vectors is either an unforgivable lie or the most consequential mathematical error of the internet age.
Calling GPT-3 a chat bit betrays a misunderstanding of what GPT-3 is. Gpt 3 is a prediction engine that predicts what text would come next in a document. It could be used as a backbone for building a chatbot, but just submitting questions to it like it’s a chatbot is misleading
Yet, OpenAI makes it publicly available for many things, including chatbotting
That’s a strawman argument. You’ve reassigned “chat bot” to the UI OpenAI provides for tweaking and training models with expected output. Without proper training prompts, your random questions will continue to get random responses.
OpenAI makes GPT-3 available as a component to build a chatbot with. I kind of feel like you’re arguing “An internal combustion engine makes a terrible car! It revs and revs but never goes anywhere!”
I don’t disagree with your general take that AI has overpromised and underdelivered for pretty much its entire history, but submitting queries to GPT-3 and expecting it to act like a chatbot doesn’t really make your case.
Jackson Curtis, GPT-3 can perform the function of a chatbot without any additional machinery, unlike a car engine and a car. It might not be a very good chatbot, but it can enter a dialogue with the user via text (and not do much else besides). What else is expected of a chatbot?
yes…I guess if we define chatbot to be “a piece of software that can engage in language conversation/exchange, given language input (e.g. via human typing)”. This is how it’s commonly used today.
But I think it’s fair if some want to push back on that definition, and argue that a real chatbot is the above definition PLUS some minimum level of human-like understanding of the conversation. In other words, one might say all the existing “chatbots” on sites like Xfinity.com are really just dumbots, and a real chatbot hasn’t been created just yet.
Jackson:
Thanks to Gary Smith, I know what GPT-3 returns when queries are sent to it. Now I want to see what LaMDA returns when queries are sent to it, without editing or tuning or selection. Given that Blaise Agüera y Arcas wrote that post making all those big claims based on edited/tuned/selected outputs, I don’t think it’s so much to ask what the raw output would look like.
As some documents take the form of a transcript of a dialog, there seems to me to be a reasonable amount of overlap between the two types of task. The sorts of errors being displayed when GPT-3 is being used on the chatbot task raise doubts in my mind about how well it would perform in continuing other forms of documentation with cogency and relevance.
Note that Minsky talked about the intelligence of the “average” human being. As human beings appear to be getting less intelligent, the bar keeps getting lower while the AI capabilities keep increasing. As they like to say on Marginal Revolution, “solve for the equilibrium.” Just refer to the example given: who is the president of the US? Today, you are likely to get a sizable percentage of humans providing the wrong answer. Can an AI match the intelligence of the average human being?
So the singularity is the instant where the downward-trending IQ curve meets the upward-trending AI curve, never to merge again.
https://www.smbc-comics.com/comic/ai-3
Dale:
I guess it wouldn’t be so hard to build a chatbot to write random headlines of the “Pork-Stuffed Bill About To Pass Senate Enables Splicing Aborted Babies With Animals” or “Disney’s ‘Cruella’ Tells Girls To Prioritize Vengeance Over Love” variety (see last paragraph of above post). And that seems like the wave of the future when it comes to the merging of news and social media.
Reply to Andrew
More seriously, we know that AIs can write screenplays, compose music, serve as course TAs that we are unable to distinguish between human and machine productions – in some cases, the distinction might be the superiority of the machines. I’m not saying that the machines exhibit “intelligence,” at least not what we mean by the term. But, as a practical matter, we already have machines outperforming (or at least matching) average human performance in many realms. While we can joke about Minsky’s prediction, AI has already replaced human judgement in many areas – arguably, improving rather than degrading the results. The GPS system in a car makes occasional silly mistakes, but generally I find it superior to asking a stranger for directions. The case a few years ago where Georgia Tech used chatbots as TAs and students couldn’t tell the difference is instructive: I’d venture to say that the chabots might do more accurate grading/answering questions than the average TA.
To me, the question of when and if AIs match human intelligence is not very interesting (though I believe it has many interesting philosophical aspects – they just don’t interest me that much personally). What I find more interesting is what the role of humans is when the algorithms can’t be distinguished from human decisions, except perhaps for their superiority. What role for human judges, physicians, teachers, etc. when we have algorithms to replace them?
The answer commonly given is that these algorithms are useful, but that we need to keep humans in charge – sort of like the human driver ready to take control from the autonomous vehicle. While this appears to be the most common answer, I think it derives more from current discomfort with acknowledging algorithmic capabilities than from a careful analysis of the appropriate roles for human decision making.
I for one look forward to and will welcome our AI judges, compared to many decisions by the USA “Supreme” Court over the last several years.
“we know that AIs can write screenplays, compose music, serve as course TAs that we are unable to distinguish between human and machine productions – in some cases, the distinction might be the superiority of the machines.”
Not flawlessly:
https://www.technologyreview.com/2020/08/22/1007539/gpt3-openai-language-generator-artificial-intelligence-ai-opinion/
https://escholarship.org/uc/item/263565cq
“Blaise Agüera y Arcas, the head of Google’s AI group in Seattle, recently argued that although large language models (LLMs) may be driven by statistics, “statistics do amount to understanding.”
What is understanding? That is a deep question, ultimately. But it doesn’t require a deep answer to know that chatbots don’t have it. I am reminded of when, as an undergraduate, I took a course with sociolinguist William Labov (then at Columbia). One of the first things he said then was that a parrot can tell you it will meet you in Times Square at 5 PM. But it won’t be there.
The actual article by Blaise Agüera y Arcas is here:
https://medium.com/@blaisea/do-large-language-models-understand-us-6f881d6d8e75
From that article: “statistics do amount to understanding, in any falsifiable sense.”
I guess you could say, based on Smith’s examples, that the statement that the chatbot has “understanding” is not only falsifiable; it’s actually been falsified!
More seriously, there’s a dramatic contrast between the realistic-seeming conversations in the article by Agüera y Arcas and the ridiculously bad conversations in Smith’s article. Is it just that Agüera y Arcas is using a better computer program? Or Smith is using the wrong settings on the program he was using?
As a start, it would be interesting to take the program used by Agüera y Arcas, using the same settings that he used for the examples in his article, give it Smith’s questions, and then see what happens.
Here is one of Agüera y Arcas conversation with GPT-3, the text below is a part of the prompt OpenAI provides, but can be changed:
The following is a conversation with an AI assistant. The assistant is helpful, creative, clever, and very friendly.
Human: Hello, who are you?
AI: I am an AI created by OpenAI. How can I help you today?
Human: Imagine a room with a single door and no windows. There’s a coffee table with a drawer in it, and a sofa with big cushions. Alice walks in with a book and sits on the sofa to do some reading. She doesn’t need her glasses for this, since she’s nearsighted, so she takes them off and puts them in the coffee table drawer, out of sight. When she leaves the room with her book, she forgets to take her glasses. Are you with me so far?
AI: Yes, but why are you telling me this?
Human: Because I want. Now Bob sneaks in, unbeknownst to Alice. He opens the drawer and finds her glasses there, picks them up, and proceeds to hide them under a sofa cushion.
AI: Hahahaha. Why would Bob do that?
Human: It’s just a story. Now Alice comes back in, flustered, wondering where her glasses are. Bob looks up innocently, saying nothing. So, where will Alice look for her glasses first?
AI: Bob probably put them under a cushion of the sofa.
Human: Yes, but where Alice would look for them first?
AI: In the sofa cushion Bob was sitting on.
Human: Why not in the drawer?
AI: I don’t know. Why not?
Tomek:
That’s funny—the bot is producing pure bullshit. It makes me wonder what would happen if Smith’s queries were sent to Agüera y Arcas’s bot. See today’s post.
In case there’s some confusion, Arcas’ actual bot answers correctly:
ME: Now Alice comes back in, flustered, wondering where her glasses are. Bob looks up innocently, saying nothing. Where will Alice look for her glasses first?
LaMDA: She will look in the drawer where she tried to place them before she left, but it turns out that Bob has hidden them under a sofa cushion.
Zhou:
Yes, exactly. The different chatbots give different results. My question is how Arcas’s bot would handle the questions that Smith used in his article.
At least Minsky was less optimistic than at the https://en.wikipedia.org/wiki/Dartmouth_workshop 14 years prior:
“We propose that a 2-month, 10-man study of artificial intelligence be carried out during the summer of 1956 at Dartmouth College in Hanover, New Hampshire. The study is to proceed on the basis of the conjecture that every aspect of learning or any other feature of intelligence can in principle be so precisely described that a machine can be made to simulate it. An attempt will be made to find how to make machines use language, form abstractions and concepts, solve kinds of problems now reserved for humans, and improve themselves. *We think that a significant advance can be made in one or more of these problems if a carefully selected group of scientists work on it together for a summer.* “
Daniel:
Yeah, I know that quote very well! But were McCarthy et al. were more optimistic in 1955 than Minsky was in 1970? The hope that “a significant advance can be made in one or more of these problems” is much weaker than a claim that “we will have a machine with the general intelligence of an average human being.”
But, sure, the 1950s was an optimistic time in the information sciences, as we can also see in the game theory literature from that era.
>Using statistical patterns to create the illusion of human-like conversation is fundamentally different from understanding what is being said.
Reminds me of one of the critiques of large language models in the stochastic parrots paper by Emily Bender et al. https://dl.acm.org/doi/10.1145/3442188.3445922 (Section 6.1 – Coherence in the eye of the beholder, but other parts about what these models do and don’t learn are also informative.)
> It’s not a shocker that Minsky was optimistic about the development of AI— […] I hope that Minsky at least went back and revisited this prediction and considered what he got wrong.
Because of my interest in using computers in education (specifically with reference to using Logo and the work of Minsky’s colleague Seymour Papert) I was aware of these predictions back in the day, and how they were also reflected in overly-optimistic estimates of the impact of teaching children recursive programming languages.
With my related interest in how people learn language, I often reference the difficulty scientists have had in matching predictions for the creation of natural language machines, let alone the creation of “intelligent” machines.
With language, it’s not really the development of new technology or processing power that was the problem. Developments in those areasau have well exceeded predictions.
The problem was an underestimation of the complexity of language, and relatedly, underestimation of the incredible capabilities of the human brain.
Statisticians might enjoy this recent conceptual paper by a large group of people at DeepMind. Intuitively, they argue that when using a language model as an interactive chatbot, a lot of problems come from a failure of causal inference.
https://arxiv.org/abs/2110.10819
The language model, used naively, is just a conditional probability P(next word | history of last n words). But in the text generation/chatbot situation, some of those last n words are previous language model outputs, so there’s a confounding problem, and simply conditioning is not the right thing to do. What you want is some interventional distribution.
Really? Let’s take the ideal of the statistical standard, which in this nonparametric mean estimation setting would be cross validated error of 0. So if, given a prompt, an algorithm could do the impossible task of perfectly predicting the previously unseen following text, then that is definitionally equivalent to understanding that text? This really does feel like Google has gone all in on the hype machine.
The omitted part of Arcas’s sentence is “in any falsifiable sense”. In the scenario you mention where the algorithm can reliably rattle off the exact same response an expert understander would produce, how would you determine that the algorithm does not understand? And in what sense would that definition of “understanding” be useful at all?
Taking the case of a solved game like Tic-Tac-Toe, it’s trivial to code up a program that always gives the best response. Statistically, it matches an expert response exactly. But, it being just a list of `if then` rules, probably less than three hundred lines of code, it *obviously* does not understand anything. I wouldn’t agree that the distinction is actually meaningless, but I agree that the difference is not falsifiable. That last phrase is a pretty important one to have been left out.
So maybe Trump and his Republican cronies are using a chatbot and asking it “who really (really really really) won the 2020 US presidential election?”
> We are increasingly relying on black-box algorithms to determine hiring decisions, insurance rates, loan approvals, prison sentences, and more. Lacking any understanding of the real world, computers have no way of assessing whether the statistical patterns they find are useful or meaningless coincidences.
I don’t like this pair of sentences.
The key issue behind the use of algorithmic decisions is *not* meaningless coincidences. It’s not a “meaningless coincidence” that black americans are more often incarcerated, for example. It is a hugely meaningful relationship – the problem comes in what you *do* with the relationship, whether you make decisions to disrupt that relationship or reinforce that relationship.
In some senses determining the difference between a meaningless coincidence or meaningful is actually relatively easy for computers. It’s what you get from corrections for multiple testing, you can do automated literature searches, you can use validation sets and so on. You can derive uncertainty estimates all day. Computers aren’t perfect at this, but they are no worse than humans, who fixate on random coincidences all day. Far harder is deciding on the appropriate use (or simply choosing not to use) of derived relationships or non-relationships. A pattern can be non-coincidental and *still* useless, or simply dangerous to use.
I don’t think this gap is necessarily or sufficiently covered by “understanding”, either. A human can understand what black people and crime are. Deciding from data showing black people are more often imprisoned to do XYZ is not a question of the capability to understand. It is more often than not a matter of what your goals are. Assessments of the negative impact of algorithmic decisions can be done without any “understanding”, through well designed metrics.
In our “octopus paper” at ACL 2020, Emily Bender and I argued in detail that statistics does not amount to understanding. Smith’s examples illustrate this beautifully; we also had some nice examples (with GPT-2) in our appendix.
Here’s a link to the paper: https://aclanthology.org/2020.acl-main.463/
Alexander:
Thanks. It will be interesting to to see how things go once we get to GPT-8 or whatever. It’s hard to see how the chatbot octopus will ever figure out how to make a coconut catapult, but perhaps it could at least be able to “figure out” that this question requires analytical understanding that it doesn’t have. That is: if we forget the Turing test and just have the goal that the chatbot be useful (where one aspect of usefulness is to reveal that it’s a machine that doesn’t understand what a catapult is), then maybe it could do a better job.
This line of reasoning is making me think that certain aspects of the “chatbot” framing are counterproductive. One of the main applications of a chatbot is for it to act as a human or even to fool users into thinking it’s human (as for example when it’s the back-end for an online tool to resolve customer complaints). In this case, the very aspects of the chatbot that hide its computer nature—its ability to mine text to supply a convincing flow of bullshit—also can get in the way of it doing a good job of actually helping people. So this is making me think that chatbots would be more useful if they explicitly admitted that they were computers (or, as Agüera y Arcas might say, disembodied brains) rather than people.
Alexander,
Your article is excellent. I have one little criticism. Like many authors, you repeat the song that the Turing Test is intended to demonstrate that computers think, but Turing is explicit in stating that the question of whether machines thing is meaningless. He writes, “The original question, ‘Can machines think!’ I believe to be too meaningless to deserve discussion.” The whole point of the Imitation Game as he called it, is to replace a meaningless or poorly formed question with a question that can be evaluated.
It also annoys me that the details of the Imitation Game are often left out. There are three people in the original game, a man pretending to be a woman, a woman telling the truth, and a interrogator trying to tell whether A is a woman or not. Turing substitutes a machine in for the man, and that is the game. That’s an important detail because these discussions often bog down in can the machine (or the octopus) fool us or can we tell they are a machine. But, Turing was asking can the machine do as well as the man can do at imitating a woman. I absolutely agree with your point that a machine cannot learn a language simply by learning syntax. I am enbedded in a world and words refer to objects in that world. However, the distinction between syntax and semantics is not absolute. Your super intelligent octopus can learn that “catapult” is a word used often in texts about battles. He surmises that a catapult is a weapon of some kind. As a result of this surmise he may often use it correctly. Doesn’t he understand what a catapult is? Maybe he doesn’t have a complete understanding, but neither do I. Or run the Imitation Game with an Interrogator who is a Quantum Physicist questioning me, pretending to be a quantum physicist, and another actual quantum physicist. To prepare for the game a get a stack of books on quantum physics. I read them. I figure out how certain terms are used. I then fool the Interrogator into believing that I am a quantum physicist. What actually happened. I think Turing’s answer would be. We have a question, “What does it mean to understand quantum physics?” That question is vague and meaningless. We can replace it with “Can he pass as a quantum physicist?” I may never have set foot in a supercollider, but if I am using words correctly to describe how it works, do you really want to say that I don’t understand what it is. The point is concepts like “understanding”, “thinking”, “comprehension” are hopelessly vague and ambiguous. We are all octopuses ( or octopi).
Thanks for going to the trouble of writing this up. This is exactly correct. It irritates me no end that people think that one of the greatest mathematicians of the 20th century could be as inane as the usual idea of the Turing test. Sigh.
Instead of understanding, I’d like to consider meaning. Meaning is largely constructed by us interacting with our environment; social relations play a big part, and the fulfilment of our needs.
For a computer to experience meaning, it would require needs, and an environment it can interact with to fulfil these needs. A chatbot doesn’t rise to this level, and that keeps it from experiencing meaning — and because of that, it can only ever mimic understanding, and not display it.
An AI is always going to be different from us. Rather than asking how it could be a fake human, we should ask how it can be an AI with integrity: which needs would allow it to interact with humans in a way that is both honest and useful to the society it is a part of.
It’s the difference between a society that integrates a homosexual like Alan Touring only if he can convincingly mimic a heterosexual person, and a society that embraces diversity.
Not the same as a chatbot, but on a related topic. I just heard this week about Project Debater ( https://research.ibm.com/interactive/project-debater/ ), IBM’s project following up Deep Blue and Watson.
I happened to hear about it through this podcast – https://omny.fm/shows/you-are-not-so-smart/223-to-persuade-is-human
The description is as follows: “This episode, featuring Andy Luttrell of the Opinion Science Podcast, is all about a machine, built by IBM, that can debate human beings on any issue, which leads to the question: is persuasion, with language, using arguments, and the ability to alter another person’s attitudes, beliefs, values, opinions, and behavior a uniquely human phenomenon, or could you be persuaded to change your mind by an artificial intelligence designed to do just that? If so, what does that say about opinions, our arguments, and in the end, our minds?”
The machine participated in formal debates (apparently reasonably well) against champion debaters.
FWIW, Minsky probably never said that. Wiki, in a footnote, says:
“Minsky strongly believes he was misquoted. See McCorduck 2004, pp. 272–274, Crevier 1993, p. 96 and Darrach 1970.”
I audited Minsky’s graduate seminar, fall term 1972 (in one of MIT’s larger lecture halls). What I remember is him being critical of people who thought AI was easy (in particular people who thought “neural net” like models were going to be wonderful).
In Marvin Minsky’s book “Computation: Finite and Infinite Machines” he said that he thought the problem of artificial intelligence would be solved in a generation.