Chetan Chawla writes:
This paper will interest you, in defense of data mining.
Isn’t this similar to the exploration Wasnik was encouraging in his infamous blog post?
The article, by Itai Yanai and Martin Lercher, is called, “A hypothesis is a liability,” and it appeared in the journal Genome Biology.
I took a look and replied: I don’t think they’re like Wansink, but there’s something important they are missing.
Here’s what they write:
There is a hidden cost to having a hypothesis. It arises from the relationship between night science and day science, the two very distinct modes of activity in which scientific ideas are generated and tested, respectively. With a hypothesis in hand, the impressive strengths of day science are unleashed, guiding us in designing tests, estimating parameters, and throwing out the hypothesis if it fails the tests. But when we analyze the results of an experiment, our mental focus on a specific hypothesis can prevent us from exploring other aspects of the data, effectively blinding us to new ideas. A hypothesis then becomes a liability for any night science explorations. The corresponding limitations on our creativity, self-imposed in hypothesis-driven research, are of particular concern in the context of modern biological datasets, which are often vast and likely to contain hints at multiple distinct and potentially exciting discoveries. Night science has its own liability though, generating many spurious relationships and false hypotheses. Fortunately, these are exposed by the light of day science, emphasizing the complementarity of the two modes, where each overcomes the other’s shortcomings. . . .
I understand that a lot of scientists think of science as being like this, an alternation between inspiration and criticism, exploratory data analysis and confirmatory data analysis, creative “night science” and rigorous “day science.” Indeed, in Bayesian Data Analysis we talk about the separate steps of model building, model fitting, and model checking.
But . . . I don’t think we should enthrone this separation.
Yanai and Lercher contrast “the expressed goal of testing a specific hypothesis” with the mindset of “exploration, where we look at the data from as many angles as possible.” They continue:
In this mode, we take on a sort of playfulness with the data, comparing everything to everything else. We become explorers, building a map of the data as we start out in one direction, switching directions at crossroads and stumbling into unanticipated regions. Essentially, night science is an attitude that encourages us to explore and speculate. . . .
What’s missing here is a respect for the ways in which hypotheses, models, and theories can help us be more effective explorers.
Consider exploratory data analysis, which uses tools designed to reveal unexpected patterns in data. “Unexpected” is defined relative to “expected,” and the more fully fleshed out our models of the expected, the more effective can be our explorations in search of the unexpected. This is a key point of my 2003 article, A Bayesian formulation of exploratory data analysis and goodness-of-fit testing (one of my favorite papers, even though it’s been only cited about 200 times, and many of those citations are by me!). I’m not claiming here that fancy models are required to do good exploratory analysis; rather, I’m saying that exploration is relative to models, and formalizing these models can help us do better exploration.
And it goes the other way, too: careful exploration can reveal unexpected data patterns that improve our modeling.
My first problem with the creative-night-science, rigorous-day-science dichotomy is that it oversimplifies the creative part of the work. In part, Yanai and Lercher get it: they write:
[M]ore often than not, night science may require the most acute state of mental activity: we not only need to make connections where previously there were none, we must do this while contrasting any observed pattern on an elaborate mental background that represents the expected. . . .
[W]hen you roam the limits of the scientific knowns, you need a deep understanding of a field to even recognize a pattern or to recognize it as surprising. Different scientists looking at a given dataset will do this against a backdrop of subtly different knowledge and expectations, potentially highlighting different patterns. Looking is not the same as seeing, after all, and this may be why some of us may stumble upon discoveries in data that others have already analyzed.
That’s good. It reminds me of Seth Roberts’s championing of the “insider-outsider perspective,” where you’re open to new ideas (you’re an outsider without an investment in the currently dominant way of thinking) but you have enough knowledge and understanding that you’ll know where to look for anomalies (you’re an insider with some amount of specialized knowledge).
But “day science” is part of this exploration too! By not using the inferential tools of “day science,” you’re doing “night science” with one hand behind your back, using your intuition but not allowing it to be informed by calculation.
To put it another way, calculation and formal statistical inference are not just about the “day science” of hypothesis testing and p-values; they’re also about helping us better understand our data.
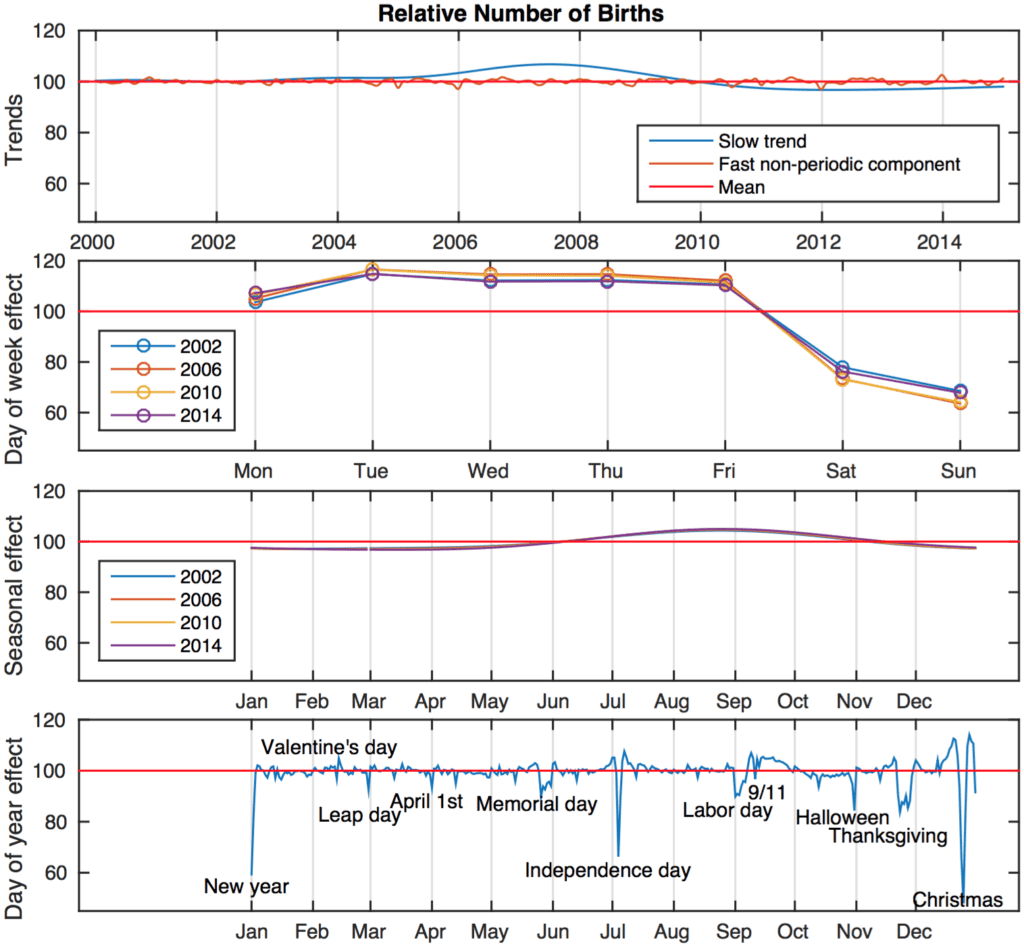
Consider the birthday example from the cover of BDA3 and pictured above. Is this “night science” (exploration) or “day science” (confirmation)? The answer is that it’s both! Or, to put it another way, we’re using the modeling and inferential tools of “day science” to do “night science” more effectively. If you want, you can say that the birthday example is pure “night science”—but then I’d say that night science is pretty much all we ever need. I’d just call it “science.”
My second problem with the night/day science framing is that it doesn’t give enough for “day science” to do. Rigorous inference is not just about testing hypothesis; it’s about modeling variation, causation, all sorts of things. Testing the null hypothesis of zero effect and all data coming from a specific random number generator—that’s pretty much the most boring thing, and one of the most useless things, you can do in statistics. If we have data from lots of different experiments with lots of different hypotheses floating around, we can do some multilevel modeling!
To put it another way: Just as “night science” can be more effective if it uses statistical inference from data, “day science” can be more effective via creative modeling, not just testing fixed hypotheses.
Science is not basketball. You’re allowed to do a moving pick.
P.S. After I wrote and scheduled this post, another person emailed me asking about the above-linked article. If 2 different people email me, that’s a sign of some general interest, so I decided to post this right away instead of on the usual delay.
This is what I wrote on Twitter:
I like the text but don’t think their own study is a good example of what they call “day science … rigorously testing hypotheses.” They declare “truth” based on statistical significance, given their wording “we found that a hypothesis-free data analysis *is* almost five times …”
But if I looked at the table and analysis correctly, had they found only 8 instead of 9 hypothesis-free students who discovered the gorilla, their results would be “statistically non-significant” and there would be no “significant liability” (in the words of the authors).
Valentin:
Speaking more generally, I strongly oppose the formulation, “rigorously testing hypotheses.” Testing hypotheses is no more rigorous than any other statistical method. The most characteristic feature of hypothesis testing is that it discards information, compressing all sorts of interesting data into a single yes/no bit of information.
One of my pet gripes about hypothesis testing is that after you find that the null hypothesis meets some level of significance you aren’t entitle to conclude that it has been verified to the the one and only correct hypothesis. There are many, maybe millions, of other hypotheses that would meet the level of significance if you queried them.
A mean of 0.000 as the null vs a mean of 0.500? How about 0.0001 or -0.002 or …? How about a mean of 0.000 if an experiment gives 0.500 but otherwise 0.75? Etc., etc., etc.
You can mostly only conclude that Hypothesis A – let’s not even call it the “null” – is fairly consistent with the data whereas Hypothesis B is not very consistent or is even strongly inconsistent. That’s not rigorously testing a hypothesis. Or maybe it can be rigorously testing that B is poorly consistent with the data, but that’s not the kind of conclusion that is normally drawn.
“You can mostly only conclude that Hypothesis A…is fairly consistent with the data whereas Hypothesis B is not very consistent or is even strongly inconsisten… “
Well said Tom!
#To put it another way, calculation and formal statistical inference are not just about the “day science” of hypothesis testing and p-values; they’re also about helping us better understand our data.#
if I may add, “…helping us better understand our data in order to reveal real-world processes generating this data”. Data is just a noisy approximation of the reality, and our ultimate goal ist to grasp the world, not the data, with whatever tools science has to offer.
PS: I am an engineer and our training makes world/model/data distinction rather obvious and we usually never engage in attempts to simplify or dispose day, night, dawn or any other science. Whatever helps our understanding of the world is welcome.
All this excitement with Hypothesis test abuse is imho not because of day/night, rather plain old cheating. Not necessarily conscious cheating, often unintended, but nevertheless cheating yourself, someone else or both.
Esad, if a bridge collapses because someone fudged some p-values, the engineer gets sued, put in jail or both. If a program to encourage healthy eating in schools fails, the social scientist gets a new data set to mine for his next proposal. Incentives!
My initial impression from their paper was that the authors were both extolling the virtues of exploration AND telling us not to pretend every single discovery was predicted a priori just because that’s the story editors want to hear. They cite one of their own papers as an example of coming up with something from exploration. I looked it up and it read like a typical confirmatory study by prescient researchers. So maybe they’re encouraging researchers to practice exploratory research as integral to science, as a method, but are fine with maintaining the conceit in the literature that it’s not, cuz that’s the cost of doing business?
I’m not saying this is hypocrisy–it’s good to offer advice to colleagues on methods, especially when those methods have been intentionally obscured in publications. And it’s not their responsibility to battle institutional cynicism, unless they want to take it. But if I’m right, Andrew, then you’re talking past each other: you’re talking about improving the institution of science and the work it produces, whilst they’re talking about a neat science trick all the cool researchers know about. Now I wanna read their paper about how you should interpret data not p-values, to clue in all those oblivious researchers fooled by all the papers whose authors interpret p-values, wink wink.