(This post is by Yuling)
Yesterday I have advertised our new preprint on hierarchical stacking. Apart from the methodology development, perhaps I could draw some of your attention to the analogy between model averaging/selection and voting systems, which is likely to be more entertaining.
- Model selection = we have multiple models to fit the data and we choose the best candidate model.
- Model averaging = we have multiple models to fit the data and we design a weighted average of candidate models for future predictions.
- Local model averaging = we have multiple models to fit the data and we design a weighted average of candidate models for future predictions, and this time model weight varies in input predictors.
For notation simplicity I will consider a two-candidate situation. The easiest voting scheme is some popular vote: every ballot will be counted. In model averaging/selection, this approach corresponds to first fitting each model individually and count the utility of each model. Here voters are data points in the observation, and they are more sophisticated than casting a binary ballot. What they vote by is a continuous number depending a pre-chosen utility function (negative pointwise L2 loss, pointwise log predictive density, etc). We could replace this training error by leave-one-out cross validated error too. The bottomline is that we will count each of the ballots and add them up to obtain either the negative mean squared error or mean log predictive densities. For Bayesian model averaging or pseudo Bayesian model averaging, we have a proportional representation system: model 1’s weight is proportional to its total voting shares (sum of pointwise log predictive densities). For model selection using LOO-CV, we pick the candidate with who wins the popular vote.
One implication of this proportional representation system is that a candidate would like to take care of every voter. It is something related to the “median voter theorem” in economics, but even worse: data points vote in log scale and can be widely mad if ignored. To some extent this explains why BMA is typically polarized. Imagine in a presidential election, but instead of a binary ballot to cast, voters endorse their preferences by two positive real numbers a and b to two candidates, such that a+b=1. A candidate’s total vote count is the multiplication of all endorsements they receive (equivalently, the summation of log a or log b they receive). The voting result will typically be quite distinct.
By contrast, we explain in the paper (Section 3) that stacking behaves like a “winner takes all”/electoral college system. That is, we first group data points/voters into two districts. Then the winner takes all shares of a district no matter how big or small the winning margin is therein.
We provide an example in which when two models become closer and closer to each other (smaller KL divergence, higher correlation of predictions, etc), their stacking weights are more distinct and eventually approach 0 and 1 when two models are nearly identical. This dynamic would never happen in a representative voting: if two candidates are identical-twins, why shouldn’t they get the same voting share? But from the standpoint of the an oracle planner/stacking, if two candidates do function identically, why should they be both kept in the administration?

Put it in another way, observing a nationwide popular vote of 51%/49% can correspond to two stories:
- In the first story, candidate A appeals to 51% of the population but is hated by the remaining 49%. Then both BMA and stacking will assign models with the 51%/49% weight.
- In the second possibility, these two candidates are non-identical twins, while Candidate A is superior to Candidate B by tiny margins in all aspects, such that every voter slightly prefers Candidate A and would vote for A by probability 0.51. Then BMA assigns candidate A with weight 0.51 and B with 0.49. Fair but not ideal. What stacking does is to realize that candidate A actually makes everyone better off, so as to assign it with weigh 1 regardless of the small winning margin. I think economists may call this “Pareto improvement”.
It is disputable whether or not the popular vote is more democratic than the electoral college. One advantage of the latter approach, or stacking in our context, is that a model can simply ignore some part of date and only focus on where its expertise is. Because of the weighting in the end, two distinct models can then collaborate. What matters is not how overall-good one single candidate is, but rather how the combination can be optimized, which implicitly encourages some individual diversity.
That said, one remedy to improve the electoral college system is to have finer-grained election districts, which is precisely what hierarchical stacking is aimed for by assigning a local weight conditional on predictors X. That is, we group voters according to their preferences first, such that people living in the same tribe have similar views. Then we assign each tribe a local combination of candidates as per their preference. Apparently such arrangement is too complicated for any society to adopt, but at least you could apply it to your stan models and make your data points happier.
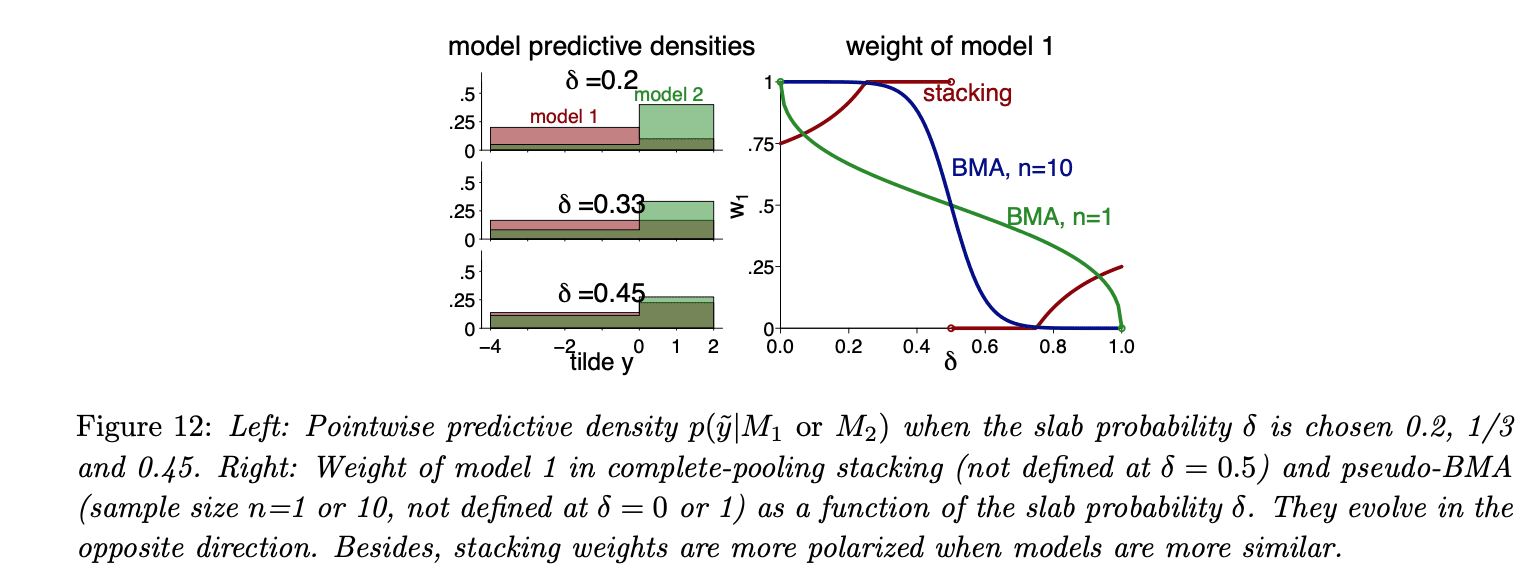
Where are the spikes and slabs for the two models in Figure 11? Is one the spike and another the slab? Or do they each have spikes and slabs?
Figure 11 is an ideal bipartisan situation: Candidate 1 is nearly only supported on the interval [-4,0] (the spike part). It has 0.01 probability on (0,2) (the slab part) to avoid zero-denominator. Candidate 2 is supported by the opposite part of the population.
This is a much better version of some ideas I’ve been working with for the past 9 months or so. You might look into Gavin Brown’s Ph.D. thesis on Negative Correlation Learning for a good characterization of the importance of diversity to stacking or stacking-like approaches. He didn’t invent the approach, but he cleaned it up a lot. His thesis’s Chapter 4 discusses a similar continuum as your Figure 1. He’s still doing work in feature selection involving some related ideas, so you might want to talk with him on it sometime. My work was building on his, but yours is a million times more mathematically mature, looking forward to digesting this.