First the statistical point, then the background.
Statistical point
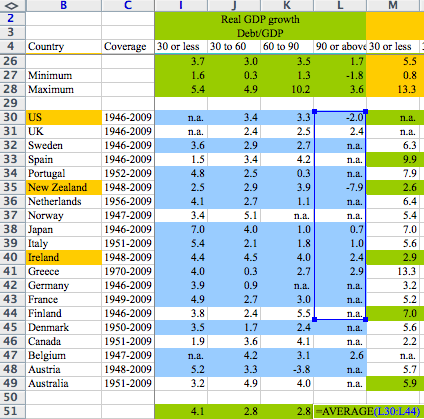
Consider the following two sentences from the abstract of the paper, Growth in a Time of Debt, published in early 2010 by Carmen Reinhart and Kenneth Rogoff:
[T]he relationship between government debt and real GDP growth is weak for debt/GDP ratios below a threshold of 90 percent of GDP. Above 90 percent, median growth rates fall by one percent, and average growth falls considerably more.
This passage corresponds to a ladder of four statements, which I’ll write in increasing order of generality:
(a) Their data show a pattern with a low correlation for debt/GDP ratios below 90%, and a strong negative correlation for debt/GDP ratios above 90%.
(b) The just-described pattern is not just a feature of past data; it also could be expected to continue into the future.
(c) The correlation between government debt and real GDP growth is low when debt/GDP ratios are low, and strongly negative when debt/GDP ratios are high.
(d) Too much debt is bad for a national economy, and the United States as of 2009 had too much debt.
– Step (a) is a simple data summary.
– You can get from (a) to (b) with simple statistical modeling, as long as you’re willing to assume stationarity and independence in some way. To put it most simply: you assume the future and the past are samples from a common distribution, or you fit some time-series model with is essentially making stationarity and independence assumptions on the residuals.
– Step (c) is a weaker, thus more general version of (b).
– And you can get from (c) to (d) by assuming the average patterns of correlation apply to the particular case of the United States in 2009.
– Completely independently, you can believe (d) in the absence of this specific evidence, just based on some macroeconomic theory.
So what happened?
It turns out that Reinhart and Rogoff made an error in their data processing, so step (a) was just wrong. Upon learning this, you might think, Game Over, but they stuck with (d), (c), and much of (b).
That’s fine—they can feel free to argue for (d) based on theoretical grounds alone, or based on some direct modeling of the U.S. economy, without reference to those historical data. They’d lose something, though, because in their published article they wrote:
Our approach here is decidedly empirical, taking advantage of a broad new historical dataset on public debt . . . Prior to this dataset, it was exceedingly difficult to get more than two or three decades of public debt data even for many rich countries, and virtually impossible for most emerging markets. Our results incorporate data on 44 countries spanning about 200 years. . . .
So if the data got screwed up, you’re kicking away the strongest leg of the stool.
And, given the importance of the published claims (essentially point (d) above) and the relevance of their unique dataset to making these claims, you’d think they authors should’ve made this broad new dataset publicly available from the start. Given the importance of this argument to the U.S. economy, one might argue they had a duty to share their data, so that other researchers could evaluate the data claim (a) and the reasonableness of the steps taking us from (a) to (b) to (c) to (d).
Background
We were discussing the Reinhart and Rogoff story in class today, and the students had two questions:
1. How could it be that the authors of this very influential paper did not share their data?
2. Why did Reinhart and Rogoff never apologize for not sharing their data?
My response to question 1 was quick; answering question 2 took longer, and brought up some interesting thoughts about scientific modeling.
First, question 1. This one’s easy to answer. Data sharing takes work, so we don’t typically do it unless it’s required, or habitual, or we’re doing it out of a public service. Views about data sharing have changed since “Growth in a Time of Debt” was published back in 2010. But even now I usually don’t get around to posting my data. I do send data to people when asked, but that’s not as good as posting so anyone can download whenever they want. There also can be legal, ethical, business, or security reasons for not sharing data, but none of these concerns arose for the Reinhart and Rogoff paper. So, the quick answer to question 1: They didn’t share their data, because people just didn’t generally share data back then. The data were public, so if anyone else wanted to reproduce the dataset, they could put in the work themselves. Attitudes have changed, but back in 2010, that’s how it usually was: If you wanted to replicate someone’s study, the burden was on you to do it all, to figure out every step.
Now on to question 2. Given that Reinhart and Rogoff didn’t share their data, and they did make a mistake which would surely have been found out years earlier had the data been shared all along, and given that the published work reportedly had a big impact on policy, why didn’t they feel bad about not sharing the data all along? Even if not-sharing-data is an “everybody does it” sort of thing, you’d still think the authors would, in retrospect, regret not just making all their files available to the world right away. But we didn’t see this reaction from Reinhart and Rogoff. Why?
My answer has to do with the different steps of modeling described in the first part of this post. I have no idea what the authors of this paper were thinking when they responded to the criticism, but here are a couple of possibilities:
Suppose you start by believing that (c) and (d) are true, and then you find data that show (a), and you convince yourself that your model deriving (b) is reasonable. Then you have a complete story and you’re done.
Or, suppose you start by disbelieving (c) and (d), but the you analyze your data and conclude (a) and (b): This implies that (c) is correct, and now you’re convinced of (d). Meanwhile you can adjust your theory so that (c) and (d) make perfect sense.
Now someone goes to the trouble of replicating your analysis, and it turns out you got (a) wrong. What do you do?
At this point, one option would be to toss the whole thing out and start over: forget about (c) and (d) until you’ve fixed (a) and (b).
But another option is to stick with your theory, continue believing (c) and (d), and just adjust (a) and (b) as needed to fit the data.
If you take that latter option, the spreadsheet error and all the questionable data-coding choices don’t really matter so much.
I think this happens a lot
I think this happens a lot in research:
(a) Discovery of a specific pattern in data;
(b) Inference of same specific pattern in the general population;
(c) Blurring this specific pattern into a stylized fact, assumed valid in the general population;
(d) Assumed applicability in new cases, beyond the conditions under which the data were gathered.
Then if there’s a failed replication, or a data problem, or a data analysis problem that invalidates (a) or (b), researchers still hang on to (c) and (d). Kind of like building a ladder to the sky and then pulling the ladder up after you so you can climb even higher.
Consider power pose, for example:
(a) Under particular experimental conditions, people in an experiment who held the “power pose” had different measurements of certain hormones and behaviors, on average, compared to people in the a control group.
(b) P-value less than 0.05 was taken as evidence that the observed data differences represented large causal effects in the general population.
(c) Assumption that power posing (not just the specific instructions in that one experiment) has general effects on power and social behavior (not just the specific things measured in that study).
(d) Statement that the average patterns represented by (c) will apply to individual people in job interviews and other social settings.
A series of failed replications cast doubt on the relevance of (a), and statistical reasoning revealed problems with the inferences in (b); furthermore, the first author of the original paper revealed data problems which further weakened (a). But, in the meantime, (c) and (d) became popular, and people didn’t want to let it go.
And, indeed, the claims economic growth and government debt, or power pose, or ESP, or various other unproven theories out there, could be correct. Statements (c) and (d) could be true, even if they were derived from mistakes in (a) and (b). This sort of thing happens all the time. But, without the strong backing of (a) and (b), our beliefs in (c) and (d) are going to depend much more on theory. And theory is tricky: often the very same theory that supports (c) and (d), can also support their opposite. These are theories that Jeremy Freese calls “more vampirical than empirical—unable to be killed by mere evidence.”
Once you’re all-in on (c) and (d), you can just park your beliefs there forever. And, if that’s where you are, then when people point out problems with (a) and (b), you’re likely to react with annoyance rather than gratitude toward the people who, from a scientific standpoint, are doing you a favor.
This is such an interesting situation!
I agree that they should have admitted their mistake. The paper should have been retracted.
But the policy implications are a completely different story. The policy implications are thus: no one should rely on these kinds of analyses to make policy. The data handling is a risk but the real problems are in the measurements themselves. a) they’re not very accurate; and b) they don’t necessarily measure what’s being claimed.
My first geology prof used to tell me: measure measure measure! But measuring is pointless if you don’t know what you’re measuring. In the physical world, that’s relatively easy to figure out. But when you’re measuring social phenomena, it’s hard to know what you’re really measuring.
Jim said,
“But the policy implications are a completely different story. The policy implications are thus: no one should rely on these kinds of analyses to make policy.”
Yes, yes, and yes!
I think that you are missing a crucial point, namely, the fact that Reinhart and Rogoff are influential economists and unlike other social sciences, top-tier economists have tremendous influence on policy makers and politicians. Rogoff testified before Congress on the issue of U.S. debt. His study was cited by tons of conservative politicians back when they cared about the size of the U.S. debt. If Reinhart and Rogoff just admitted that they were wrong and therefore there was no real empirical support for c and d, they would lose that influence. I don’t mean to say they are power mad. Rogoff definitely believes that the size of U.S. debt is a big risk. He has become an advocate. There is nothing wrong with advocates, and there should be nothing wrong with scientists becoming advocates, but it creates a conflict. “I screwed up,” “My data doesn’t actually support the conclusions I made and advanced for years.” These kind of statements would show scientific integrity, but would be devastating fodder for cross examination.
I think you are missing a key point. Reinhart and Rogoff are top-tier economists with influence among policy matters. Rogoff has testified before Congress on the issue of U.S. debt. He has become an advocate for the position that the size of this debt is a risk to the system. There is nothing wrong with being an advocate or with scientists becoming advocates, but it creates an inherent conflict. “I got it completely wrong.” or “My position in that paper turns out to have no empirical support.” These statements may show scientific integrity, but they are fodder for cross examination. I am sure Rogoff truly believes that U.S. debt is a big risk. He doesn’t want an error he made to be used to undermine that point. This is a problem anytime scientists provide expert advice or become advocates. I don’t think there is an easy answer. There may be circumstances where minimizing an error in your research may be justified in the context of a public discussion about public policy.
Steve said,
“There may be circumstances where minimizing an error in your research may be justified in the context of a public discussion about public policy.”
I’m not convinced.
“I’m not convinced.”
Me either! :)
I am not convinced either. That’s why I said “may.” But, I think it is worth putting into the mix that people in Rogoff’s position are not just dogmatists and unwilling to consider their mistakes they may also be thinking that acknowledging the mistake in the context of a public debate may be damaging to the cause.
People in important positions who’ve cornered themselves with advocating a particular position run into this problem a lot. But I don’t think they improve their position by ignoring or just downplaying a problem like this. If they don’t come clean with acceptance and a clear explanation their credibility dives and they’re just another advocate of questionable honesty and integrity.
I agree, but I don’t think it is as simple as staking out an ideologically pure test that truth should win out. I would love that to be true, but it is not. Advocates have to deal with the reality that rhetoric matters. So, there is a very real trade off between convincing people to do the right thing for the right reason and convincing people to do the right thing. I want the former, but I cannot ignore the fact that the cost/benefit calculus may be in favor of the latter from time to time.
The fact that (d) type statements are often things that people believe (or want to believe) makes them harder to knock down (I like the term vampirical!) — and also means we are less likely to look hard at the (a) and (b) level supporting evidence.
As to data sharing: if we looked at the payoff matrix for a “top academic” sharing data with a “peon academic”, stonewalling and delay would seem to be the optimal strategy for the “top academic”. The odds that what the “peon academic” is going to do with your data will enhance your reputation are low. Only forced sharing (which some academic journals in economics are now moving to) will work.
For those who need a little refresher on this topic, here’s a decent one by John Cassidy:https://www.newyorker.com/news/john-cassidy/the-reinhart-and-rogoff-controversy-a-summing-up
+1 to both paragraphs of bicyclist’s comment.
I’ve said this before here, but I might as well say it again: the Excel error actually had little impact on their results, which is why they were fine admitting to that mistake. In order to get very different results, other economists binned data differently and included different data (like New Zealand in the 70s, which people who worked in the New Zealand government of that time consider unreliable), which R&R don’t consider to be “mistakes”. But the real reason they were wrong is because their approach could never give anything other than correlations, and there was very good reason to believe that causality was not so simple as to always flow from high debt to low growth. They engaged in a whole lot of “storytime” in wider publications by acting as if they’d found a casual relationship even though that wasn’t actually justified even if you took their original paper at face value.
Im surprised that eg the inflation adjustments needed to get real GDP are accepted so easily.
OT:
I was just wondering why there is no mention of economic bubbles before the 1600s, can anyone verify whether this is really the case?
Perhaps this?
https://en.m.wikipedia.org/wiki/Dutch_Golden_Age
“why there is no mention of economic bubbles before the 1600s…”
it appears that there were financial crises:
https://www.jstor.org/stable/2122822?seq=1#page_scan_tab_contents
I’m willing to bet though that the apparent lack of modern-style crises results mostly from heavy state (royal) control of economies.
Its close but not quite the same thing where prices get pumped up skyhigh and then crash.
I think the Tulip bubble was the first real bubble.
Seems like the key feature of true modern bubbles (and subsequent crashes) is credit, which became readily available for the first time in Dutch markets during the tulip bubble. According to Niaal Ferguson’s book, the Dutch came up with many of our modern market tools, like buying on margin (credit) and short selling. Both require a well developed credit system.
Don’t forget the myrrh bubble of 424 B.C.!
Supposedly this crises of 33 AD was caused by a credit crunch as well:
https://www.armstrongeconomics.com/research/panics/ancient-panics/financial-panic-of-33ad/
“two-thirds of every loan should be invested in Italian land to reduce the speculation in the provinces.”
So it was a bubble then! Speculation on land in the provinces was rampant. The effort to curb it – deflate the bubble – caused the credit crunch.
cool, thanks for posting that!
BTW, I was aware that credit existed before the tulip bubble. My understanding was that the tulip bubble was the first time people could use margin to buy stocks. But you know if I recall correctly Niall Ferguson’s book The Ascent of Money attributes the origin of credit to the renaissance.
There’s been revisionism on tulip mania:
https://marginalrevolution.com/marginalrevolution/2018/02/tulip-mania-wasnt.html
John Law was involved in the Mississippi land bubble. There was also a South Sea bubble.
+ 1 Indeed, adjustments to get real GDP across long time spans or between nations are a joke. You can see this how different researcher calculate GDPs. For instance, the CIA calculates India’s GDP to be $9.47 trillion in U.S. dollars, whereas the World Bank calculates India’s GDP at $2.7 trillion (U.S. dollars). That is an enormous difference that depends entirely on the choices made by different researchers about how to compare various goods and services in the two very different countries and cultures. People use to understand this problem. Our CPI is really the U-CPI, the urban consumer price index because the economists who created it understood that comparing rural prices to urban prices was hopeless, but now we get comparisons among industrialized and non-industrialized countries between time periods where the availability of many good and services differed substantially and there is not the whiff of any skepticism that these comparisons may be meaningless.
A somewhat amusing example of some of the difficulties of economic estimation across time is this BBC “More or Less” program, which tries to estimate how rich Jane Austen’s fictional Mr. Darcy was. https://www.bbc.co.uk/sounds/play/w3csvq3g
Indeed, however while it’s nearly impossible to compare say a 25 percentile person living in LA today to anyone living in Ancient Egypt, it *is* possible to compare say income received to the cost to purchase very basic living requirements, such as food and clothing and non-climate-controlled shelter.
That we have such a stupid “poverty measure” in the US is absolutely SCANDALOUS. And, yes I do know that there’s an “supplementary poverty measure” research program, but I’d like to point out that the research group was formed in 2009 which is like at least 50 years too late
Also the supplemental poverty measure may well be so politicized that it is useless, I’m not sure.
I am not sure that we can have a poverty measure that is not “politicized.” It is a moral and not a scientific question. Who do we consider to live under conditions that arw unacceptable given the level of wealth we have collectively? The answer is “the poor.” But, the who are included among the “poor” is really a value judgment.
Sure but what’s needed here is a scale bar, a number of dollars needed to purchase a quantity of stuff that is understood to be necessary for some basic level of subsistence. Food, shelter, clothing and transportation to and from the source of income and food… it really doesn’t matter what precise level you choose, just make it consistent so we can take income and divide by the scale bar and get a dimensionless number that expresses degree of wealth relative to a well defined and not at all extravagant scale.
instead we get thresholds and false dichotomizations and broken ideas
Steve:
Yup, see here.
In adjusting for inflation, we are comparing different baskets of goods. This is simple when the two baskets contain the exact same goods. But, when one basket contains a smart phone and another basket contains a land line phone, a camera, a record player, and a type writer, how should the comparison work? Should we say that the price of the smart phone costs the same as the land line, the camera, the type writer, the record player, and the video game console? Or should we compare only the price of phones?
Under one choice, prices have dropped dramatically. Under another, prices have gone up. Any one who thinks carefully about this question can see that there is no objective answer to the question. We should accept that both possibilities are reasonable.
And yet a slice of pork meat and two eggs, or a chicken breast with rice are still the same commodity as they were 2000 years ago. So too is 500 square feet of room with a roof and 4 basic walls. So too is a plain cotton shirt and cotton pants… which is why the basic poverty measure is so important because basic human needs haven’t changed in 10000 years (though technology for providing them has of course, teepees and igloos and log cabins and soforth are all plausibly shelters, but the commodity is really the space to sleep or eat or cook)
I would have to disagree. I buy the 3x more expensive “organic” chicken breast and it is like a different species than the cheap stuff which I have to assume is some sort of mutant chicken injected with salt water and other preservatives. Also, growing food in one place and shipping it elsewhere (cities) is depleting the soil of minerals (especially magnesium) that are lost to wherever the sewage ends up (mostly not back in the farmland the food came from).
Sure but we are talking about small differences compared to say camel rides vs an Airbus or epic poetry memorized by special storytellers vs ubiquitous downloadable video, or hand twisted hemp vs nylon rope
Also, a good measure of poverty would use whatever was the locally cheapest meat, whatever was the locally cheapest grain, whatever was the locally cheapest 3 or 4 vegetables, whatever was the locally cheapest fermented beverage etc.
So it’s not about rice is cheap one place, barley is cheap somewhere else but rice is expensive and imported, yet we force the index in somewhere else to use the expensive imported rice so we match on a fixed commodity.
Eggs and ham are definitely not the same product as they were 2000 years ago. For one, every egg today has salmonella. 2000 years ago, they didn’t. Pigs and chickens today are definitely the product of 2000 years of selective breeding. On top of that, culinary culture and knowledge changes. If people’s tastes and ability to prepare and store food changes, then the commodity changes. My grand parents were share croppers. They were dirt poor, but my grandmother was a seamstress. She could make extraordinary cloths. There are pictures of my mother dressed to a tie. She looked like a movie star, but they didn’t always have shoes, and they were always in debt to their landlord. On the other hand, they had food. My point is that if you try to compare the basket of goods share croppers had in the 1940s to a working class family in America today, you are going to have to make choices like do you compare the cost of fabric my grandmother used to make clothes to the price of that fabric today or do you tried to take into account the implicit knowledge that my grandmother had and therefore estimate the value of the clothes are compare that to comparable quality clothes today. Making one set of choices will make the share cropper look poorer. Make another choice and the share cropper will look rich. There is not an objective answer to the question because in truth there were some ways in which those sharecroppers had it better and many other ways in which they were worse off. Trying to reduce the question of poverty to a single number or measure is the problem.
Steve said, “My grand parents were share croppers”.
According to my grandfather, his father once signed up for a share-cropping variant — he didn’t “rent” or live on the land he tended, but was promised a share of the crop in return for his labor. It turned out that, even though he tended a variety of crops, his “share” was given entirely in turnips. Not much sale value, so the family ate little but turnips for a year. (And thereafter, my grandfather hated turnips.)
Steve brings up a bunch of absolutely valid points about what I’ll call second order variation in food items. Sure.
But there are easy ways to avoid this kind of stuff if you think it through. For example, we get some historians and some nutritionists, and we go back through the last 2000 years and for every 100 year period and across each major region of the world, we discover the details of say 50 of what we’d call “typical” meals containing about N calories where N is about 1/3 of what a typical person of the size and activity level of that period would require for a day. We then use as an index in that place and time period the price of a years worth of the 10 least expensive of these meals.
This would be a reasonable proxy price for subsistence food and would automatically take into account the variation in availability and quality and soforth.
Having done all this work, we might as well also take the median price of any of the top 50 most common meals and consider this a proxy for typical food, and we should take the average of the top 10 most expensive meals and consider this the proxy price for upper class food…
My point being that in order to continue living you have to ingest a certain number of calories each month, whatever the cheapest way to ingest those calories is… that provides a baseline cost of maintaining life that is much more biologically rather than preference based.
Similarly whatever the cheapest way is to not have to sleep in the pouring rain or get hypothermia and die overnight, that provides for a biologically motivated need rather than a largely preference based price.
Each time we take some measure of the minimum way in which you can achieve some measure of stability required to keep you alive for 4-6 decades or so: you don’t substantially risk death each night from hypothermia, you don’t substantially risk starvation each week from lack of calories, you can dress yourself sufficiently that you aren’t ostracized from society for abject nakedness while working, you don’t substantially risk losing whatever the income is that you are relying on to provide the money to buy the shelter and food… but you have basically nothing more than those things. Whatever quantity of money it takes to buy those things and only those things… the ratio of your income to that income required to get those things is a meaningful dimensionless number that doesn’t require arbitrary “adjustment” through time.
“there is no objective answer to the question. We should accept that both possibilities are reasonable.”
Yes. I’m not an economist, but I might expect that, as with many other procedures in science there are different methods that have different tradeoffs to the issues you raised for calculating indices like the poverty index, GDP, inflation rate etc. That would be normal. So the CIA’s method may emphasize what’s useful to the CIA, while the US Bureau of Whatever creates an index that’s suitable for it’s purposes.
WE get comparisons that are inappropriate (i.e., industrialized to non) because people need something to compare and better problematic than nothing. Or so scientists across the board seem often to believe. When they want to do some kind of analysis, and there’s a number or data set sitting there already that nominally would do the trick, even though it’s problematic, it’s just too tempting to ignore.
+1
Steve, dude, you are comparing two numbers that are not comparable. The CIA number is purchasing power parity adjusted. The World Bank number is not.
And then, not only do you not understand the numbers, you go on at great length on how economists don’t know what they are doing. This has got to be Peak Internet.
R&R received and deserved a lot of flack. However: the data problem was identified by a grad student who had, I believe, received the spreadsheet from R&R. So presumably they were willing to share the data. Furthermore, Reinhart was generally quite transparent. The data for the “This time is different…” book, for instance, was available on her website right after publication (I remember, because I looked at it at the time).
But Andrew’s more general points are well-taken.
Another issue, in this particular case, is that they didn’t even publish their paper in a peer-reviewed venue. For all the pitfalls of peer review, the fact is that many still consider it a reliable way for filtering out poorly done work and that some politicians were still eager to take the results of this study even without this “seal of quality” of sorts.
Another aspect of this story, alas, is that the economics profession doesn’t really care about errors committed by its leading lights. See for instance the nonexistent consequences of Martin Feldstein’s coding error in his career-making 1974 paper on Social Security and private savings. (It’s covered by Dean Baker at http://cepr.net/blogs/beat-the-press/in-history-of-economic-errors-martin-feldstein-deserves-mention) R&R had every reason to expect that the kerfuffle over their paper would pass, leaving them and their claims untouched.
The interesting question is why economics is like this. (1) Is economics different? (2) Is it because of the services economists perform for political and other elites? (3) Are some results in economics so “obviously” correct (debt is bad, social security distorts saving incentives) that glitches in the evidence don’t matter? (4) Something else?
Economics is different, there is no mechanism of validating their predictions and no possible outcome which would cause any of them to change their minds. It’s mostly charlatanism, which is why most of them are hired guns on one side in a policy debate.
R&R found a willing audience on one side, that’s why it got so much traction. The same as the likes of the Stern report, which for years was the last word on the economic impact of climate change. Pure hocus pocus, but by the time it’s discredited or ignored or whatever, there will be something along to take its place.
Perhaps another way to say this: Economics is often a purveyor of fake news.
And, perhaps ironically (or perhaps fittingly?), fake news may have economic consequences, e.g.:
https://www.npr.org/2019/09/06/758473796/stop-the-presses-newspapers-affect-us-often-in-ways-we-dont-realize
and
https://www.computer.org/csdl/magazine/it/2017/06/mit2017060008/13rRUB6SpX0
Some famous mistakes in economics papers are like the Piranha Problem papers in social psych, where little things are found to have implausibly big effects, supported only by the one paper’s analysis. Others, tho, like Reinhart and Rogoff, are plausible and the authors eyeball a pattern in the data and then their mistake in data recording or analysis supports what they were pretty sure they’d find. In econ, it’s this second type which is the more likely to be done by famous people and to get cited a lot (and also to get past referees, because they aren’t skeptical ofsomething which seems likely to be true). Moreover, the conclusions may well be true even if the paper is fatally flawed. I guess Bayesians might put this down to misuse of stat significance— the authors have a hunch because they know the data, and when they test it, their mistake makes it statistically significant wher eit wouldn’t be otherwise, and then the mistake is found, and everybody says the paper is wrong, but it’s still valid at a p-value of 15%.
I’m more familiar with this in pure theory papers, since I do more of that. The author has good intuition, so he thinks a proposition is true. He proves it with a lengthy proof with some difficult steps and many boring steps. The referees think about the proposition and decide it’s true, but iwthout going over the proof carefully. It IS true. But the proof is wrong, sometimes fatally so (that is, it would have to be proved using a different approach).
But most papers, either empirical or theoretical, die a lonely death even if published, with nobody reading htem. So it’s efficient not to be too careful at hte publications stage, and instead to encoaurge grad students and others to try to replicate afterwards, and onlyl try it with the really good papers, the ones that have influence.
Eric:
Yes. An efficiency argument for post-publication review.
Also: Reputational incentives and post-publication review: two (partial) solutions to the misinformation problem.