Steve Stigler writes:
I saw a piece on your blog about putting. It suggests to me that you do not play golf, or you would not think this was a model. Length is much more important than you indicate. I attach an old piece by a friend that is indeed the work of a golfer!
The linked article is called “How to lower your putting score without improving,” and it’s by B. Hoadley and published in 1994. Hoadley’s recommendation is “to target a distance beyond the hole given by the formula: [Two feet]*[Probability of sinking the putt].” Sounds reasonable. And his model has lots of geometry, for example:
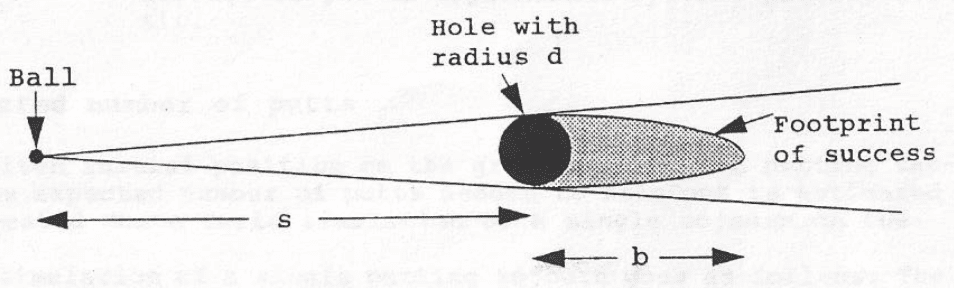
Anyway, what I responded to Steve was that the simple model fits just about perfectly up to 20 feet! But for longer putts, it definitely helps to include distance, as was noted by Mark Broadie in the material he sent me.
The other thing is that there’s a difference between prediction and improvement (or, as we would say in statistics jargon, a difference between prediction and causal inference).
I was able to fit a simple one-parameter model that accurately predicted success rates while not including any consideration of the difficulty of hitting the ball the right length (not too soft and not too hard). At least for short distances, up to 20 feet, my model worked, I assume because it the took the uncertainty in how hard the ball is hit, and interpreted it as uncertainty in the angle of the ball. For larger distances, these two errors don’t trade off some cleanly, hence the need for another parameter in the model.
But even for these short putts, my model can be improved if the goal is not just to predict success rates, but to figure out how to put better—that is, to predict success rates if you hit the ball differently.
It’s an interesting example of the difference between in-sample and out-of-sample prediction (and, from a statistical standpoint, causal inference is just a special case of out-of-sample prediction), similar to the familiar problem of regression with collinear or near-collinear predictors, where a wide range of possible parameter vectors will fit the data well (that’s what it means to have a ridge in the likelihood), but if you want to apply the model to predict for new data off that region of near-collinearity it will be necessary to bite the bullet and think harder about what those predictors really mean.
So . . . prior information can be important for an out-of-sample prediction or causal inference problem, even if it’s not needed to fit existing data.
Andrew, could you elaborate on the statement “and, from a statistical standpoint, causal inference is just a special case of out-of-sample prediction”?
Is the special case when your statistical model maps to an physical (or economic or physiological or…) model?
The special case is when your model correctly predicts the effect of interventions that actively change the values of predictors.
I’m dimwitted enough to require a bit more elaboration.
“Correctly predicting effects of changed predictors” sounds just like out-of-sample prediction. But in what way is causal inference a special case (and not an ordinary case) of (functioning) out-of-sample prediction?
Is is that having the right causal model gives you correct out-of-sample predictions on a wider range of new predictors? I’m guessing you mean something else.
Suppose you have some data on cholesterol and mortality… it’s observational data. You divide this data set in half, and fit a model to the first half. It successfully predicts in the second half.
Yet, through an accident of your data collection methodology or whatever in your data set the people with high cholesterol live longer and have fewer heart attacks.
Now, we run a randomized controlled trial on a group of different people. In this group we give half of them a cholesterol reducing drug and half of them 50mg of pure starch. We see in our data that through time those who get the cholesterol reducing drug have reduced cholesterol, and also have fewer heart attacks and live longer.
When we fit our model to this experimental data, and then recruit a new set of experimental cases, the model correctly predicts that those whose cholesterol is reduced will have fewer heart attacks and live longer.
Both cases involve correctly predicting out-of-sample. But the first observational model has nothing to do with what happens if you *change* an individual person’s cholesterol. It just tells you that in the group you observed the people who have higher cholesterol are somewhat healthier.
The second model is a causal model because it correctly predicts out-of-sample what will happen if you *change* people’s cholesterol.
Also note that both of these could be relatively simple linear regression type models, they don’t need to have any mechanistic biochemistry type stuff in them in order to be considered causal.
excellent, clear example.
I don’t understand Stigler’s point. By Stigler’s rationale, linear regression “models” aren’t models, because no real-world phenomenon is actually caused by randomly drawn points about a line. While this may be true, I can’t imagine this is what any applied statistician means by the term “model”.
My dad (who used to be a great amateur golfer) also says that disance is a huge factor in putting. I just went to the putting green with him when I was back in Detroit recently where he was stressing how important distance was. Dad wasn’t much for advice outside of sports or avoiding being arrested, but I remember growing up with the mandate never to leave a ball on what he called the “amateur side” (i.e., too short). As a result, fifty years later, I still think of anything that falls short as being on the amateur side whether it’s a free throw or a parameter estimate.
Andrew—where did your data come from? Was this pro golfers on tournament greens? My dad said that putting on professional tournament greens is like putting on the hood of a car they’re so fast. That makes the putting distance game really different than it is on local amateur courses or even tournament courses when not groomed for the pros.
There’s another uncertainty you get on harder courses, which is that it’s almost never level ground from the ball to the hole. So you have to figure out the right angle to try to hit it (which makes it seem kind of like miniature golf to me—combo shot off the balloon through the clown’s mouth…).
So a sensible model might give someone length accuracy/error, directional choosing ability/error, and then directional hitting ability/error. As Andrew says, the simple model just packs all these sources of error into a single error term. There might not be enough data in his data set to fit the more complex model.
As Andrew mentions at the end of the post, this is all part of Andrew’s methodology for fitting models (as described on page 1 of Gelman et al.’s Bayesian Data Analysis). We expand them with reasonable parameters (like length and angle selection) until the data no longer supports the expansion. The reason we don’t run into massive overfitting is that we try to choose reasonable parameters and don’t take the goal to be in-training-set prediction. If the latter is all we cared about, we’d add a random effect on the log odds scale for each putt that would exactly capture the data in the sense that the posterior predictive likelihood of the binary data in the fitted model would be as close to 1 as you want.
P.S. I only golf to keep dad company, despite having had a lot of practice as a kid, especially in chipping and putting (“drive for show, putt for dough” as dad always said ). The highlight of my golf career was spraying two dozen balls into the ocean and condos at Pebble Beach as dad drove straight down the narrow fairways.
Bob:
The first dataset is from Don Berry’s statistics textbook from 1995, I think it was. The second, larger dataset comes from Mark Broadie. All the data are from pro golfers in tournament play, I believe. Broadie’s data have a lot more information, including the golfer, the golf course, maybe the weather conditions . . . lots more could be done if you are interested in golf (which I’m not). I like this example because (a) it’s clean, and (b) we can build a model from first principles, rather than just using generic model from a statistics textbook.
And it prompts/invites input from domain experts for how to get less wrong.
(But we all need to choose how we spend our time.)
“I remember growing up with the mandate never to leave a ball on what he called the “amateur side” (i.e., too short)”
Studies have shown that 94% of putts that don’t reach the hole do not go in.
What do you mean? Are you saying that 6% of putts that don’t reach the hold actually go in?
No. The other 6% don’t go in either.
Terry and Sock Puppet make a good comedy team. ;~)
the “amateur side” does not refer to missing a putt short, it refers to missing a put on the “low-side” – e.g. on a right-to-left breaking putt, the amateur side is left.