Joel Elvery write:
Long-time listener, first-time caller. I’m an economist at the Federal Reserve Bank of Cleveland.
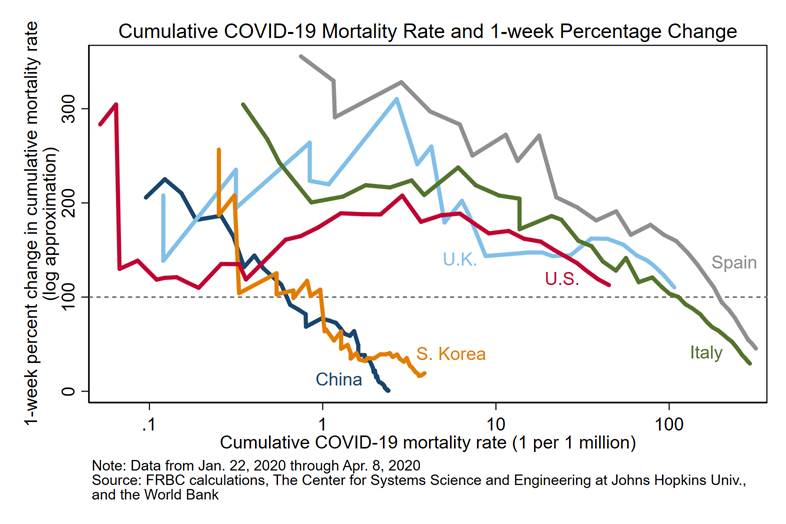
I think I have stumbled on to a very effective way to visualize and compare the trajectories of COVID-19 epidemics. This short post describes the approach and what we learn from it, but the graph above is enough to give you the gist.
I’m trying to get the word out to other people who are graphing COVID-19 data in case they also find this approach useful.
My only contribution he was to suggest he label the lines directly. Below is the first version he sent:

P.S. Lots of confusion (including from me!) in comments. Perhaps the right take-home message here is not that Elvery’s graph is good or bad, but rather that no single graph will tell the story. We need multiple visualizations to understand the data.
This doesn’t really make sense. The x-axis is population scaled, while the y-axis is not.
Zhou:
The y-axis is relative change, so it doesn’t need to be scaled. But now I’m confused: does “100” on the y-axis correspond to 100% change (i.e., doubling) or does it correspond to constant? If “100” corresponds to doubling, then I’d recommend relabeling the y-axis as 1, 2, 3, etc, rather than 0, 100, 200, etc. Also I’d put the dotted line at 1 (i.e., the current “0”) rather than 2 (the current “100”), because that seems like the right baseline. And I’d also let the y-axis go all the way to 0 (which would be -100 on the current scale), as that’s the hard lower bound.
You might be right… I just think the graph is rather confusing overall and doesn’t really serve to illuminate much.
100 means of the cumulative number of deaths has doubled from one week ago and 0 means it has remained constant (there were no additional deaths). You are right that in principle there is no need to go below zero.
The graph is a little hard to figure out at first.
The y axis is percentage change in fraction of all cases that have died. if there are no new deaths then there will be no change in the cumulative cases that have died… so y goes to zero.
Instead of mortality rate it should say case fatality rate I believe.
No, it’s scaling by overall national population, which I kinda don’t like, because this sort of thing is affected by geographic containment, and this kind of graph doesn’t well describe that. (I.e. if you consider policies restricting the infection to within Hubei, or to within New York state, or within Italy as a part of Europe.)
Generally speaking I don’t think it’s wise to scale by pop if a thing isn’t somewhat uniformly spread population wise within whatever you choose as your geographic unit.
Ah right, good point. But it’s not mortality rate in terms of per unit time, like “the mortality rate from smoking is 3/million/yr” it’s “the fraction of the population that died is 3/million”
Scaling by population can show how well containment worked. So for example china and south korea show that they haven’t spread the infection widely among the population (yet… china may still have a second country-wide eruption)
I guess it depends on what you want to see, but in my opinion this graph doesn’t show things better than just graphing cumulative deaths vs cumulative cases and you can do that as either counts or fraction of population. Both graphs show useful information (one shows absolute impact, one shows fractional impact).
Where deaths vs cases goes flat, this graph would have its y axis go to zero.
Another mathy way to put it is that this graph shows some variation on d(log(deaths/population))/dt vs log(deaths/population)
Maybe it’s just a bad idea to imagine you can find a single “perfect graph” to show what’s going on in something as complex as the covid-19 pandemic.
I agree 100% – different graphs serve different purposes. This one enables me to address the questions I want to address.
I agree about the issue about looking at “too large” geographical units which can dilute the impact of the epidemic when it’s not homogeneous. New York state would be ahead of Italy or Spain in that chart. But Lombardy would be still higher, etc.
Yeah I agree with this. I’d like an urban/suburban/rural split on these numbers given that population density/how people interact is important.
Hi. This is a mortality rate, not a fatality rate.
Mortality rate is deaths divided by population. In this cases it is reported as deaths per million residents.
I think this graph faces the same problem as a p-value: Mostly everyone assumes it does something different which it doesn’t really do!
Normally “mortality rate” is a per unit time concept:
https://en.wikipedia.org/wiki/Mortality_rate
What dimensions (units) does your x axis have?
What dimensions (units) does your y axis have?
I think the concept of “cumulative COVID-19 mortality rate per million people” as “total deaths divided by population” is pretty clear. But you can make it “per year” if you wish. On March 31 you count the reported COVID-19 deaths since March 31, 2019. Today you count the deaths since April 10, 2019. This should address your concern until one year after the first deaths was reported.
I don’t think your alternative scale would be better but in any case I think you may be misundersanding the chart. The “hard lower bound” is not at -100% (or 0 in your alternative scale). Going below 0% (1 in your alternative scale) requires people to come back from the dead. Which is somewhat appropriate for the season but unlikely to happen.
(By the way, your comment was edited since I wrote my previous reply which doesn’t make much sense now.)
> does “100” on the y-axis correspond to 100% change (i.e., doubling) or does it correspond to constant?
Actually it corresponds to a 172% increase as I explain in another comment. I was also misinterpreting the chart myself…
I think all of these misinterpretations show it’s not a great chart. :P
This
I take my share of responsability. I shouldn’t have ignored that “(log approximation)” red flag in the axis label.
This is an extremely helpful suggestion. I will use the ratio labeling and put the reference line at 2 (doubling). Thanks!
Thanks again to all for corrections and suggestions. A corrected version of the brief report is now at https://clevelandfedcm.ws.frb.org/newsroom-and-events/publications/cfed-district-data-briefs/cfddb-20200408-getting-to-accuracy.aspx .
Since this piece is targeted at a non-technical audience, I decided to stay with a percentage change measure. I abandoned the log scale on the vertical axis. The y-axes now show the 7-day moving average of 1-day percentage change. Since compounding is unintuitive to some people, I added reference lines to show 1-day percentage changes associated with doubling in 2, 3, and 7 days. I also added tick marks to convey the time dimension.
My sincere thanks,
Joel Elvery
I agree that your way of labelling is better. I find it quite annoying when there’s a graph with a huge table of colors, some of which get repeated (or at least the shades are close enough I can’t tell the difference).
On another note, your way of labelling is relatively robust to someone making a black-and-white copy, since you can just try to rely on the positioning of the label.
First off thanks for sharing the plot! Plots are fun to think about. I have some questions.
I don’t understand what a cumulative rate is. Google suggested “cumulative rate of return” when I typed it in. Maybe this is a finance term?
But a rate is like a derivative, and a cumulative is like an integral, so I’m not sure what a cumulative is.
Also the y-axis, does 150 mean that if my cumulative rate in week 1 in X then my cumulative rate in week 2 is 1.5 * X? What does log approximation mean?
—
“As a result, it can be misleading to compare data by calendar days.”
Given this plot is quite a bit different than other plots (of like cumulative whatevers vs. day), it would probably be good to point out exactly what is misleading about these simpler plots. I guess specifically, what conclusions are we incorrectly drawing from these graphs?
—
The Fortune citation on unreported deaths in China is really sketchy:
“China intentionally under-reported total coronavirus cases and deaths, U.S. intelligence says” — “The officials asked not to be identified because the report is secret, and they declined to detail its contents. But the thrust, they said, is that China’s public reporting on cases and deaths is intentionally incomplete. Two of the officials said the report concludes that China’s numbers are fake.”
At least they’re honest where they got their info, but that seems pretty low value.
Yeah I think those vague insinuations don’t really mean much. There’s a wide range of situations covered by “intentionally incomplete”! Are we saying the numbers are out by some proportion because it would cost too much to have mass population testing to capture asymptomatics and chase down deaths outside of hospitals? Are we saying testing capacity is choked so a lot of probable-infected didn’t feature in the figures? Or are we saying some official is just making up the numbers?
Take all the deaths reported so far (say 4778 for New York City) and divide by the population (around 8.55mn). That gives a cumulative COVID-19 mortality rate of 550 per million. The acumulated number of deaths one week ago was 1562 in NYC, so there has been a 206% increase. That would put the current point for NYC at x=500 y=206 (a bit outside of the chart to the right and a bit above the center on the vertical).
Actually should be x=550, y=100*log(4778/1562)=112
A footnote on that blog post says “The log approximation of the percentage change is used here to keep scale of graphs readable. Specifically, percentage change = 100*(ln(cumulative mortality rate today) – ln(cumulative mortality rate 7 days ago))”
This means that 100 is not doubling, it means multiplying by 2.78 (e). 200 doesn’t mean tripling, it means multiplying by 7.40. At least 0 still means a constant value.
It this sense, the scale is much less readable. In another sense it’s more readable: otherwise the axis would extend up to 3000 to show the same datapoints.
I think concrete examples like this help. But, now my question is: why is that point useful? What does it compare with, and how does displaying such points improve our understanding of….?
Hi. Thanks for posting this!
I chose this graph because it allows you to answer three important questions about an epidemic:
1. How deadly has the epidemic been?
2. How quickly has it grown, both in the past week and over its course?
3. How does the epidemics trajectory compare to those of other countries?
I also think that it helps people grasp the scale of the growth (especially if I change y-axis labels to multiples): Over 100% means it is more than doubling every 7 days.
Yes, the y-axis is percentage change (log approximation keeps the scale readable). I like the idea of changing labels to be multiples instead and to include the true zero. I’ll do that in future versions. Thanks!
> Over 100% means it is more than doubling every 7 days.
Over 69% means more than doubling every 7 days. Over 110% means more than tripling every 7 days. I think the way the scale has been calculated and presented is an obstacle more than a help. I would either stick to a percentage change that does what is expected (100% means doubling) or a simply a factor (new/old, as suggested by Andrew) plotted in a logarithmic scale clearly labeled as such.
Thanks for the correction. I will fix this in any future versions. -Joel
I don’t think it tells you any of those things. All these charts that dont include the testing rate are misleading.
It tells you about the course of the disease among people who are sufficiently sick to seek and get testing. So it’s not exactly worthless, but you’re right that the testing we’re doing doesn’t tell us much about the broad population and/or asymptomatic or light-symptom cases.
I mean if a country stops testing or tightens the criteria for a test then you get less mortality. In the US they are (now, I don’t know how long this has been the policy) calling every death where someone tested positive a covid mortality. I’ve also seen that presumed covid patients are counted in some places, which is based on the doctors perception.
Is that the same in China, etc?
Also, covid patients get their bill guaranteed paid by the federal government, so hospitals have financial incentive to get as many of their patients as possible labeled positive.
Sorry if this double posts:
Btw, Dr. Birx shared these numbers yesterday during the daily press conference on the age distribution of testing in the US:
75% of results have been reported to CDC (1.5 million tests)
– In order to get tested you have to have symptoms
Age < 25
– 200k tests (11% positive)
25-45
– Over 500k tests (17% positive)
45-65
– Nearly 500k tests (21% positive)
65-85
– Nearly 200k tests (22% positive)
> 85
– 30k+ tests (24% positive)
By gender:
– 56% of tests were female (16% positive)
– 44% of tests were male (23% positive)
For this particular chart, testing is not an issue. The cumulative mortality rate is total number of reported COVID-19 deaths in the country divided by total number of residents in the country.
The issue of different testing rates is one of the primary reasons that I choose to study mortality rates rather than anything based on confirmed cases. I this is discussed in the short report. https://www.clevelandfed.org/newsroom-and-events/publications/cfed-district-data-briefs/cfddb-20200408-getting-to-accuracy.aspx
Yes, but a COVID death is a death + a positive test
Agreed Daniel – Pat Bayer recently made a relevant point about how this might matter going forward:
https://twitter.com/PatBayerNC/status/1244636541718331392
That being said, at least for some countries like Italy I think one could replicate the figure with overall excess mortality rather than just officially-classified COVID mortality. It does not appear to me that we have the means to infer that variable for the US or states at the moment, but there might be a way.
Yes, I think a counterfactual estimate of mortality during the pandemic could be constructed from historical records in most places, with sufficient information. Then we could estimate the causal effect of COVID on overall mortality… This would be particularly relevant if we could exclude say accidents, crime, etc which are mostly down due to lockdowns. CDC Wonder data will probably be useful once it’s available.
There is all cause mortality, pneumonia mortality, hospital visits, etc available but with a week or two delay. Here is what I’ve been looking at to try to guess when this ends:
https://docdro.id/XMurqhl
PS: I’ve never used that docdroid site before but it seems like its hosting the pdf fine.
Data sources:
https://www.cdc.gov/coronavirus/2019-ncov/us-cases-epi-chart.json
https://www.cdc.gov/coronavirus/2019-ncov/cases-updates/testing-in-us.html
https://en.wikipedia.org/w/index.php?title=Template:2019%E2%80%9320_coronavirus_pandemic_data/United_States_medical_cases_chart
https://covidtracking.com/
https://www.cdc.gov/flu/weekly/weeklyarchives2019-2020/data/senAllregt14.html
https://www.euromomo.eu
https://gis.cdc.gov/grasp/fluview/mortality.html
In Spain, at least in Madrid and Castilla, excess mortality is far above official coronavirus mortality (according to newspaper reports, more than double in March). The reason is that a death is reported as due to coronavirus only if there was a positive test. At the peak of oversaturation of the hospitals many old people in residence homes were not even attended medically (someone decided to prioritize resources in this way although, of course, no one will admit it now and it will never appear in this way in official reports) and in these regions several thousand died without being tested.
You can see Spain here: http://euromomo.eu/outputs/images/Multicountry-zscore-Total.png
None of this data is perfect but I don’t see how it can be worse than getting your info from the news.
“The reason is that a death is reported as due to coronavirus only if there was a positive test. At the peak of oversaturation of the hospitals many old people in residence homes were not even attended medically”
‘zakly what I been sayin’
One trouble with the graph is that it is almost impossible *not* to interpret the x axis as time, even though it is clearly labeled. Also, the fractional death rates have been declining in many countries over time, so there is a rough (if non-linear) correspondence between the times and the rates. This tends to strengthen the unintended linkage between the x axis and time.
I think that the graph does not really illustrate Joel Elvery’s point # 2: “How quickly has it grown, both in the past week and over its course?”. It illustrates something else, instead:
How much (as a fraction) of a county’s total population died by the time its (fractional) death rate got down to a certain number, like 100%/week?
Now that is certainly of great interest, but it’s also a pretty abstract concept to grasp. It does not directly show how quickly anything has grown.
I think that Joel’s curve is pretty useful for thinking about how rapidly each country was able to get the outbreaks under control.
I have three conceptual problems.
1. The x-axis is an integral (cumulative mortality rate) while the y-axis is the derivative of the x-axis (as best I can tell). I don’t see this often (if ever) so I don’t have any feel for interpreting what I am seeing.
2. Graphs usually have the independent variable on the x-axis and the dependent variable on the y-axis. In what sense is cumulative mortality rate an independent variable, and in what sense is change in cumulative mortality rate a function of cumulative mortality rate?
3. I really, really, want to see the x-axis as time or some simple function of time. Indeed, the lines grow from left-to-right over time which encourages seeing the x-axis as time. But the x-axis is not time, which is confusing. Or you can see it as a very odd function of time which is even more confusing.
Maybe there is a another presentation that would not cue me so strongly to the traditional x/y axis interpretations.
If the x-axis is an integral, and the y-axis is a derivative of the x-axis, is this a plot of the derivative of an integral which is just the function itself? Are we just looking at a plot of the death rate over time with, perhaps, some odd transformation of time?
Your are right that x is an integral x(t)=sum(d(i)) for i in 1,..,t where d(t) is the number of deaths per day (normalized by the total population).
But y is not the derivative of x, it’s the derivative of log(x), more precisely y(t)=100*(log(x(t))-log(x(t-7))).
In any case you’re right that given the line we can work out the time evolution. From the last point x(t),y(t) we can calculate x(t-7) and then look up the corresponding y(t-7). From there we get x(t-14), etc. We can also calculate all the intermediate points, even though it’s less straight forward.
Terry: sort of. As Carlos Ungil notes, it’s a derivative of log(x), i.e. the derivative of x divided by x. Like you, I think this is essentially a plot of a function versus its integral, with at least one normalization thrown in. If I had more time, I’d plot what this looks like for functions we have an intuition for, for example an overall number of deaths that is sigmoidal in time. I think doing this would give a sense (at least for me) of whether this way of plotting is useful or not, and how the shape depends on the parameters of the function.
What it’s saying is pretty simple:
the mortality rate change accelerates for a while then falls, and of course the cumulative rate continues to increase.
I can’t imagine how the path would be any different in shape than the humped distribution shown under any circumstances. Even if left unchecked, eventually the morality rate change would peak and decline as the proportion of the population that hasn’t been infected shrinks. I guess it tells you something about the relative proportions of populations affected in different countries. That suggests the effects of preventative measures; but could also be the effects of population dispersion, poor reporting or some other effect.
It answers Joel’s (1) and (3) but I don’t see that it answers (2) because there’s no expression of time except possibly in the number of data points(?). Also (3) is not that clear because it’s not clear what the starting point is.
IMO the graph would be dramatically improved by clarifying what the individual data points mean with respect to time. Is each a week later than the one before? If so, why not label them as such, or use a symbol for each month (that’s only four symbols and since they’ll presumably go in order, not too much for readers).
I also think that to give it more concrete meaning it needs something that people understand to compare against – one line that is a standardized model or something. How do these data relate to common epidemic model parameters? Seems like there should be some relationship such that models of different parameters can be expressed as lines that give a comparison.
Yeah I think providing symbols for data points that indicate time would eliminate the confusion of the x-axis with time and thus be a major improvement. I would reduce the thickness of the lines and add symbols for each month. This works even if they’re not all starting at the same time, the symbols can provide the color so the lines can be pretty thin. I prefer the legend over line labels. I’m interested in the patterns first, which countries are which second.
Thanks! Marking time, but not for every point, is an excellent idea. I bet that something like marking each Monday will do the trick.
I started with scatter plots using “|” as a marker, which let me see time, but went with line charts because the work is targeted at a non-technical audience.
Yes I think it will help a lot. Actually at first I was baffled by the graph but now that I get it I like it.
Your comment implicitly answers a question I forgot to ask: what is the frequency of the data? I guess it’s daily? I realize that time is compressed on, say, Korea vs. Italy, but the variation in frequency of data points on the shorter and longer lines catches the eye and people will have to guess about why that is, so you might want to indicate the frequency in your note on start and end dates.
jim says:
“eventually the morality rate change would peak ”
yes, definitely, peak morality is here! :)
Thanks — I needed a laugh.
This shows the same data (more or less, different source) presented in a more traditional way as a function of time: https://imgur.com/a/Cx1qWn5
I’m not sure that the proposed chart is better, more informative or easier to understand than a simple time series chart of cumulative deaths per capita.
The main issue with the time series chart is that we have to mentally shift series to compare them. Many people address this problem by setting the clock at zero when some threshold is passed (like 100 deaths or whatever) for each series separately. See the FT charts for example: http://www.ft.com/coronavirus-latest
I just found this nice shiny app: https://jgassen.shinyapps.io/tidycovid19/
I spent a few more minutes thinking about this, and I now realize why this is *not* a way to “visualize and compare the trajectories of COVID-19 epidemics.” If anything, it’s a way to see what the functional form of COVID-19 growth is and graphically read off the parameters of a given form. Nonetheless, it’s always neat to see new ways to plot, especially ones that don’t have time on the x-axis, so thanks, Joel! To explain:
Let’s call cumulative deaths as a function of time M(t) (i.e. M(t) is all the deaths to time t).
The y-axis is essentially y = d (log M) / dt, as has been noted in other comments; in other words, y = (1/M) dM/dt.
The x-axis is M(t) normalized by population P: x = M/P.
For all sorts of growth processes, dM/dt ~ rM for small M (i.e. exponential growth with rate r). Therefore as M -> 0, the y-axis approaches r. The y-intercept of the above graph is simply the growth rate.
As time goes on, dM/dt -> 0, so the x-intercept is the total number of deaths normalized to P.
Everything in between these is just the *functional form* of the growth curve; it says nothing about the trajectory. This is easiest to see for logistic growth, for which one can write dM/dt and M(t) analytically. (y vs x on a semilog plot as above is simply a straight line.)
In other words, this is a nice way to (in principle) read the growth rate and the total number of deaths per capita from a Covid-19 “trajectory.” Whether the data are robust or smooth enough to actually read these off the graphs is debatable!
If the y axis is the fraction of the cumulative deaths that happened in the last week. (Deaths last week / total cumulative deaths) then logistic growth would be a straight line on this plot, with the x intercept a prediction of the final.
I first saw these style of plots here: https://dothemath.ucsd.edu/2011/11/peak-oil-perspective/
This is an interesting idea and an intuitive measure. Thank you for the suggestion.
I tried it and it doesn’t show much variation until growth starts to slow down. It would work very well as a graph that highlights the period after mortality rates stop doubling each week.
I guess for the logistic, we can’t log transform the axes. I did it for some of the larger countries here: https://imgur.com/a/n1Nq6hy and is showing some nice linear trends.
So, thinking about it a bit more, I really like this plot, If we assume logistic growth ~ $ \Delta z = \alpha z (1 – z/K)$ then $(\Delta z)/z = \alpha / K (K – z) $ and a plot of $(\Delta z)/z$ versus $z$ on linear axes should look like a line with an easy to read off procedure for both logistic parameters. $K$ is simply the x-intercept and $\alpha$ is simply the y-intercept. I whipped up an observable notebook that lets you view this dynamically for each country / region / state and county from the Johns Hopkins data here: https://observablehq.com/@alemi/logistic-growth-plots
Ha! Great link. Love it.
That page from 2011 predicted about 8 billion barrels per year in 2015 and 5 billion barrels per year in 2020. Here’s data for 2013-2019 showing 10-20 billion barrels per year
https://www.rigzone.com/news/global_oil_gas_discoveries_hit_fouryear_high_in_2019-06-feb-2020-161004-article/
It seems like less oil was being discovered 1990-2010 than 2010-2020. Maybe that data isn’t comparable for some reason I guess.
I like this: https://imgur.com/edQKovm
The one thing that most of us want to know is when will it all stop? If we can’t get that, many of us would like to know what is happening with the growth rate. It used to be about 30%/day in the US a few weeks back. Is it getting better? Is it getting close to zero?
The fractional growth rate is easy to obtain: the (discrete) time derivative of ln(n)/n, where n = cumulative number of cases. You can smooth as you like.
According to the latest data from John Hopkins, the fractional rate of increase of US fatalities is about 12%/day. Not good, but a lot better than the 30%/day it was for a while. The fatalities appear to lag the total cases by about a week, and the fractional rate of increase for the total number of US cases is down to about 7.5%/day. Many other countries have much the same pattern.
There are already plenty of cooks working on the broth, so I’m not going to weigh in on the plot itself. There are several interesting suggestions. Joel, thanks for bringing this to us. I think all of us find it hard to interpret at first, which may be OK: this is not an infographic for a mass-readership newspaper and it’s fine if it takes some work to learn to read it, as long as the payoff is worth it. For myself I guess I’m not convinced that this is better than some alternatives, but that may just be because I haven’t put enough time into getting used to it.
I’d like to thank Carlos and Raghuveer and everyone else who has devoted effort to understanding it and in some cases correcting it, and everyone who has suggested alternatives. So many other places that have a lot of commenters are full of non-constructive criticism, and maybe this blog gets some of that too but Andrew just doesn’t let them post, I dunno. But these comments are genuinely constructive and I think many of us appreciate that. Thanks, everyone.
Agree 100%.
Am I right to assume that an exponential growth would show as a constant fct here? (no matter what the cumulative mortality is, the relative gain over the last week is the same).
If so then the decreasing functions show that as cases accumulate, the logarithmic return, or “interest rate” (whatever the exponential parameter is called), is getting lower. That kind of makes sense. People run out of contacts to infect or become more careful, the most fragile individuals have already died, etc. It does not mean that the epidemic is under control.
As for the horizontal shifts between countries, that might be affected by heterogeneity in epidemic foci. Eg if the Chinese fatality totals were divided by the population of Hubei instead of then whole country, the rates would go up by a factor of 20, a good shift to the right.
Andrew, I’d be interested to hear/read your impressions of the various statistical models for forecasting the course of the covid-19 epidemic; i.e., those that aim to leverage the observations from countries further ahead in the epidemic to predict the future of those at an earlier stage?
I would like to see the time order of the datapoints. I think the line that guides the eye ‘suggests’ some sort of time evolution that I expect is not there, or is not obvious, or is not the same for each country.