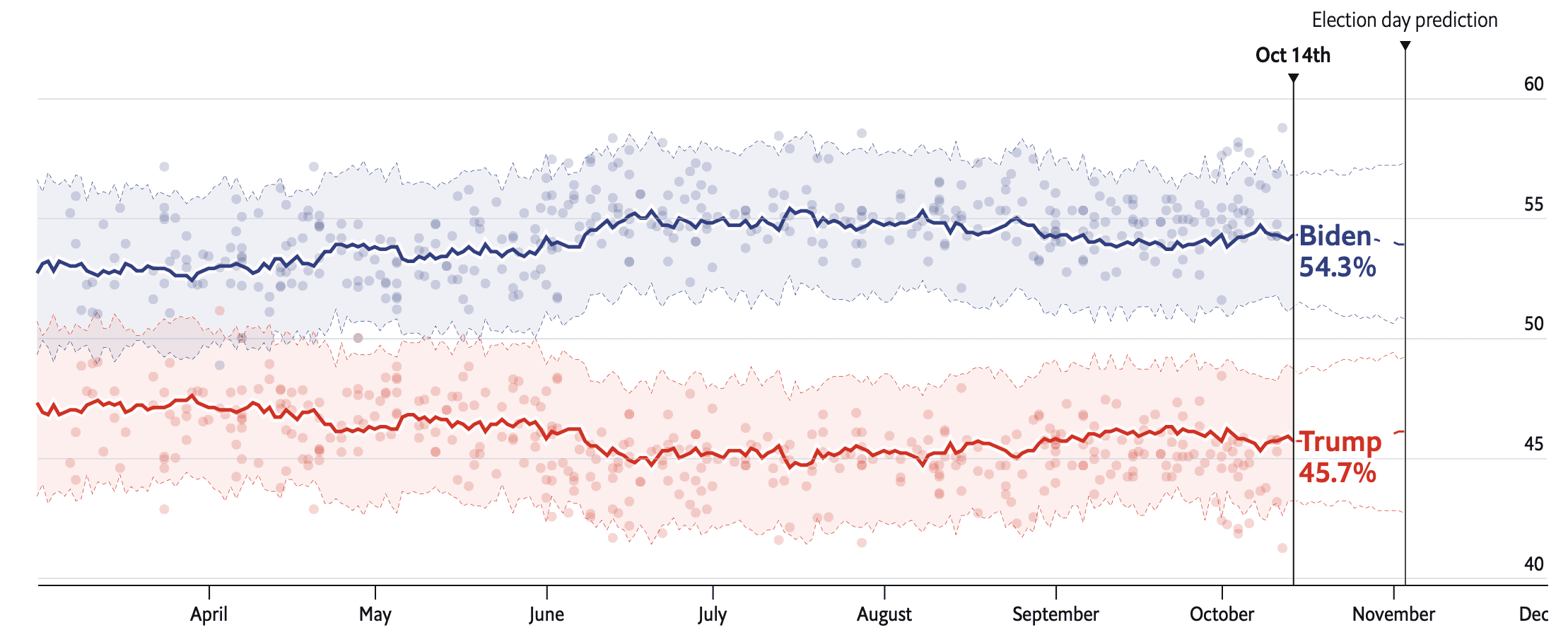
The above is from our Economist election forecast. Someone pointed to me that our estimate is lower than all the dots in October. Why is that? I can come up with some guesses, but it’s surprising that the line is below all the dots.
Merlin replied:
That happened a bunch of times before as well. I’d assume that there are more pro Dem pollsters than pro Rep or unbiased pollsters. Plus those who don’t adjust should also be above the line. And then we are still getting dragged towards the fundamentals.
And Elliott wrote:
First, the line is not lower than all the dots; there are several polls (mainly from the internet panels that weight by party) that are coming in right on it.
Merlin’s email explains a lot of this, I think — our non-response correction is subtracting about 2 points from Dems on margin right now,
But perhaps a more robust answer is that state polls simply aren’t showing the same movement. That’s why 538 is also showing Biden up 7-8 in their model, versus the +10 in their polling average.
And I realized one other thing, which is that the difference between the dots and the line is not as big as it might appear at first. Looking at the spread, at first it looks like the The line for Biden is at around 54%, and the dots are way above the line. But that’s misleading: you should roughly compare the line to the average of the dots. And the average of the recent blue dots is only about 1 percentage points higher than the blue line. So our model is estimating that recent national polls are only very slightly overestimating Biden’t support in the population. Yes, there’s that one point that’s nearly 5 percentage points above the line, and our model judges that to be a fluke—such things happen!—but overall the difference is small. I’m not saying it’s zero, and I wouldn’t want it to be zero; it’s just what we happen to see given the adjustments we’re using in the model.
P.S. Elliott also asked whether this is worth blogging about. I replied that everything’s worth blogging about. I blog about Jamaican beef patties.
I think Nate Silver said on a recent podcast that the estimate of national average from state polling is between +9.0 and 9.5. The estimate of popular vote on Election Day is closer to +8 because fundamentals predict a the race will tighten.
Nate also said in a recent tweet that there model will react more quickly/aggressively to changes in polls when it is close to Election Day (e.g., Comey letter). Does the economist forecast make that adjustment?
N:
The Economist (i.e., us) and Fivethirtyeight go about things differently. We have a model for the polls and the underlying public opinion (including a model for how that opinion varies over time), then we estimate the unknowns using Bayesian inference. So we don’t need to add in any decisions to react more aggressively or reweight or whatever because this is all implicit in the model: the Bayesian forecast of the election-day outcome automatically changes as the election gets closer, because of how the time series model works. Fivethirtyeight does some sort of weighting of polls, I think, and so its weights need to be constructed to do the right thing as election day becomes closer. I’m not saying that our approach is necessarily better than theirs (or vice versa): there are arguments for or against Bayesian inference, as compared to coming up with a data-based estimator without a full probability model. They’re just different approaches, and some things that they would need to put in explicitly in their forecast come automatically if you’re fitting a Bayesian time-series model.
I think I can divided my question into two parts:
1) Theoretically, do vote intentions change more quickly as you approach Election Day? It seems you are smoothing out the polling data trying to separate noise/error from true changes in voting intentions. I imagine this smoothing could obscure fast changes such as releasing the Comey letter. If voters are more tuned in to the news as we approach Election Day, then maybe voter intentions will change faster.
2) Does your election forecasting approach allow for this type of phenomenon? I am not exactly sure how you would model this effect. Maybe it would manifest as autocorrelation decreasing over time in each simulated trajectory so that the final weeks might be more wiggly.
N:
1. I have no idea if vote intentions change more quickly as you approach Election Day. It’s possible, and the opposite is possible too. I guess it depends on the context.
Just to be clear, we don’t “smooth out” the polling data. We fit a time series model that allows for underlying changes in opinion.
2. Yes, it would be possible to expand the model to allow larger jumps. But I don’t really see much support in the data for this.
Andrew:
You say “you don’t see much support in the data” for allowing larger jumps. How do you tune or calibrate this aspect of the model? Have you looked at how your forecast would have changed in real time to an event such as the Comey letter (e.g. -3 pts in 1 week)?
N:
First, we parameterize in terms of one candidate’s share of the 2-party vote, so a 3 percentage point shift in the difference is what we would cal a 1.5% shift. Second, I think that when we see large swings in the polls, much of that is explainable by differential nonresponse. The rest, yes, this would fit our model.
Regarding how the forecast will change in real time: It won’t jump immediately, because it doesn’t “know” how much of the shifts are real. But if there are enough polls showing this swing, then, yes, the forecast will move. We haven’t looked at this sort of thing in detail, though. It would be possible to simulate some data and see what would happen.
Chiming in here, N and Andrew:
You can see the results of our 2016 mode here: https://github.com/TheEconomist/us-potus-model
You’ll have to scroll down a ways to get to our time series. It looks like the model reacts just fine to the Comey letter, at least to the extent that polls picked up the movement.
But note that a 3 point change in a week look like an exaggeration. In fact our model picked up the vast majority of tightening in the final month of the election *before* the Comey letter hit the media cycle.
So I think we’re at risk at getting too caught up in narratives and conventional wisdom here…
>>In fact our model picked up the vast majority of tightening in the final month of the election *before* the Comey letter
Hmm, so would that suggest that if this election were going to follow the trajectory we should have already seen that (given that we’re well into the final month)?
Elliott:
Nate Silver wrote an article ‘The Comey Letter Probably Cost Clinton The Election’ which claims a -2.9 swing in popular vote margin for Clinton and a -2.8 swing in swing states. I don’t know if that is accurate, but I assume that is what he was referencing when he tweeted “I would note that our averages are tuned to a more aggressive setting in the closing days of the campaign. There certainly can be danger in under-reacting; we think some other averages were a bit slow to adjust to the Comey letter in 2016, for example.” That was what prompted my original question, however, maybe that adjustment in reported polling average is separate/different than how polls are handled in their forecast.
N:
I haven’t read this particular article by Nate, but let me just say again, first, that a 2.8 percentage point swing in the vote margin is a 1.4 percentage margin in vote share, and, second, that a 1.4 percentage point swing in the polls is probably something like a 0.5 percentage point swing in public opinion (with the remaining change arising from differential nonresponse).
The other point is that the way a Bayesian model works is that we don’t construct averages, aggressively or passively. We have a model for the underlying process and a model for the polls given the underlying process. We could indeed model increased variation during the last week of the campaign. I don’t really know that this makes sense, but it’s a modeling choice, sure.
I raised a similar concern here and got have spent some time since then thinking about Andrew’s response.
https://statmodeling.stat.columbia.edu/2020/06/12/election-2020-is-coming-our-poll-aggregation-model-with-elliott-morris-of-the-economist/#comment-1361323
I still think my point is valid, but at the same time, I’d very much prioritize Andrews statistical expertise over my own worries. So I’ll try to reiterate as brief and clear as possible:
If I understand your point correctly, your model already accounts for a large share of the fluctuation seen in the latest raw polling data (one way or the other, e.g. by considering third party votes?), so you’d argue that while this looks counterintuitive, the non-change to the latest data might still be OK.
My counterargument is that I’d expect an optimally tuned model to perform roughly as well as a simple smoothing filter (in case of election polls as a 2-week moving average). Unless there’s some prior information hidden in the data or model (say on a hidden dynamic as in a predator-prey-model) your statistical model probably won’t do better at picking up the mean trends but shouldn’t do worse either (while adding a lot of additional benefits, e.g. by picking up information and uncertainty along the way). But statistical models are really hard to get right, so if your mean trend looks sluggish, there’s a good chance that it’s not calibrated right to pick this up.
Then again, my prior is that picking up short-term fluctuations is good (this appears to also apply to the 538 model’s built-in assumptions) and I’m not sure if this is ultimately correct.
Andrew:
Per our previous discussion regarding polling frequency and posterior intervals, I believe the problem is a bit more serious than I originally anticipated. To demonstrate, I ran the 2016 model with all of the polling data, then I reran the model after removing some polls in Florida. Specifically, I dropped all Florida polls that were conducted after August 1st of 2016. This removes about 75% of the polling data for Florida. The resulting posterior prediction interval for Florida is basically unaffected by this change.
I repeated this process a number of times, dropping all polls in Florida after a given date. You can see the results here:
https://imgur.com/a/FnYesp0
The bottom panel tracks the total number of Florida polls that the model is using to create the Florida predictions. Overall, the amount of polling data in Florida seems to have no real observable effect on the posterior prediction intervals.
After reading through the supporting literature, I believe that the source of this problem may be with the way the random walk process is coded. For states without polling on a given day, the change in the latent vote intention variable (mu_b) for that state is constructed as a deterministic linear transformation of the changes in states with polling. The only variation in vote intention that the model allows is through polling — unpolled states are constrained to have zero state-specific variance in vote intention on those days. In other words, the random walk process is not coded as a random walk. Or more precisely, the variance of the random walk innovation is a function of polling frequency.
Here’s another way of seeing it: Imagine the model were run on just two states. State A has polling every day, while state B has no polling. The only variation in mu_b that the coded model will assign to state B is the attenuated variation in State A’s polling (attenuated by the between state correlation being less than 1). If I’m reading the code correctly, the model will be more confident (smaller CIs) in state B’s predictions, despite there not having been a single poll. Note as well that this problem also explains the improper coverage of the CIs for the infrequently polled states, as first noticed by fogpine.
If this is indeed the problem, then the solution is fairly simple: explicitly code the random innovation in the random walk process. At each iteration of the random walk (line 86 of poll_model_2020.stan), draw a random innovation from the random walk distribution instead of the current linear transformation. This is closer to the theoretical model, and also allows all states to have some state-specific variation on days without polls.
Mj:
We can take a look. National swing is pretty much uniform, so I could well believe that throwing away 75% of the polls from a state won’t add much uncertainty to its posterior distribution. But I agree it should add some uncertainty, so we’ll have to look more carefully.
The problem with this position though is that the posterior means are affected quite a bit by the presence of polls. This seems to contradict the notion that the CIs are properly estimated conditional on the amount of polling.
An easy way to test this is to run a permutation test of sorts, where we iteratively estimate the model while shutting down all (or most) polling in one state at a time. If the CIs are properly estimated, then we should expect no qualitative difference in the distribution of p-values/CI coverage as a result of removing polls from the data. Running just three chains with 500 samples takes about twenty minutes on my computer, so I’d have to do this overnight, but I can get a sense of how this might go just by looking at Florida:
https://imgur.com/H2ccD51
But to get back to my main point in all of this, the counterfactual Florida in the above diagram (with no polling) looks very similar to the original model’s predictions for West Virginia and Wyoming, which have little polling. Florida is not a “tail” state, but we can mimic the poor CI coverage of the tail states just by manipulating the polls. To me, the weight of the evidence clearly indicates that the model has a poll problem, not a tail problem.
And going back to the Florida diagram one more time, note that the confidence intervals are almost identical when we remove *all* of the Florida polls. None of the 100+ polls conducted in Florida in 2016 have any impact on the model’s confidence in Florida’s vote share. That seems pretty remarkable.
Mj:
Removing polls from one state from the data should definitely affect our inferences. But maybe not as much as you might think, given approximate uniform swing. Again, though, we can take a look, as there could well be a problem somewhere in our model. We’ve had problems before, so no reason to think we can’t have some remaining issues.
FYI, something is wrong with the plot in my previous post. I can’t reproduce it, so I believe it must have been a coding error. I have not been able to reproduce such a dramatic swing in any of the states I’ve looked at since, which basically negates the entire point I was trying to make. Feel free to delete that comment!
I am a bit confused on the last point. If Sigma = LL^T, then mu_{b, t} ~ MVN(mu_{b, t – 1}, Sigma) should be equivalent to mu_{b, t} = L * Z + mu_{b, t – 1} if Z ~ N(0,1). The latter samples faster than the former but the outcome should be the same, should it not be? That doesn’t make the problem disappear but just to confirm.
There’s a lot of moving parts that I’m having some difficulty tracking, but your math does appear to check out. I’ll have to think more about this.
I totally agree. In some way, the model was “rushed” insofar as we don’t really have evidence of most of the model properties and their interactions besides educated guesses and some inspections of observational data. Thanks really for looking at it. I almost thought that being open about our model is pointless if nobody actually checks the code.
I see where I missed it: The raw_mu_b object is a SxT matrix. I had thought it was just a vector for the last day in the sample. My suggestion doesn’t make any sense in light of this.
I do still believe that there’s something happening with the relationship between the random walk error and the polling error that’s driving the “tail” behavior — there’s just too much of a correlation between polling and the unlikeliness of a state flipping to be ignored. But my case is definitely getting thinner the more I look at it.
I blog about Jamaican beef patties.
US elections come and go. Jamaican beef patties remain.
Jkrideau:
They remain in my arteries, that’s for sure.
“Jamaican beef patties remain.”
Probs not as long as American cheese.
It’s interesting that the concern was for Biden line being below the dots but the Trump line being above the dots was not a concern. Personally that seems more traumatic to me.
Jdk:
These are identical. We’re working with share of the two-party vote, discarding respondents who support third parties or express no opinion.