A colleague pointed me to Nate Silver’s election forecast; see here and here:
The headline number
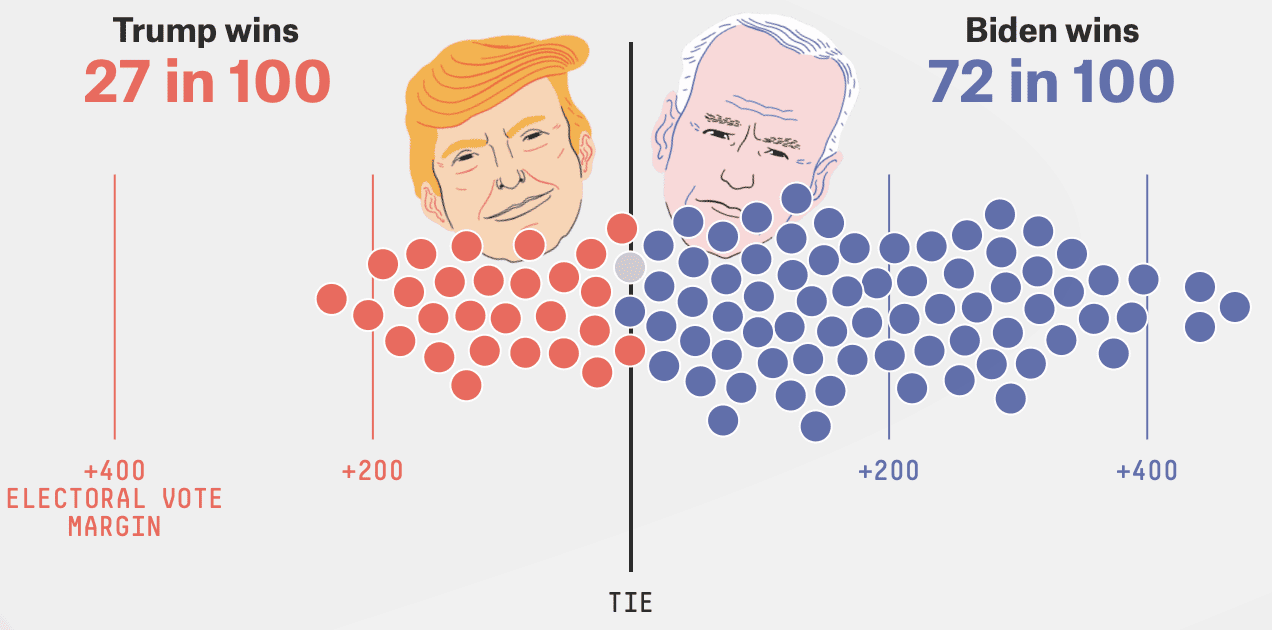
The Fivethirtyeight forecast gives Biden a 72% chance of winning the electoral vote, a bit less than the 89% coming from our model at the Economist.
The first thing to say is that 72% and 89% can correspond to vote forecasts and associated uncertainties that are a lot closer than you might think.
Let me demonstrate with a quick calculation. We’re currently predicting Biden at 54.0% of the popular vote with a 95% interval of (50.0%, 58.0%), thus roughly a forecast standard deviation of 2.0%:

As most of our readers know, the electoral college is currently tilted in the Republicans’ favor. That’s not an inherent feature of the system; it’s just one of those things, a result of the current configuration of state votes. In some other years, the electoral college has favored the Democrats.
Anyway, back to the current election . . . suppose for simplicity that the Democratic candidate needs 51% of the national vote to win the electoral college. Then, using an approximately normally-distributed forecast distribution, the probability that Biden wins in the electoral college is, in R terms, pnorm(0.54, 0.51, 0.02), or 93%. That’s pretty close to what we have. Move the threshold to 51.5% of the vote and we get pnorm(0.54, 0.515, 0.02) = 89%. So let’s go with that.
Then what does it take to get to Nate’s 72%? We want pnorm(x, 0.51, y) to come out to 72%. We know from reading Nate’s documentation that his forecast is both less Biden-favoring and more uncertain than ours. So we’ll set x to something a bit less than 0.54 and y to something a bit more than 0.02. How about pnorm(0.53, 0.515, 0.025)? That comes to 73%. Close enough.
So, here’s the point. Nate’s forecast and ours are pretty close. Take our point forecast of 0.54 +/- 0.02 of the two-party vote and tweak it slightly to 0.53 +/- 0.025 and the approximate probability of a Biden electoral-college win drops from 89% to 72%.
This is not to say that a forecast of 53% is the same as a forecast of 54%—they’re different!—nor is it to say that a forecast standard deviation of 2.5% is the same as 2%—those numbers are different too! But they’re not a lot different. Also, it’s gonna be hard if not impossible to untangle things enough to say that 53% (or 54%) is the “right” number. The point is that small differences in the forecast map to big differences in the betting odds. There’s no way around this. If two different people are making two different forecasts using two different (overlapping, but different) pools of information, then you’d expect this sort of discrepancy; indeed it would be hard to avoid.
Going beyond the headline number
To understand the forecast, we can’t just look at the electoral college odds or even the national vote. We should go to individual states.
The easiest way for me to do this is to compare to our forecast. I’m not saying our model is some sort of ideal comparison; it’s just something I’m already familiar with, given the many hours that Elliott, Merlin, and I have been staring at it (see for example here and here).
I decided to look at Florida, as that’s one of the pivotal states.
We give Biden a 78% chance of winning the state, and here’s our forecast of the two candidates’ vote shares in Florida:

What’s relevant here is the bit on the right side of the graph, the election day prediction.
And here’s what fivethirtyeight gives for Florida:
From this image, we can extract an approximate 95% predictive interval that the vote margin will be between +14 for Trump and +18 for Biden. Mapping that to the two-party vote share, that’s somewhere from 43% and 59% for Biden. It’s hard for me to picture Biden getting only 43% of the vote in Florida . . . what does our model say? Let me check: Our interval is much narrower: our 95% predictive interval for Biden’s share of the 2-party vote in Florida is approximately [46.5%, 58.5%] (I’m reading this off the graph).
I can’t give you a firm reason why I think 46.5% for Biden is a better lower bound than 43%—after all, anything can happen—but it’s helping me understand what’s going on. One way that the fivethirtyeight forecast gets such a wide national interval is by allowing Biden to get as low as 43% of the two-party vote in Florida. Or, conversely, one reason our model gives Trump such a low probability of winning is that it effectively rules out the possibility of Biden getting as low as 43% of the Florida vote (and all the correlated things that go along with that hypothetical outcome).
OK, let’s check another: Fivethirtyeight gives Trump a 2% chance of winning Connecticut! In contrast, our probability is less than 1%.
How the forecasts work
In some sense, there’s only one way to forecast a presidential election in the modern era. You combine the following sources of information:
– National polls
– State polls
– State-by-state outcomes from previous elections
– A forecast of the national election based on political and economic “fundamentals”
– A model for how the polls can be wrong (nonsampling errors and time trends in public opinion).
– Whatever specific factors you want to add for this election alone.
That’s it. Different forecasts pretty much only differ in how they weigh these six pieces of information.
We’ve discussed our forecast already; see here, here, and here, and our code is here on Github.
On his site and in a recent magazine interview, Nate discusses some differences between his model and ours.
Nate writes that his model “projects what the economy will look like by November rather than relying on current data.” That makes sense to me, and I think that is a weakness in our model that we don’t do that. In this particular case, it’s hard to see that it matters much, and I don’t think it explains the difference between our forecasts, but I take his general point.
He also writes, “Trump is an elected incumbent, and elected incumbents are usually favored for reelection,” but that seems to miss the point that Trump is an unpopular incumbent. Also he says he analyzed elections back to 1880. That doesn’t seem so relevant to me. Too much has changed since then. For one thing, in 1880, much more of politics really was local.
And he writes, “COVID-19 is a big reason to avoid feeling overly confident about the outcome.” I guess that explains some of the wide uncertainties resulting in that possibility of Biden only getting 43% in Florida.
And he writes that, his model “is just saying that, in a highly polarized environment, the race is more likely than not to tighten in the stretch run.” That does not explain that Florida prediction, though. But I guess if you start with our forecast of Florida getting 52.4% in Florida, and you pull that toward 50/50, then it will pull down the low end of the interval too, resulting in that 43% lower bound. Also, as of when the model was released, there was still a chance that Biden would pick Fidel Castro as his running mate, so the prediction had to include that possibility.
One thing that Nate doesn’t mention is that they model individual districts in Maine and Nebraska, and we never bothered to do this. Not a big deal, but credit where due.
Graphical displays
The fivethirtyeight page has some innovative graphical displays. There’s an image showing a random forecast that updates at occasional intervals. I guess that’s a good way to get repeated clicks—people will go back to see how the forecast has changed?
I don’t really have strong feelings about the display, as compared to ours. I mean, sure, I like ours better, but I don’t really know that ours is better. I guess it depends on the audience. Some people will find ours easier to read; some will prefer theirs. I’m glad that different websites use different formats. I’m assuming the New York Times will again use its famous needle display?
The fivethirtyeight page has time series graphs that go back to 1 June. Ours go back to the beginning of March. Both of these are anachronistic in going back to before the forecasts were actually released. But they’re still helpful in giving a sense of how the methods work. You can see how the forecasts are moved by the polls. I’m not sure why they don’t go back to March. Maybe not enough state polls? Or maybe they felt that it didn’t mean much to try to make a forecast that early.
I particularly like how our graphs of vote share show the forecast and the individual polls over time:
I recommend that fivethirtyeight try this too. Right now, they have time series graphs of the forecast vote shares and then a table listing state polls, but the polls haven’t made their way to the graph yet.
The fivethirtyeight site gives letter grades of the A/B/C variety to polling organizations. We don’t assign letters, but we estimate systematic biases (“house effects”) and their uncertainties from the data, so I guess the overall effect will be similar. I’m not quite sure how fivethirtyeight combines information from national and state polls, but I’m sure they do something reasonable.
They smooth their electoral college forecast (“smoothed rolling average”). That makes no sense to me at all! The electoral college really is discrete; that’s just the way it is. No big deal, it just seems like an odd choice to me.
And they’ve got a logo with a fox wearing glasses and headphones. I don’t know whassup with that, but as the coordinator of a blog with the epically boring title of Statistical Modeling, Causal Inference, and Social Science, I’d certainly claim no expertise in brand management!
P.S. Nate also has an online interview where he’s pretty complimentary about our model (as he should be; as noted above, we’re all using similar information and getting similar conclusions) but at one point he unleashes his inner Carmelo and knocks our process:
[Elliott] Morris also says, well, this poll isn’t doing education weighting, or this is a robo poll, so we’re not going to include it. I want to make as few subjective decisions as possible. I want a good set of rules that generalize well, and we’re pretty strict about following those rules. Sometimes a pollster will write us and say, hey, we intended our poll to be interpreted this way, and you’re doing it that way. Well, I’m sorry, but we actually have a set of rules and they’re here on the site. And we have to be consistent.
That’s just silly. We have rules too; they’re just different from Nate’s rules! Also the rules we use are not what Nate said to that reporter. I’m sure why he thought this, but actually I think the only polls we have excluded so far are HarrisX and Emerson College polls, because of biased questionnaires and bad data quality. For better or worse, data quality matters. Otherwise where do you draw the line: what if my cousin who went to prison for fraud were to start promoting an election poll, would I have to include that just out of a concern about making subjective decisions? Of course not.
I’m not sure how important each of these rules is to the final prediction—there are enough solid national polls that the final results are pretty stable—but from a conceptual standpoint, and with 2012 and 2016 in mind, our most important polling adjustment is to treat polls that adjust for party ID as baseline and allow for a time-varying bias of polls that don’t adjust for party ID. That’s there to allow for partisan nonresponse bias. The importance of adjusting for education also comes from what happened in midwestern states in 2016.
Speaking more generally, it’s hard for me to know what to make of a statement such as, “I want to make as few subjective decisions as possible,” in this case. Here are some further thoughts on subjectivity and objectivity in statistics.
P.S. Let me just clarify my first point above in response to an online comment from Nate. I’m not saying that 72% and 89% are close in probabilistic terms. I agree that there’s a big difference between 8-1 odds and 3-1 odds. What I’m saying is that the large difference in these probabilities arises from small differences in the forecast distributions. Changing a forecast from 0.54 +/- 0.02 to 0.53 +/- 0.025 is highly consequential to the win probability, but as uncertainty distributions they are similar and they are hard to distinguish directly. You can get much different headline probabilities from similar underlying distributions. That’s one reason I was looking into specifics such as the Florida forecast. The fivethirtyeight forecast gets wide uncertainties in the national forecast by having wide uncertainties in individual states. That doesn’t mean their Florida forecast is wrong, just that it’s part of the larger picture of their prediction.
I wonder how much the focus on “election day” should change given the possible increased orevalence of mail-in ballots. In 2016, Trump’s polls were worst after the TV debates, and then worked their way back up towards election day. If they’re hoping for a similar strategy this year, then mail-in ballots, with voter decisions made days or weeks in advance of election day, would negate any last-minute gains in standing. (In that light, instilling fear into undecided voters that mail-in ballots might be considered inferior in an attempt to make them vote at the polls on election day makes some sense.) Do the forecasts factor the percentage of mail-in votes and the earlier decision dates for those into their models?
Maybe we even need a 95% confidence interval for the date of the election day!
My understanding is the polls themselves factor this in. One of the questions they ask is something to the effect of, “have you already voted, if so for whom?” So once a segment of the vote is locked in via voting early, that vote preference is locked into the polls too.
@Justin This isn’t the relevant point. No one has voted yet. But lots of people will have voted by the end of September, roughly halfway to the offical election day. So, there is less time for them to change their minds than Nate Silver seems to imply when he talks about his model.
So, once early voting is undewrway, should polls be weighted by the proportion of voters who’ve already cast their vote?
> They smooth their electoral college forecast (“smoothed rolling average”). That makes no sense to me at all! The electoral college really is discrete; that’s just the way it is. No big deal, it just seems like an odd choice to me.
That makes easier to estimate visually the area under the curve (i.e. the probability of one or the other winning). They are not replacing the raw histogram but adding that “smoothed rolling average” as an overlay, it doesn’t seem so bad.
Not that I have insight into the specific inner workings of either model, but I imagine that a fair amount of the difference between yours and Nate’s is that last element you listed, “whatever specific factors you want to add for this election alone”. I won’t question Nate too much since he seems to do good work and has a good track record but part of what they added this year compared to previous elections is uncertainty due to COVID and related general weirdness in our current times. They have measures for that and say they back-tested it and whatnot but it kind of feels like they added uncertainty to the forecast to tighten the numbers a bit and just waved their hands toward a reason.
As for their graphics, what you have now looks very much like what they use for things like approval polls. projects.fivethirtyeight.com/trump-approval-ratings
Alex:
Yeah, they should add dots for the individual polls on their approval ratings plots too! Seems like pretty much a free improvement. Also with their graphics skills, they could set it up so you could click on the dots to get details for individual polls.
I’d like to see the legend include the dots for the polls. Right now you have two bright circles labeled “Modeled Two-Party Vote”. But there are no bright circles in the graph. Then you have dim circles, but they aren’t included in the legend. I suppose that they are the polls, but then they wouldn’t be “modeled votes”. Without a legend or caption, I can’t tell if those dim circles are supposed to be polls, individual runs of the model, or what.
For us red-green or blue-yellow colorblind people, than goodness that the two parties’ colors have somehow become red and blue instead of red and green or yellow and blue!
I think Alex was saying that they already have the dots for the approval ratings:
https://projects.fivethirtyeight.com/trump-approval-ratings
Jeff:
That’s weird. When I copy the link from Alex’s comment and put it in my browser, I see a time series of approval ratings with no dots. When I click on the link from your comment, I see the time series with dots included. And they’re the same url! I have no idea what is going on here.
I think clicking betweeen the tabs ‘Today’ and ‘4 years’ makes disappear and return
I wasn’t talking about 538’s graph. I was talking about the graph on this blog post, https://statmodeling.stat.columbia.edu/wp-content/uploads/2020/08/Screen-Shot-2020-08-13-at-7.59.45-PM.png, introduced by “We give Biden a 78% chance of winning the state, and here’s our forecast of the two candidates’ vote shares in Florida:”.
Why did you do this:
How about pnorm(0.53, 0.515, 0.025)? (~72%)
Instead of this:
How about pnorm(0.53, 0.51, 0.035)? (~72%)
By doing the former aren’t you inducing a third difference (a different EC advantage)?
I see the problem. In text your wrote that you switched the EC advantage to 51.5%, but in code (what I was reading), you wrote:
pnorm(0.54, 0.51, 0.02) = 89%
I think this is a typo. It should be:
pnorm(0.54, 0.515, 0.02) = 89%
Because there’s a typo in his first first (second?) statement:
pnorm(0.45, 0.515, 0.02): ~89%
whereas
pnorm(0.45, 0.51, 0.02): ~93%
Andrew does first say the 93% and then in the text says to move the threshold to 51.5%, but does not update the pnorm formula when restating it:
“in R terms, pnorm(0.54, 0.51, 0.02), or 93%. That’s pretty close to what we have. Move the threshold to 51.5% of the vote and we get pnorm(0.54, 0.51, 0.02) = 89%”
Yes, typo fixed, thanks for pointing this out. That’s a problem with my worklow of copying-and-pasting code rather than doing full markdown!
> the only polls we have excluded so far are HarrisX and Emerson College polls, because of biased questionnaires and bad data quality.
Oh I’d love to hear this story.
If we have a normal election it’s hard to imagine that the outcome is in doubt.
The bigger issues are hard to include in any model but:
1) what’s the probability that election day doesn’t happen?
or:
2) serious tampering happens (direct or backdoor means, such as messing w/ USPS)?
There are some slight noises being made about this stuff but it’s not enough.
That’s like modelling card probabilities when you’re playing against Bugs Bunny.
Yeah, I get that.
But I throw it out there because we’re talking about the 2020 election and it’s a serious concern. We need serious people to focus on it.
jim –
> 2) serious tampering happens (direct or backdoor means, such as messing w/ USPS)?
Not clear where it’s going longer-term or even what the effect might be (i.e, a backfire effect if people get their SS checks late?), but that happening is looking less and less like an uncertainty:
https://www.vice.com/en_us/article/pkyv4k/internal-usps-documents-outline-plans-to-hobble-mail-sorting
Actually at first I was *extremely* fried about that. But then even some NPR commentators acknowledged that there’s a legit reason: first class mail volume has been and still is falling through the floor.
jim –
> But then even some NPR commentators acknowledged that there’s a legit reason: first class mail volume has been and still is falling through the floor.
I”m not sure that stacks up as a reason for the policy changes to be implemented at this particular point in time. Eve if, overall, it increases efficiency it still might have a particularly negative impact along a particular metric – people’s ability to vote.
Do you conclude that this isn’t happening because of a political motivation for voter suppression?
That’s a prediction you can make, but to be clear, it’s very divergent from 538 (and I’d assume The Economist’s) forecast.
Nate specifically wrote a long paragraph saying how this model is conditioning on the fact that democracy generally proceeds like it has in the past, i.e. no unprecedented interference. Gelman never made that statement explicit, but nowhere in his model does he try and account for that.
Wondering what these probabilities are is fair, but there’s little point in Gelman or Silver chiming in, none of their skills would be relevant at that estimation. But it’s important to note that “hard to imagine the election is in doubt” goes right against the 538 forecast. You might just disagree with Nate, but he thinks the election is very much in doubt, even in reasonable circumstances.
1) is basically zero. The US system is actually really hard to alter to that degree. Also, if there’s no election, IIRC Pelosi automatically becomes President on Inauguration Day.
There is no *way* Trump has enough support to get around this. I don’t think any US president in the remotely modern era could, but if there were one, it certainly wouldn’t be him!
>>If we have a normal election it’s hard to imagine that the outcome is in doubt.
All else being equal, yes, but all else might not be equal.
The one big caveat I see is if other nations start vaccinating their population by October, and then we do, and *Trump gets credit for cutting through bureaucratic red tape to get it approved*.
Just a vaccine approval wouldn’t be enough, though, IMO.
And actually, the “outcome might be in doubt” in at least one other way: what if either candidate catches COVID? If one candidate is in the hospital on Election Day (or during early voting), that could swing the vote, potentially.
This is just crystal-balling, but I think both of those probabilities are well below 1%, so probably not enough to influence things.
I’m more interested in the trend for polling to underestimate Trump support. I think that was a factor last election, and I think it might be a much bigger factor this time. I wouldn’t be surprised if there was a two point shift in results from that alone. I don’t know how you could sensibly forecast that, though.
What would be the cause of the underestimate? Are people afraid to say they support Trump or will vote Republican? Are they wavering or undecided? If they’re switching at the last minute, why are they doing that?
Keith:
In 2016, polls underestimated Trump support in some states, not others. I think the underestimation came from nonrepresentativeness of the sample; see discussion in this article.
Keith –
> I’m more interested in the trend for polling to underestimate Trump support.
For the most part, the error in the polling was within the margin of error. My understanding (and I would appreciate being corrected if I’m wrong) is that the larger error in predictions for the overall outcome came from underestimating the chances for an overall alignment of direction of error – and in particular among a key set of swing states.
My guess is that you think that there is a “shy Trump voter” effect? If so, do you have an evidence basis for believing that to be true? I’ve seen some arguments that there isn’t such an effect.
-snip-
Were there any possible factors for which you didn’t find evidence?
Yes. Take the hypothesis that there’s a segment of the Trump support base that does not participate in polls. If that’s true, that’s a huge problem for organizations like ours, and we need to study that and understand it if we’re ever going to fix it. But we looked for evidence of that, and we didn’t find it.
If it’s true that we’re missing a segment of the Trump support base, we would expect to find – without doing any fancy weighting, just looking at the raw data – that people in more rural, deep-red parts of the country would be underrepresented. And we didn’t find that; if anything, they were slightly overrepresented. We did a number of things with a critical eye looking for those types of problems, and did not find them. And so that gave me real reassurance that fundamentally, it’s not that the process of doing polls was broken last year.
-snip-
https://www.pewresearch.org/fact-tank/2017/05/04/qa-political-polls-and-the-2016-election/
And
–snip–
The bottom line is that Trump did better than the polls predicted, but he didn’t do so in a pattern consistent with a “shy Trump” effect. It’s more likely that polls underestimated Trump for more conventional reasons, such as underestimating the size of the Republican base or failing to capture how that base coalesced at the end of the campaign.
–snip–
https://fivethirtyeight.com/features/shy-voters-probably-arent-why-the-polls-missed-trump/
Do you have reasons to doubt these analyses? If so, what are they?
> I think that was a factor last election, and I think it might be a much bigger factor this time.
“I think it might be” is a pretty broad statement. Do you think it will be? If so, on what evidence do you base that opinion?
The points about data quality from polls made in this post seem very relevant. Thinking ahead a little, it seems that in future election forecasters will be pushed to have public statements on show about why they include some polls and not others.
As for the differences between the two models discussed, I feel like a lot of work is done by this statement:
“– Whatever specific factors you want to add for this election alone.”
Nate Silver continuously warns about the dangers of p-hacking and overfitting to historical data, in my view so that he can make a claim that forecasters *need* to have real-world experience of publishing forecasts of elections, in public, over and over again, before they can have anything worth saying. I’m not sure this is completely true. Presumably this attack helps to de-legitimize competing forecasts. But it seems to me that mathematically, a test set can be historical data as well as unseen future data. Statistical theorems are true independent of the time that the data was collected.
Practically of course, it might be that raw “experience” matters. But if so then why not just come out and say that?
Henry:
It’s my impression that Nate is too focused on state polls, which is why his Florida interval is so wide—he’s not fully accounting for all the information in the national polls as well. The background here may be that Nate started by analyzing polls from primary elections, where you can’t do so much pooling of information from different states. I think we can dismiss his statements about subjectivity and objectivity as Carmelo-style trash talk, but I agree with you on the general point that data quality is an issue.
> What I’m saying is that the large difference in these probabilities arises from small differences in the forecast distributions. Changing a forecast from 0.54 +/- 0.02 to 0.53 +/- 0.025 is highly consequential to the win probability, but as uncertainty distributions they are similar and they are hard to distinguish directly.
For those who may wonder what the distributions look like (vertical line at 0.515): https://imgur.com/a/5bo9Mjk
The part of the 538 model that I’m baffled by is the inclusion of number of full-width NYT headlines as a source of uncertainty (more about the election = higher uncertainty). In the methodology, it is justified by linking to a single tweet where Nate screen shot his stata output. I haven’t seen a full justification for this yet, but I think it’s being used as a considerable source of additional uncertainty (which certainly seems subjective, a criticism he loves to lob at others). I’d be interested to know what others think of that piece.
As for Emerson and HarrisX, I fully support the decisions to not include those. When I was de facto head of the team running HuffPost Pollster, we had to make decisions all the time. I chopped Rasmussen for lack of methodological transparency, and Gravis + Emerson for only calling landlines with IVR. Emerson has since added MechanicalTurk sample… which I also find completely inadequate. That’s the data quality issue there. I presume with HarrisX it’s the biased questions.
Thanks again for good, public discourse on this that is not restrained to 280 characters.
Natalie:
Yeah, polls are scary! The closer you get to them, the more you can notice their imperfections. Elliott can provide details of why he excluded HarrisX and Emerson, but, yes, I think it was question wording in one case and the use of MTurk in the other.
Andrew and Natalie,
Yep, we excluded Emerson because they use MTurk, and HarrisX because of both shady data transparency and writing clearly biased questionnaires (maybe we can chalk this up to a Penn factor). The and is important because it shows they’re not just getting a bad sample but that they don’t really care.
Now that I’m more awake, I also looked at our rules (nb Nate S, not “subjective” criteria) and we also exclude numbers from John Zogby and American Research Group for similar transparency reasons. We keep Gravis because, though IVR is crappy, at least they pick up the phone and tell us what is going on.
I really don’t know what to do about Rasmussen. They list most of the info on their site, but the underlying demos are clearly all wacky. I’m not convinced it’s enough to say “this poll looks weird,” though; I feel the need to base the exclusion on other factors too. Weird data happens all the time!
On the other hand, if your poll is routinely biased toward Trump by 5-10 points, and it jumps around wildly by nearly as much, that suggests both that is has more error than you can remove by just adding a house effect and that it will probably add less value of the estimate because of increased measurement error.
Yea, I’d love to see the analysis he did to determine how to weight that because I do think the 538/Economist uncertainty difference is a little larger than Andrew’s illustration implies.
I think that Andrew’s examples above undersell the uncertainty difference a bit. The Trump EC advantage is looking closer to 2 points than the 3 he used in his final example. So to fit the two models probabilities you would need:
Econ: pnorm(0.54,0.51,0.025)=89%
538: pnorm(0.53,0.51,0.035)=72%
That would imply an increase of 40% in the assumed SD vs the 25% needed in Andrew’s example.
That said, I take Andrew’s point that it doesn’t take much of a parameter difference to explain the probability difference. I could totally believe that both the 2.5% and 3.5% uncertainties are within the uncertainty in the uncertainty (or 2% vs 2.5% in Andrew’s examples).
Andrew –
You say:
> And he writes, “COVID-19 is a big reason to avoid feeling overly confident about the outcome.” I guess that explains some of the wide uncertainties resulting in that possibility of Biden only getting 43% in Florida.
Nare says:
> Take what happens if we lie to our model and tell it that the election is going to be held today. It spits out that Biden has a 93 percent chance of winning.
I’m curious how your model would estimate the probabilities if the election were held today? Is there some way for me to check that directly as time goes on? I’m assuming, of course, that if I look at the Economist website, when I see “Chance of winning
the electoral college” it projects the probabilities forward to actual election day. I wonder if one major difference might be that the 538 forecast has a bigger difference between the “if he election were held today” and “when the elections takes place” estimates than your forecast?
…Nate says…
Andrew –
Related…your projections for popular vote %’s change from Biden at 54.5% today to 54.1% on election day. The drop is obviously very small, relatively, but I’m curious if you have a general sense for why it changes? I”m assuming it’s not just random variation?
It’s partially pooling toward the fundamentals-based prediction.
Further, the 538 interface makes this hard to see, but it seems the 538 prior is moving things even more strongly towards 50%. Their current national polling average is +8.5 Biden which would point to a two-party vote of 54.25%-45.75%, but the projection is 53-46. Some rounding is obviously happening there, but regardless 538 seem to be expecting more than a 1% shift in the vote share vs. less than half a point for the Economist.
Joshua:
The projections of model today correspond to our estimates of today’s public opinion, which pretty much corresponds to what we think would happen if the election were held today (although this is kind of a weird way to think about it, given that people know the election will not be held today).
Andrew –
> which pretty much corresponds to what we think would happen if the election were held today.
Excuse my simplistic understanding, but…
So then is it true there is a very big difference, in that for your forecast there isn’t much change between “if it were held today” and your overall estimate, as compared to a big change in the 538 forecast? If so, wouldn’t that be a really big difference and the easiest way to see that they build in a lot more uncertainty?
My understanding is equally simplistic, I guess. If the uncertainty in the current state leads to +/-x, the uncertainty in the future state should (at least usually) be larger. Events between now and November could move things either direction. Imagine some kind of uncertainty multiplier for each electoral district, with the multiplier decaying towards unity as Election Day approaches…I don’t know how one would estimate what it should be right now, but it wouldn’t be 1.00000.
On the off chance that the election turns out to be wildly different from what either model currently indicates, what will be the most likely justifications, excuses, and assertions made by the polling experts? Is any statistical model for a future election flexible enough to include the possibilities of an outbreak of war, assassination(s)or candidate heart attacks?
>> Is any statistical model for a future election flexible enough to include the possibilities of an outbreak of war, assassination(s)or candidate heart attacks?
Wasn’t it said in an earlier post that the model assumes Trump and Biden are in fact the candidates?
Could you respond to Nate S/Nate Cohn’s critique of your model’s backtesting strategy? In short, the Nates think testing the model against past elections is foolish.
Nate Cohn called G Elliott (and by association, you) deluded because you use oos cross-validation to test the model’s viability.
See the thread here https://twitter.com/Nate_Cohn/status/1293602797196369922
and https://twitter.com/NateSilver538/status/1293610859126755330
And Nate’s longer reply here https://thecrosstab.substack.com/p/what-makes-a-model-good-august-9
And
Last, what do you think about creating an “uncertainty index” as a bag of indicators?
Anon:
Nate Cohn wrote to Elliott Morris: “I think you’re overfitting models on a small dataset and using regularization and out-of-sample cross-validation to delude yourself into thinking that’s not what your doing.” I don’t think Elliott, Merlin, and I are deluding ourselves. We know that we’re fitting models on a small dataset and using regularization and out-of-sample cross-validation! Are we “overfitting”? That I don’t know. “Overfitting” is just a word. We’re doing our best, that’s all.
Nate Silver wrote, “Given the nature of election data, you don’t want do to too much optimization.” I agree. You should never do too much of anything.
One thing that I’ve been thinking about is that when people talk about being conservative and not overfitting, in practice this can mean that they’re relying really heavily on the experience of 2016. Then what they’re doing is overfitting to 1 data point.
Finally, sure, I think that using an “uncertainty index” can be a good idea. No model can contain everything.
I mostly agree with this, except for the part about “Overfitting” being just a word. I mean, of course there is a literal sense in which it is just a word. But it is a word that is intended to represent a concept. The word “overfitting” is just a word, but overfitting is a real phenomenon.
Overfitting is bad.
Unfortunately, underfitting is also bad.
Nate can say you’re overfitting, and you can say he’s underfitting. Or maybe you are both overfitting or both underfitting. More likely, you are both overfitting in some ways and underfitting in others. Indeed, I would say that’s about the best you can hope for! It’s not like you can expect to fit exactly the right model in exactly the right way. I have often pointed out to my colleagues, and sometimes to my clients, that it is unrealistic to have the goal that your estimate is exactly right; what I am aiming for is not knowing which way it’s likely to be wrong.
Anyway, I’m not saying it’s worth arguing about this, I’m just saying that if you’re arguing about whether you’re overfitting, you aren’t arguing about a word but about a concept.
Phil:
Yes, you’re right. I actually would not say that Nate is underfitting; rather, I might say that he’s overfitting to 2016. Or maybe that corresponds to underfitting to earlier elections. To the extent that he’s basing his decisions on data going back to 1880 (and I guess he is; otherwise why would he mention it?), I think he’s overfitting to those past data which I don’t are relevant to what’s going on now.
Thanks for the reply, Andrew.
Could you say more why you think your strategy makes sense vs. Nate’s? Why is cross-validation on a small sample a good idea here and why is Nate Cohn incorrect when he says you’re delusional? I don’t think the Nates are correct here in the sense that we’re talking about the differences in approach vs. the side effects of some kind of psychological defect. But I am wondering if there is a way to further unpack this to explain the modeling reasoning.
Fwiw, I think CV/oo sampling is reasonable because you’re taking an approach that says there is signal in past elections and in the covariates of those elections in predicting the outcome that are relevant to the current election. That seems.. reasonable. The idea that, according to Nate Cohn, if you are interested in weather forecasting, this becomes a foolish predicate, just doesn’t add up for me. The fact he doesn’t unpack his argument much further tells me his reasoning isn’t all that deep, beyond just saying the CV sample is small. But Nate C. has a lot of very smart ideas about polling so I’m wondering if there’s more to say here that I’m missing.
Anon:
The “delusional” thing is just silly. Elliott knows what he’s doing! Regarding our strategy vs. Nate’s: there are a bunch of differences. The clearest differences is how we’re handling the polls: we’re including state and national polls, allowing nonsampling error and time trends using a hierarchical Bayesian model (you can see details in our Stan code). I’m not quite sure what Nate’s doing but I think it’s some sort of weighted average, and that sort of thing becomes tricky when you’re trying to juggle many sources of uncertainty and correlation. Regarding the prior or fundamentals-based model: there’s no agreed-upon way to do this. I respect that Nate’s doing what he thinks is best, but ultimately N is small and you have to make judgment calls and state your assumptions clearly.
As to cross validation, that’s not such a big deal one way or another. No matter how you slice it, you’re gonna be trying out different models, fitting them to past data, and looking to see what they imply for the current election. Cross-validation is just one way of assessing that fit: it’s neither perfect nor horrible. Cross validation is just one more tool. I don’t agree with Nate that there’s useful signal going back to 1880, but I do think there’s signal in past elections, of course. Indeed, I feel that the people who would deny the value of past elections are overfitting to a single past election, 2016.
Sweet, you’re getting me excited about the election.
I heard some questions at Stan-con last night about using different methods in different application areas. Comparing methods is like comparing apples and bicycles. Would I eat a bicycle? I could try, but it wouldn’t work very well. Would I use an apple as transportation? I wouldn’t get very far. But they’re both extremely useful.
Similarly, if you think that a bicycle is useless, it probably means you don’t know how to ride it. If I was a whale from mars, and I came to earth not knowing what a bicycle was because I don’t have legs, then a bike would be pretty useless to me.
I think it’s important to think about application area more than the method itself. Certain methods have been used successfully in certain application areas for years.
“The relative probability of this or that arrangement of Nature is
something which we should have a right to talk about if universes
were as plenty as blackberries, if we could put a quantity of them
in a bag, shake them well up, draw out a sample, and examine them
to see what proportion of them had one arrangement and what
proportion another. But, even in that case, a higher universe
would contain us, in regard to whose arrangements the conception
of probability could have no applicability. ” Peirce.
Now substitute “outcome of an election” for “arrangement of Nature” and “elections” for “universes.
Prof.,
I’d wager the newer fox logo is inspired by the Hedgehog (top-down big theory) vs. Fox (eclectic generalist) dichotomy popularized by Philip Tetlock.
Question is: is that a stated preference or revealed preference?
And the instance in which the fox is wearing headphones wants to draw attention to the podcast. And glasses = smart, obvs.
Jeff,
Obv, Cool as a fox :)
Chetan:
The fox and hedgehog thing long preceded Tetlock! Also see here.
Certainly. I originally encountered it in Isaiah Berlin’ book. Only meant that Tetlock popularized it in the TED/ Long-Now talk circuit in the 2000s.
Colossal waste of time and energy to try to play along with the battle of the prediction models.
Polling is Broken, not longer just biased and unreliable.
Until that’s fixed (impossible), Nate Silver, Sam Wang, Princeton bla bla bla are as useful as the National Enquirer when trying predict the presidential election.
Too much at stake for those seeking to protect or attain the power and riches that come along with victory to expect fairness and honesty from them.
Pasquale:
You could be right. I work on many projects, and I accept that some of them will be a waste of time. That’s the nature of research.
Pasquale –
> Too much at stake for those seeking to protect or attain the power and riches that come along with victory to expect fairness and honesty from them.
Could you elaborate on what you think is a manifestation of dishonesty?
Politifact discussion of
1. Biden lies
There are some real hooters in there, high recommended.
Not like anyone needs it, but for balance’ sake:
2. Trump lies
Bingo, frankly Andrew is way to smart to not realize this…
The purpose of polling is not to measure public opinion, rather to shape opinion…
If you care about prediction focus on running your only objective polling not playing with fun models..
Does your overall model work like a weighted average of (fundamental prediction) and (poll time series model) or does the time series model have a non-unit root and bias towards the fundamentals? Both make sense as modeling strategies, but a state level model like
[state_mean_it = state_mean_it-1 + phi*(state_fixed_model_i – state_mean_it-1) + u_it ] and [correlated u_it across i based on state-level factors] and [model for varience of u_it] and [national_mean = weighted sum of state means] captures some of the dynamics he’s talking about where 1) based on partisanship and other “fundamental factors” there is an attractor that you expect the polling to hover around and 2) polls may not have a unit root on any scale, i.e. many changes in polling are ephemeral and over time people forget and revert to their partisan tendencies. I guess this a restatement of the prior debate where the big question was “do polls mean-revert” except with a specific model for the mean they’re reverting to. There is (I think) justification for pure mean-reversion since politicians can change their message depending on the current polling.
I am also very skeptical of extending fundamentals models much further into the past. The measures of interest are only vaguely available, so of course they perform less well.
Ryan:
The fundamentals model gives a multivariate normal prior (with a wide variance) for the vote in the 50 states on election day. The polls are informative about current opinion (we also include allow for nonsampling error in various ways). We have a time series model for trends in public opinion during the campaign. Regarding the mean-reversion thing, see this discussion.
I will try to introduce some precision; to make precise a distinction between two sets of concepts which abound in talk of prediction of elections, and which I believe are commonly conflated. The first is the “prediction of the outcome” and the second is the “probability of the predicted outcome”. Sometimes the matter is further muddied insofar as the prediction is itself represented as a probability. I will try to make my point clear by indicating how, in the most elementary and severely idealized ground possible – namely urn models of simple surveys – the terms above can be made quite unambiguous. The argument holds a fortiori for less idealized and more complex models of greater realism with many internal degrees of freedom.
If an election were to be held tomorrow and “prediction” meant simply no more or less than an accurate ascertainment in advance of the counts in two categories “A” and “B” (e.g. “pro” or “con”) then if it were possible to [1] survey every individual voter today; and [2] we knew on the basis of prior experience or – what ought amount to the same – some iron psychological law that the voters in this district always respond truthfully and moreover do not change their minds; then our complete enumeration today would constitute a prediction of the outcome tomorrow, and one in which would be be justified in regarding as certain. In this situation – of complete enumeration of truthful voters – we would be justified in attaching probability of “1” to our prediction; but doing so would amount to a superfluous embellishment given the peculiar ground in which our survey was done. Let us say that the total number of votes is N, the sum of A and B; and that A is to win so that A is greater than B. We make our “prediction” that A wins with (A of N) of the votes and to this prediction we attach a probability statement: our survey procedure (with all its attendant assumptions) tells us we may regard this prediction as certain – we may as well say “Our prediction comes with an error probability of 0”. We may as well say “The probability that A wins with (A of N) is 1”. But it must be understood that the probability of which we speak has its ground in the nature of our sampling procedure; and our strong assumptions about the behavior of the voters.
Let us take a small but significant step in the direction of realism. Suppose that the voters are still known to be truthful when they respond on Monday; and that they do not change their minds before they vote on Tuesday (both these on the basis of long prior experience with voters in this district or – what amounts to the same – from understanding of some ‘iron’ psychological law which holds good for the folk there). We also suppose that all who respond on Monday are able to vote on Tuesday – that no one fails to cast a vote, by reason of illness or indisposition; and that all votes are indeed counted; and that moreover the count itself is not subject to error. These are many caveats and they are preposterously unrealistic. But holding that aside, we bring in the essential degrees of freedom without which a realistic survey cannot be described. That is sampling variation. We do not survey all the voters, rather we survey n smaller than N. And this survey sample is partitioned into two groups n , the sum of a and b. Under the same conditions as above, the only plausible prediction is that A will win a fraction (a of n) of the total votes. If (a of n) is greater than (b of n) we are compelled to “predict” that A will be the winner.
But having introduced the smaller sample n we cannot assert with complete confidence as before that if a is greater than b then it will be the case tomorrow (all our assumptions holding good: the truthfulness, veracity, ability and longevity voters; and the reliability of the vote-counting) that A will be grater than B. For there is the possibility of reversal. In this idealized setting we can quantify the probability of reversal by counting the number of ways we may query n individuals falling into two categories: a A’s from b B’s from a total population of N. The number of such selections is (A,a)*(N-A,n-a) [I have written the combinatorial coefficient sideways because of typographical limitations]. And the number of such selections which represent a reversal are simply those for which a are less than n – a: i.e. for which a is less than half-n. If we regard our survey as one among many parallel surveys of exactly the same design on that same Monday afternoon, on any reasonable interpretation of the word “probability”, we may quantify the degree to which such a reversal occurs by the sum of terms for all a greater than half-n of the hypergeometric probability (A,a)*(N-A,n-a) divided by (N,n). The upper limit of this sum depends on the order in which the four numbers n, half-n, A, N stand in relation to one another; and a careful attention to this reveals that the problem breaks down into a handful of cases. Put another way, the propensity for our survey of size n to not suffer from reversals depends to some extent on how the sample size n stands in relation to the (unknown) outcome count A.
For definiteness call this probability of reversal R = p( A less than B given: a greater than b; a,n,A,N).
Note that the parametric dependencies (a,n,A,N) after the “;” cannot be dispensed with.
Now say on Monday evening we predict “A” will achieve a fraction (a of n) of the votes and if that fraction is greater than (n-a) of n we predict that “A” will win. We also attach to our prediction a quantification of the uncertainty which goes along with it. This is the reversal probability “R”.
We may give our prediction as follows: “The prediction of A’s share is (a/n) and the probability that A wins is the non-reversal probability 1 – R. When one says “The probability that A wins is 1-R” it must mean this.
In this simple idealized setting, the factors bringing uncertainty into our prediction are not the minds of the voters (they are rigid and truthful); not their propensity to vote on Tuesday (all of them shall); not the propensity of the vote-tabulation to be less than accurate (it is perfect). The only factors in this model in which uncertainty is grounded and which therefore propagate uncertainty into our prediction is the uncertain representativeness of our sample – here due entirely to the choice of a single sample of size n out of (N,n) samples of size n drawn from the population of size N.
The prediction here is thus a point-estimate; and the probability is a “margin of error” due entirely due to sampling variability. We can imagine the whole thing being repeated in the sense of a large group of similar samples of size n taken on the same Monday with the same method; which differ only insofar as different individual voters were queried.
Now see how complications of this sort multiply as soon as we introduce more realism into the description – i.e. degrees of freedom in the model: [1] subjects may not answer truthfully; [2] subjects may change their minds; [3] not all subjects who were queried will actually vote; [4] not all votes are counted; [5] not all votes that are counted are counted accurately; [5] That time passes between the event of the survey and the election; [6] That time-series of such surveys indicate a trend in the responses; etc. But the qualitative nature of the prediction will be the same: I come up with a point estimate a of the number who will vote for “A” and I quantify my certainty in that prediction with a non-reversal probability i.e. my confidence that given (a greater than b) I will find (A greater than B) after the election.