Jim Savage writes:
I just saw your post on poll bounces; have been thinking the same myself. Why are the poll aggregators so jumpy about new polls?
Annoyed, I put together a poll aggregator that took a state-space approach to the unobserved preferences; nothing more than the 8 schools (14 polls?) example with a time-varying mean process and very small updates to the state.
One of the things I was thinking of was to use aggregated demographic polling data (from the polling companies’ cross-tabs) as a basis for estimating individual states for each demographic cell, and then performing post-stratification on those. Two benefits: a) having a time-varying state deals nicely with the decaying importance of old polls, and b) getting hold of unit-level polling data for MRP is tough if you’re me (perhaps tough if you’re you?).
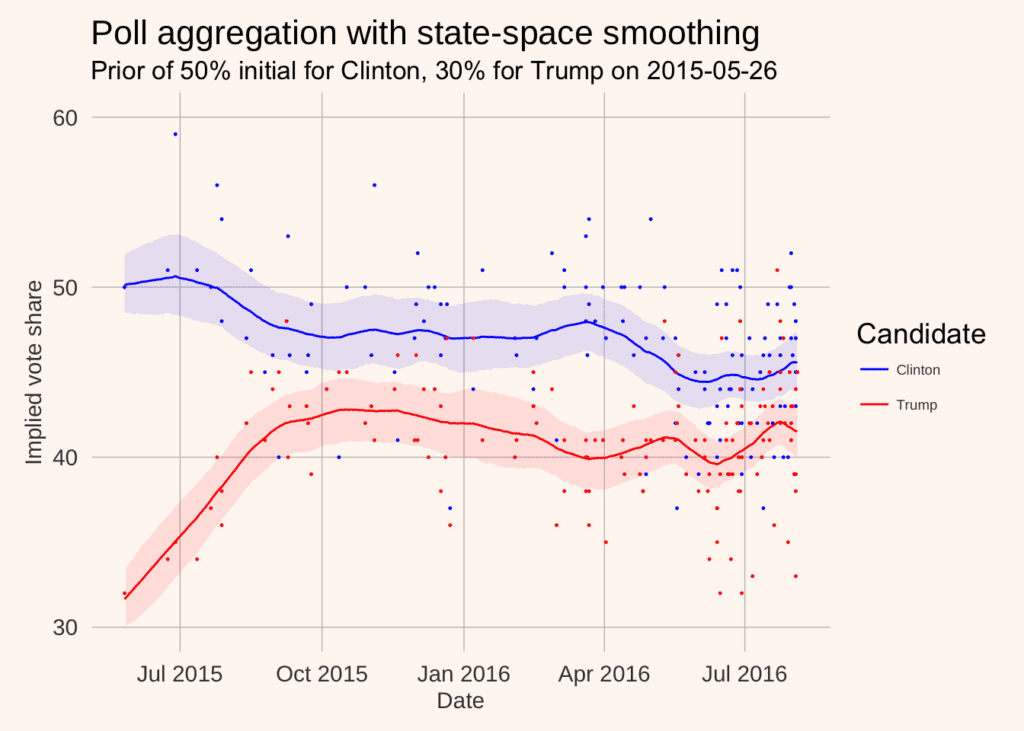
Here’s the plot:
A full writeup, automated data scraping, model etc. is below.
Here’s the zipfile with everything.
My only comment is that you should be able to do even better—much better—by also including party ID among the predictors in the model, then fitting a state-space model to the underlying party ID proportions and poststratifying on it as well. That would fix some of the differential nonresponse stuff we’ve been talking about.
And here’s Jim’s writeup:
This tutorial covers how to build a low-to-high frequency interpolation model in which we have possibly many sources of information that occur at various frequencies. The example I’ll use is drawing inference about the preference shares of Clinton and Trump in the current presidential campaign. This is a good example for this sort of imputation:
- Data (polls) are sporadically released. Sometimes we have many released simultaneously; at other times there may be many days with no releases.
- The various polls don’t necessarily agree. They might have different methodologies or sampling issues, resulting in quite different outcomes. We want to build a model that can incorporate this.
There are two ingredients to the polling model. A multi-measurement model, typified by Rubin’s 8 schools example. And a state-space model. Let’s briefly describe these.
Multi-measurement model and the 8 schools example
Let’s say we run a randomized control trial in 8 schools. Each school ii reports its own treatment effect teitei, which has a standard error σiσi. There are two questions the 8-schools model tries to answer:
- If you administer the experiment at one of these schools, say, school 1, and have your estimate of the treatment effect te1te1, what do you expect would be the treatment effect if you were to run the experiment again? In particular, would your expectations of the treatment effect in the next experiment change once you learn the treatment effects of the other schools?
- If you roll out the experiment at a new school (school 99), what do we expect the treatment effect to be?
The statistical model that Rubin proposed is that each school has its own true latent treatment effect yiyi, around which our treatment effects are distributed.
tei∼(yi,σi)teiNyiσiThese “true” but unobserved treatment effects are in turn distributed according to a common hyper-distribution with mean μμ and standard deviation ττ
yi∼(μ,τ)yiNμτOnce we have priors for μμ and ττ, we can estimate the above model with Bayesian methods.
A state-space model
State-space models are a useful way of dealing with noisy or incomplete data, like our polling data. The idea is that we can divide our model into two parts:
- The state. We don’t observe the state; it is a latent variable. But we know how it changes through time (or at least how large its potential changes are).
- The measurement. Our state is measured with imprecision. The measurement model is the distribution of the data that we observe around the state.
A simple example might be consumer confidence, an unobservable latent construct about which our survey responses should be distributed. So our state-space model would be:
The state
conft∼(conft−1,σ)conftNconft1σwhich simply says that consumer confidence is a random walk with normal innovations with a standard deviation σσ, and
survey_measuret∼(conft,τ)survey_measuretNconftτwhich says that our survey measures are normally distributed around the true latent state, with standard deviation ττ.
Again, once we provide priors for the initial value of the state conf0conf0 and ττ, we can estimate this model quite easily.
The important thing to note is that we have a model for the state even if there is no observed measurement. That is, we know how consumer confidence should progress even for the periods in which there are no consumer confidence surveys. This makes state-space models ideal for data with irregular frequencies or missing data.
Putting it together
As you can see, these two models are very similar: they involve making inference about a latent quantity from noisy measurements. The first shows us how we can aggregate many noisy measurements together within a single time period, while the second shows us how to combine irregular noisy measures over time. We can now combine these two models to aggregate multiple polls over time.
The data generating process I had in mind is a very simple model where each candidate’s preference share is an unobserved state, which polls try to measure. Unlike some volatile poll aggregators, I assume that the unobserved state can move according to a random walk with normal disturbances of standard deviation .25%. This greatly smoothes out the sorts of fluctuations we see around the conventions etc.
That is, we have the state for candidate cc in time tt evolving according to
Vote sharec,t∼(Vote sharec,t−1.0.25)Vote sharectNVote sharect10.25with measurements being made of this in the polls. Each poll pp at time tt is distributed according to
pollc,p,t∼(Vote sharec,t.τ)pollcptNVote sharectτI give an initial state prior of 50% to Clinton and a 30% prior to Trump May of last year. As we get further from that initial period, the impact of the prior is dissipated.
The code to download the data, run the model (in the attached zip file) is below.
library(rvest); library(dplyr); library(ggplot2); library(rstan); library(reshape2); library(stringr); library(lubridate) options(mc.cores = parallel::detectCores()) source("theme.R") # The polling data realclearpolitics_all <- read_html("http://www.realclearpolitics.com/epolls/2016/president/us/general_election_trump_vs_clinton-5491.html#polls") # Scrape the data polls <- realclearpolitics_all %>% html_node(xpath = '//*[@id="polling-data-full"]/table') %>% html_table() %>% filter(Poll != "RCP Average") # Function to convert string dates to actual dates get_first_date <- function(x){ last_year <- cumsum(x=="12/22 - 12/23")>0 dates <- str_split(x, " - ") dates <- lapply(1:length(dates), function(x) as.Date(paste0(dates[[x]], ifelse(last_year[x], "/2015", "/2016")), format = "%m/%d/%Y")) first_date <- lapply(dates, function(x) x[1]) %>% unlist second_date <- lapply(dates, function(x) x[2])%>% unlist data_frame(first_date = as.Date(first_date, origin = "1970-01-01"), second_date = as.Date(second_date, origin = "1970-01-01")) } # Convert dates to dates, impute MoE for missing polls with average of non-missing, # and convert MoE to standard deviation (assuming MoE is the full 95% two sided interval length) polls <- polls %>% mutate(start_date = get_first_date(Date)[[1]], end_date = get_first_date(Date)[[2]], N = as.numeric(gsub("[A-Z]*", "", Sample)), MoE = as.numeric(MoE))%>% select(end_date, `Clinton (D)`, `Trump (R)`, MoE) %>% mutate(MoE = ifelse(is.na(MoE), mean(MoE, na.rm = T), MoE), sigma = MoE/4) %>% arrange(end_date) # Stretch out to get missing values for days with no polls polls3 <- left_join(data_frame(end_date = seq(from = min(polls$end_date), to= as.Date("2016-08-04"), by = "day")), polls) %>% group_by(end_date) %>% mutate(N = 1:n()) %>% rename(Clinton = `Clinton (D)`, Trump = `Trump (R)`) # One row for each day, one column for each poll on that day, -9 for missing values Y_clinton <- polls3 %>% dcast(end_date ~ N, value.var = "Clinton") %>% dplyr::select(-end_date) %>% as.data.frame %>% as.matrix Y_clinton[is.na(Y_clinton)] <- -9 Y_trump <- polls3 %>% dcast(end_date ~ N, value.var = "Trump") %>% dplyr::select(-end_date) %>% as.data.frame %>% as.matrix Y_trump[is.na(Y_trump)] <- -9 # Do the same for margin of errors for those polls sigma <- polls3 %>% dcast(end_date ~ N, value.var = "sigma")%>% dplyr::select(-end_date)%>% as.data.frame %>% as.matrix sigma[is.na(sigma)] <- -9 # Run the two models clinton_model <- stan("state_space_polls.stan", data = list(T = nrow(Y_clinton), polls = ncol(Y_clinton), Y = Y_clinton, sigma = sigma, initial_prior = 50)) trump_model <- stan("state_space_polls.stan", data = list(T = nrow(Y_trump), polls = ncol(Y_trump), Y = Y_trump, sigma = sigma, initial_prior = 30)) # Pull the state vectors mu_clinton <- extract(clinton_model, pars = "mu", permuted = T)[[1]] %>% as.data.frame mu_trump <- extract(trump_model, pars = "mu", permuted = T)[[1]] %>% as.data.frame # Rename to get dates names(mu_clinton) <- unique(paste0(polls3$end_date)) names(mu_trump) <- unique(paste0(polls3$end_date)) # summarise uncertainty for each date mu_ts_clinton <- mu_clinton %>% melt %>% mutate(date = as.Date(variable)) %>% group_by(date) %>% summarise(median = median(value), lower = quantile(value, 0.025), upper = quantile(value, 0.975), candidate = "Clinton") mu_ts_trump <- mu_trump %>% melt %>% mutate(date = as.Date(variable)) %>% group_by(date) %>% summarise(median = median(value), lower = quantile(value, 0.025), upper = quantile(value, 0.975), candidate = "Trump") # Plot results bind_rows(mu_ts_clinton, mu_ts_trump) %>% ggplot(aes(x = date)) + geom_ribbon(aes(ymin = lower, ymax = upper, fill = candidate),alpha = 0.1) + geom_line(aes(y = median, colour = candidate)) + ylim(30, 60) + scale_colour_manual(values = c("blue", "red"), "Candidate") + scale_fill_manual(values = c("blue", "red"), guide = F) + geom_point(data = polls3, aes(x = end_date, y = `Clinton`), size = 0.2, colour = "blue") + geom_point(data = polls3, aes(x = end_date, y = Trump), size = 0.2, colour = "red") + lendable::theme_lendable() + xlab("Date") + ylab("Implied vote share") + ggtitle("Poll aggregation with state-space smoothing", subtitle= paste("Prior of 50% initial for Clinton, 30% for Trump on", min(polls3$end_date)))
Very nice work, but you didn’t give us the Stan code!
https://github.com/khakieconomics/state_space_polls/blob/master/state_space_polls.stan
Is the zip attachment available?
Luis, Adam:
I added a link in the above post to the zipfile.
Loved the graph. So much clearer than the scatter plot posted on the first “bounce” post. I could never interpret what that one was.
The first post was important and different than this one. The X axis was party affiliation percentage among respondents to the poll vs. vote share in poll. It’s about an effect that Andrew suggests to add to this model. It’s a good general lesson to take your modeling down to the lowest relevant level you can find and then build up with poststratification.
The issue I struggle with is that unless we go through the procedure you describe below in a comment (““Better” has to be defined decision theoretically”) how do we know whether adding any more effects e.g. the party-ID effect Andrew suggests will indeed make the model any better?
Maybe it will. Maybe it will make it worse. But how can we tell without some sort of predictive validation?
And I rarely see that part of the predictive validation loop in the Bayesian models I see posted. And decision-theory even more rarely.
Rahul:
See chapter 7 of BDA3 or my papers with Aki on Waic and Loo.
Naive question: In this case, what does “you should be able to do even better” mean? What to we validate against to define “better”?
Is the only validation who predicts the final election vote share better?
“Better” has to be defined decision theoretically. Traditionally, researchers evaluate point estimates against true parameter values (e.g., vote share). You can do this over time with cross validation by estimating each t + 1 given time t or estimating each t given a subset of the data at t (and all the data before t). Then there’s the issue of what you measure — getting the right winner, log loss, squared error on vote share, etc. That’s where the decision theory comes in based on what you want to predict and what costs for getting right and wrong answer are.
Thanks. So is anyone actually doing all this for voting models out there?
Yes, see Andrew’s publication list. The reason we keep harping on about these things is that we don’t think enough people are doing them as standard operating procedure. Hence all of our emphasis on model checking and validation. Just like software—try to break it.
A few tips to get it to run
– use the dev ggplot2 (this allows subtitles). You can install this with devtools::install_github(“hadley/ggplot2”)
– remove the reference to lendable:: (my employer’s library which uses the theme).
Apologies! Next step is to relax independence of the unobserved state.
Dumb question: What is the “shrunken_polls” matrix? Didn’t understand that bit.
My second question probably reflects my ignorance of Stan functioning but here goes: The parameters mu & tau get initialized in the model by the lines
mu[1] ~ normal(initial_prior, 1);
&
tau ~ student_t(4, 0, 5);
But how come shrunken_polls is allowed to be referred to before it is ever initialized?
Y[t,p]~ normal(shrunken_polls[t, p], sigma[t,p]);
Hey Rahul –
All the parameters are initialised in the parameter block; the model block simply describes the density of the data conditional on the parameters and the priors for the parameters.
You can think of the shrunken_polls matrix as being the analogy to the “true but unobserved” treatment effects in the 8 schools example (ie. the updated treatment effect estimates after the experimenter at one school has observed the treatment effects from the experiment at other schools). I’ve set up shrunken_polls to have T rows (number of days including those days with no polls) and a number of columns corresponding to the maximum number of polls on a single day (I’m treating polls on a single day as exchangeable).
shrunken_polls is very poorly programmed, in that there are loads of un-used parameters–corresponding to periods in which there were no polls. You still have to give these a distribution; I just use normal(0,1). Would be quicker to run if I had a shrunken_poll parameter for every non-null poll and then mapped these to the measurement matrix Y.
OK, maybe I still don’t get the modelling abstraction. What I meant was mu[1] is set to normal(initial_prior, 1) & tau to student_t(4, 0, 5).
But what is shrunken_polls[1,1] set to before it is used in the expression Y[1,1]~ normal(shrunken_polls[1, 1], sigma[1,1]). Assuming shrunken_polls[1,1] is not -9.
I’d have thought shrunken_polls[t, p] ~ normal(mu[t], tau) ought to come before the other line?
Maybe, I am not getting the obvious.
Ah! I get the question now.
It doesn’t matter about the order in which you declare these operations. All they do is increment the log probability counter by the log density at a point.
In Stan, order DOES matter. It’s not like JAGS for example where the whole thing is one big declarative statement.
On the other hand, in this case I don’t think order matters because the “~” operator is NOT an assignment to the thing on the left hand side, as you say, it’s a shorthand method of incrementing a variable called __lp.
so:
foo ~ bar(baz,quux);
is actually translated into the equivalent of
__lp = __lp + log_bar(foo,baz,quux);
so, it’s not an assignment to foo, it’s a function call in which foo is the first argument.
Just to clarify my understanding:
Can I put this line right at the end of the model block?
mu[1] ~ normal(initial_prior, 1);
https://github.com/khakieconomics/state_space_polls/blob/master/state_space_polls.stan
So, what’s a counterexample where order *would* matter with the model block?
Rahul:
Here’s an example where order matters:
vs.
This is kind of a weird example, but it illustrates the general point that if your model includes a sequence of statements that affect each other, the order can matter.
Thanks Andrew!
Can anyone elaborate on the distinction between the = vs. ~ operators when used in the model block? I tried looking for it in the Stan manual but couldn’t locate it.
I couldn’t find the tilde in the standard operators table (Fig. 26.1) which is quite extensive.
Rahul. the “=” operator is assignment to a variable. I guess they changed this, it used to be the R left arrow operator <- assignment to a variable changes the value that is stored in that variable. You can’t assign to a parameter.
the ~ operator describes a probabilistic fact about the object on the left hand side. It says that the probability you are assigning (or maybe “assuming” is the better terminology) to the value of the left hand side object being x is dx times the value of the distribution function on the right evaluated at x.
as an example, if y is a parameter
y ~ normal(0,1); says that your information about what the value of y is is that it has probability dnormal(yy,0,1) * dy of being within infinitesimal distance dy of yy.
(where now dnormal is R notation for the normal density function, not Stan notation)
this doesn’t modify the value of y in any direct way, what it does is it modifies the dynamics of the sampler so that the sampler ensures this probabilistic constraint is included in the calculation.
the thing on the left doesn’t need to be just a data value, or just a parameter value, it can actually be any expression containing data and parameters. It’s up to you to understand what that means, and declare “true” facts (that is, to create a good model of reality). I started some mild holy wars on the Stan mailing list about this topic. I called the distinction “declarative vs generative”. If you put only data or only parameters on the left you’ve got a “generative” model, where you imagine that the values are “generated by” sampling from the distribution on the right. If you put some other expression on the left, you’ve got a declarative model, where you’re declaring that the transformed quantity on the left has a certain probabilistic constraint on its values. In any case, the fact that you can put an expression on the left hand side makes it clear that this isn’t an assignment to a variable, it’s a declaration of a probabilistic fact.
The manual explains the language in detail: http://mc-stan.org/documentation/
Daniel Lakeland’s syntax is outdated (and direct increment of lp__ is no longer supported). The current syntax is as follows
y ~ foo(theta);
and
target += foo_lpdf(y | theta);
The only difference is that the former drops normalizing constants that only depend on data and constants (i.e., don’t depend on variables declared as parameters, transformed parameters, or local variables in the model block in the Stan program). Also, use _lpmf if foo is a probability mass function (pmf) instead of density function (pmf).
Wow, those are some pretty big syntax changes, but I think I like them. When did that happen?
@Andrew
Thanks for posting this counterexample illustrating when order matters.
Are there any “non-weird” i.e. realistic examples where order matters (within the model block)? I skimmed through the manual & couldn’t locate any yet. Just curious.
Also Bob, is it still possible to put an arbitrary expression on the left hand side of ~ or in the corresponding position such as foo_lpdf(expression | stuff, here)
?
Rahul, I think there are LOTS of non-weird places where order matters. Basically it’s the same as in other programming languages, don’t USE a variable until it’s been assigned the value you need it to have. Just remember that parameters are not variables you assign to, they’re variables that *the sampler* assigns to.
Stan code is executed in order, so order matters. It can cause bugs when users expect tree-respecting evaluation as in JAGS/BUGS. It always matters when a local variable is defined—that has to happen before it’s used, and it’s a common source of errors. Also, people write iterative algorithms in Stan, and order matters there in the usual way.
Why do you still have to give the shrunken_polls a distribution for the missing data: “shrunken_polls[t, p] ~ normal(0, 1);”, why not just leave out the else statement all-together? Is it due to some fancy internal HMC correlation between the elements of shrunken_polls when generating that matrix, if so, shouldn’t it be distributed the same way as for the non-missing case: “shrunken_polls[t, p] ~ normal(mu[t], tau);”?
I understand this will become moot for your model once you remove the unused parameters, but might be relevant for other models. Coincidentally, I ran your original model and also those two variations, and the plots were practically the same.
I cleaned it up a bit. You can play along at home with the following repo:
https://github.com/khakieconomics/state_space_polls
Would it be possible to do this at the state level and then simulate electoral votes from that or is there not enough data/another reason that isn’t a good idea?
So in the combined analysis does the size of each individual poll get any weight? Shouldn’t it? Or are the poll sizes not available? Or does the s.d. capture that info.?
Yep, that’s captured in the noise of the individual poll measures (each poll’s margin of error). FYI I have updated sigma in the repo–apparently MoE is one sided.
If I understand the code, you have two underlying quantities, the average over all the polls “shrunken_polls”, whose distribution is determined strictly by the polls on that day, and the underlying state, mu, whose distribution is determined by a random walk diffusion from the previous day, and a measurement error model where shrunken_polls is an estimate of mu, with a constant measurement error tau.
Is there any specific reason why you use a random walk diffusion, rather than a smoother gaussian process? Or did this just work well enough and was simple?
Your plot shows the smooth average, and then just a band of color. if you look at spaghetti plots of individual mu trajectories, are they smooth, or jagged like random walks? My intuition says that the overall average opinion should move smoothly (as it does in your graph) so it seems like mu trajectories should probably have a gaussian process prior where they’re smooth using say a quadratic exponential covariance function with a time-scale that’s uncertain, but has a prior that puts high probability on a range from say 5 to 200 days. Then, the posterior over the timescale would be interesting. How fast does opinion really change?
To make this work, you need a covariance matrix as a transformed_parameter, and a loop over the covariance matrix that sets the covariance between two mu values mu[i] and mu[j] to be exp(-((t[i]-t[j])/tscale)^2), then the line
mu ~ multivariate_normal(overall_avg,covariance_matrix)
The next modification might be to make the timescale itself a function of time. Obviously when there are many candidates in the primaries, opinion for a given candidate can change more rapidly. When the primaries are done, I’d bet opinions change more slowly. It’s much less clear to me how to construct a proper covariance function with a time-varying time-scale. Perhaps the covariance between two points could be determined by the time-scale at the mid-point? That at least would make the matrix symmetric, but I’m not sure if that’s going to be positive-definite.
The graph I’d love to see is the ultrasimplistic one: For each time point just average the result of the (say) 5 nearest studies weighted by their s.d. & apply a smoothing filter.
Wonder how different that line would be from this one.
A graph of shrunken_polls is more or less the average of all polls for that day, weighted by sd.
“Apply a smoothing filter to shrunken_polls” is more or less what “mu” is. The specific smoothing filter is that mu[i] is simultaneously (soft) constrained to be within 0.25 of mu[i-1] and to be within “tau” of shrunken_polls[i]
having “mu” be a weighted average of shrunken_polls for several days in either direction would be more or less the gaussian process I am suggesting above.
By “soft constrained” I mean that rather than in boolean logic saying that either a thing is true or not true (ie. it’s definitely true that x is between a and b), we instead assign decreasing plausibility to deviations. So for example
y ~ normal(0,sigma) means we find it less and less plausible that y/sigma would be more and more distant from 0 and beyond a distance of 3 or so it becomes dramatically implausible.
That’s the notion of Bayesian logic in Cox/Jaynes theory. Plausibility is assigned by our knowledge, and is a real number that sums up across all the possibilities to equal 1.
Also, this makes it clear that the diffusion process is maybe not the best process. From a causal perspective obviously the vote share on day i comes from the vote share on day i-1 and some number of people potentially changing their minds. But from an inference perspective, it’s just as true that if we KNEW the vote share on day i+1 we’d expect that the vote share on day i (backwards in time) would be near to it (things change somewhat slowly) so inference is bi-directional even if causality isn’t.
So what’s the advantage of using the “cannon” over my primitive slingshot?
I think that’s a good question that we too much take for advantage as Bayesian statisticians. I get asked this all the time by machine-learning researchers in natural language.
You quantify uncertainty in your predictions, you can include prior knowledge if you want to (not including any is a form of prior knowledge), and you can fit the amount of smoothing you apply rather than hack it. You can also calculate event probabilities (e.g., probability that Clinton wins), and make predictions into the future with the time series model. It gives you the right information for making decisions (e.g., betting on outcomes, making plans to move to Canada, etc.).
Why is the number “0.25” in mu’s prior any less of a “hack” than whatever knob controls a smoothing widget.
Agree it is. We could perform inference for this as well. Our prior though should be on fairly small updates– that was the entire point of the exercise.
The 0.25 is cast in terms of probability, so it gives you a coherent framework for both defining the number and reasoning about its effects. In practice, we typically build hierarchical models where the constant hyperpriors aren’t very sensitive at all. Then, of course, the lower-level likelihood decisions and choice of prior distribution can matter.
Daniel –
You’re interpretation of shrunken_polls and mu is what I had in mind. And yes, I just used a random walk for the unobserved state for simplicity. I don’t much like random walk state, as they have funny implications for the (unbounded) range of values you consider to be possible in the future. And, as you say, a given draw of the state will look like a random walk (and we probably think it moves slower). So I guess I’d prefer something more structural as the state.
Cool idea on the GP state. I’ll have a play! Though that might make it more difficult to jointly model Trump and Clinton, which is a cinch in the current setup.
For a simultaneous model of Clinton and Trump, you might get away with having a clinton timeseries, a trump timeseries, and an “other” timeseries. Put gaussian process priors individually over them, then declare the polls to be dirichlet vectors distributed around the means defined by the GP (assuming the polls give you both clinton and trump shares, so you can calculate “other”)
Another beginner Stan question: Is using
vector[T] mu
any different from
real mu[T]
Any reason why the notation for declaring size is different from vector to real?
in Stan a vector is a mathematical vector, whereas “real mu[T]” is an array of reals. You can for example multiply a vector by a matrix, but not multiply an array by a matrix (except maybe by explicitly or implicitly converting it to a vector).
These distinctions are in the manual under data types somewhere. The manual is QUITE comprehensive, actually one of the better ones I’ve seen for any Free Software project.
There’s a whle chapter in the manual on this. The basic types are int, real, vector, row_vector, and matrix, and each has their own size that attaches to the type. Then you can have arrays of any dimensionality with any of the basic types as members. The array size declarations attach to the variable, but maybe we should’ve done them the other way to avoid confusion rather than inheriting some of the same confusions as in C. There’s also a separate syntax for arguments of functions that doesn’t involve sizes.
It’s just unusual to see the mix: i.e. the size declaration suffixes to the keyword in one case & the variable in the other.
If you’re worried about random walks being unbounded, just do a random walk in the log odds space. For Clinton/Trump it shouldn’t matter but I think that if you wanted to look at some third party candidate (in terms of true preference; strategic vote intention brings in other issues), you would expect it to move more slowly, as you’d naturally get from using log odds like this.
Neat idea. Thanks.
Can one evaluate if random walk diffusion works better or a smoother gaussian process via some sort of predictive accuracy comparison?
If yes, I’d be very curious to see this done.
Well, you never really see the unknown “true preferences” except at the election results. So it’d be hard to see which worked better along the way compared to some kind of data.
But, you could for example plot spaghetti plots of individual state-space paths and see whether one or the other model does or doesn’t conform to your beliefs about realistic movements of the state space. For example if you see individual paths wiggling up and down on short time scales but you think things should be more stable, that would be a diagnostic tool you could use to help you specify the model better.
If you cannot ever see which strategy works better why bother changing?
Well, there are two notions of “works better”. One is “it works better at predicting something that we can occasionally observe”, and another is “it behaves in the way that we want our model to behave”.
For example, suppose you have a model for how the kinetics of some complex chemical reaction works. You’d want to encode that model as accurately as possible to correspond to what you think is going on, so that the inferences about the unobserved quantities are as accurate as you can get them. It’s a little like focusing a microscope. Why bother focusing the microscope if the thing you’re trying to see is smaller than the resolving power? Well, focusing it is going to give you the best chance of inferring the position of the tiny particle even though the particle will be too blurry to get a perfect position estimate.
I see what you mean. And I do actually funnily work in reaction kinetics. There there’s a similar debate between “microkinetic modelling” vs the rest of conventional empirical approaches.
But somehow I’ve gotten to be quite skeptical of the “it behaves in the way that we want our model to behave” approach.
Perhaps I am wrong.
Its always worth checking the goodness of your model against both your expectations and data. If it doesn’t meet your expectations then its probably a bug in your modeling or implementation. If it can’t predict correctly then its probably an unrealistic assumption.
@Daniel
Fair enough. That sounds entirely reasonable.
I agree that you should be using party ID data, but still… the “enthusiasm” (high differential response) is still data. I’d guess you’d want a two-dimensional state, enthusiasm and preference; and that both states should basically be AR(1) with correlated movement but different parameters (enthusiasm jumps around more, tends to regress strongly back towards the mean; preference moves slower but is less likely to spring back). With enough data, it should be possible to learn all 5 parameters you’d need for this model (2 for each AR process, plus 1 for the correlation of their movement).
Andrés Asensio shared this with me (it’s in Spanish): http://aasensio.github.io/elecciones2016/
A better job than my effort (he accounts for bias in polling firms), and again, all in Stan. Unfortunately it didn’t predict the outcomes very well!
I wonder why the elections (i.e. observing the state) does not bring the inference of the state space some weeks before and some weeks after the elections closer to the value_at _the_election. All the theta_i are estimated together, so they can be influenced by the future. Is this a matter of tuning the model? It seems that the polls are way noisier than expected, but the model is not capturing that until the election. I have not looked at the whole data preparation, but perhaps “Sigma_Sondeo” should be set larger.
All great stuff.
I made the same question myself during preparing this work. The value of sigma_sondeo (the estimated uncertainty for each individual poll) is
plainly extracted from their Poissonian character, so it neglects any systematic effect. As you say, even though the values quoted by the
polling companies (the square root of the number of interviews) are already large, I have the strong impression that they have to be much much
larger. This is, in essence, what happened in the last December elections. Almost all the polling companies were wrong because they were
underestimating their uncertainty. I have plans to see whether it is possible to infer some asymmetry in the sampling distribution. It is
a well-known fact (at least in Spain) that people voting to right wing parties tend not to answer that in the polls, while the opposite happens
for left-wing voters. Additionally, it is also well-known that abstention is more volatile in left-wing parties.
Layman’s question: In the formulæ in this post, I see several instances of a private use Unicode character, U+E23A – a character without a set meaning, whose appearance depends on the system. It shows to me as a Chinese character; I thought it was cool that statisticians were using hanzi in math, but then my friend told me it was a blue “play” icon in his system.
Looking at the source, I think it corresponds to \mathcal{N} in MathML. Is there any widespread practice where the private-use char U+E23A corresponds to a calligraphic N, or is our MathML (or whatever) bugged? I stumbled upon a \mathcal{N} in Stack Exchange and apparently it was rendered correctly. (I think ideally \mathcal{N} should be U+1D4A9, MATHEMATICAL SCRIPT CAPITAL N).
That’s really good to know. Bob’s always telling me off for using mathcal. I’ll use \mbox{Normal} in the future.
I can’t read the formulas in the text here. I didn’t try to debug what’s going on in my Mac’s Chrome and FireFox browsers. Sometimes in the past I’ve seen pages that look good if the O.S. is Windows, because of the fonts on Windows, but I see MathJax is being used here, so I’m stumped.
Would it be possible to print to PDF and put the PDF up, just as a quick way to make the inline formulas available? I am really looking forward to reading this post in full.
Possibly of interest, possibly obvious: if I read the model correctly, conditional on the parameter(s) the state-space part is a linear-Gaussian state-space model. Thus it is possible to integrate the state variables out in closed form using a Kalman filter type loop, whereafter Stan’s HMC needs to move only in the space of the parameters. Though, if computation time is not a bottleneck, this may be only harmful as the model is not immediately grokkable from the Stan code anymore.
I experimented with a somewhat similar model — different parameters/priors, simulated data, no application, and I have only one “poll” per time instant, but based on this it should be straightforward to use the same trick with the poll-averaging-model, too.
Code: https://github.com/juhokokkala/kalman-stan-randomwalk
Writeup: http://www.juhokokkala.fi/blog/posts/kalman-filter-style-recursion-to-marginalize-state-variables-to-speed-up-stan-inference/
Kalman filtering came to mind to me as well. With this situation I think the advantage that the direct modeling approach has is both interpretability as well as flexibility. For example, the suggestion elsewhere above of transforming the gaussian process through a sigmoid function to ensure bounded 0-1 range.
The other advantage of using KF here is that you only use information available at t to calculate the state at t. If you code it up as I have, the inference is about what you believe the state was at t given all the information available today, including information from after t.
It’s not clear that’s an advantage. If you wanted to know what the situation was say May 24th because you wanted to know how public opinion affected some other process that you’re studying that occurred on may 24th… then you’d want to use your best estimate of what was going on May 24th.. Information from after may 24th is relevant to your best inference. On the other hand, if you’re trying to figure out how to make decisions about something, and you know when you make the decisions you won’t have information about the future… then you want to limit the influence of future info on the inference. They’re both relevant to different questions.
To me, the question I have today is how much variability has there been in public opinion over the past year or so, and for that it’s relevant to use bi-directional inferences.
Daniel Lakeland: Yup, I agree on both advantages of the direct modeling approach.
James Savage: Actually, in my example, I in the end used a smoothing pass to sample from the states, so that all information available today is used and the sampler thus targets exactly the same thing as the direct modeling approach. There would be an interpretation problem with using the filtering distributions of the KF (those using information only upto t): when the parameters are given priors (as in: not fixed), information from future leaks into the filtering distributions via the parameters anyway. Because the ‘filtering distribution’ of the sampler would be p(state | information only upto t, parameters) but integrated over the parameters using the distribution p(parameters | all information available today). This construct does not have any reasonable interpretation that I can think of.
I’ve created a version of this script in python and pystan (I hope without bugs) https://github.com/eliflab/polling_model_py .