Discussion of statistical graphics typically focuses on individual graphs (for example here). But the real gain in your research comes from integrating graphs into your workflow. You want to be able to make the graphs you want, when you want them.
At the same time, the graph have to be good enough that you can learn from them. So no Excel-style bar graphs. It doesn’t matter how good you are at making excel-style bar graphs, you’re not using graphs effectively.
Not so good
For example consider this graph accompanying a news article by German Lopez:
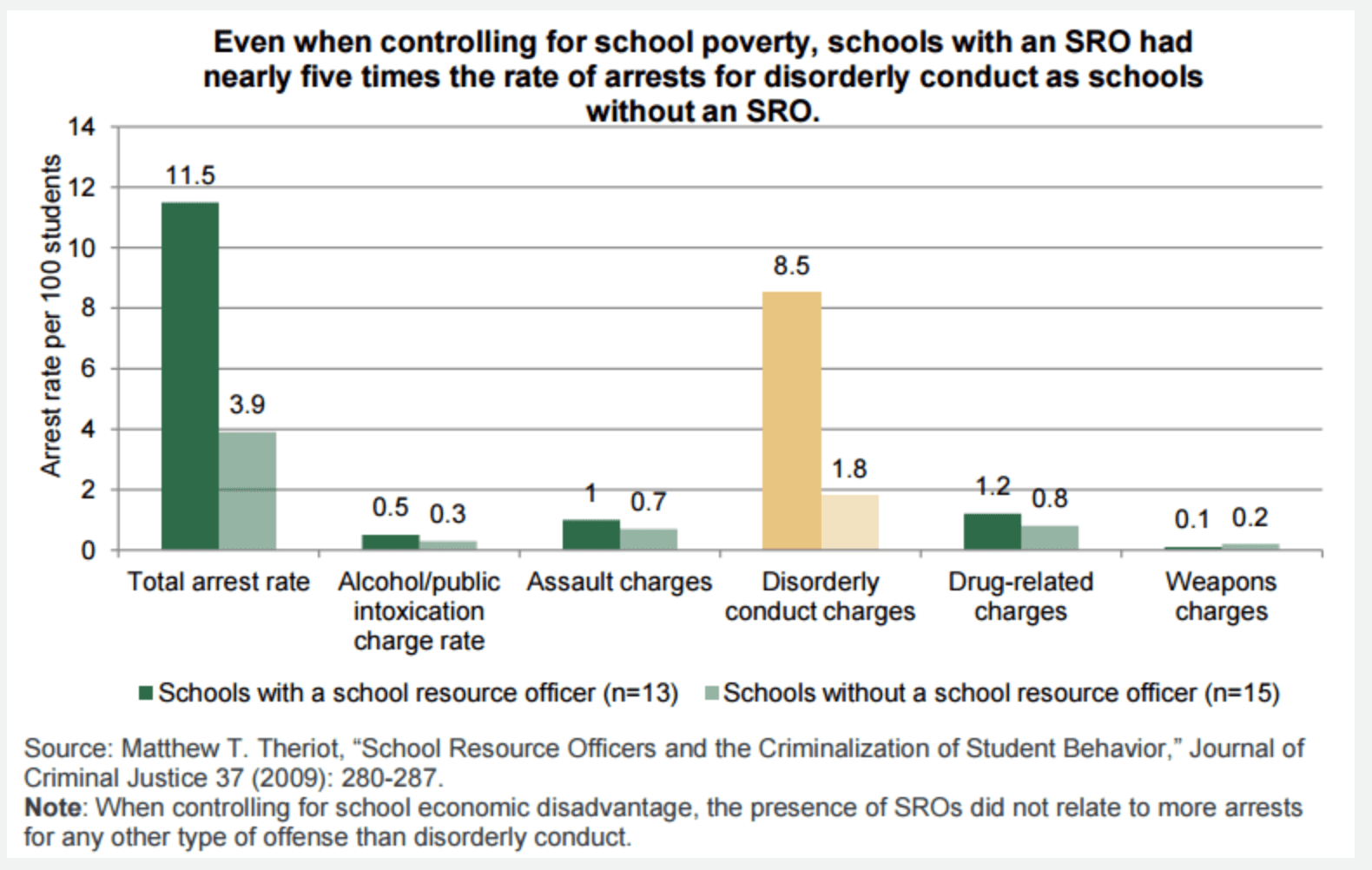
This graph isn’t horrible—with care, you can pull the numbers off it—but it’s not set up to allow much discovery, either. This kind of graph is a little bit like a car without an engine: you can push it along and it will go where you want, but it won’t take you anywhere on its own.
So good
What I like to see is when a researcher uses graphics as a way to understand data in a way that they couldn’t learn by just looking at a few numbers. A good positive example here is Dan Kahan, for example here:
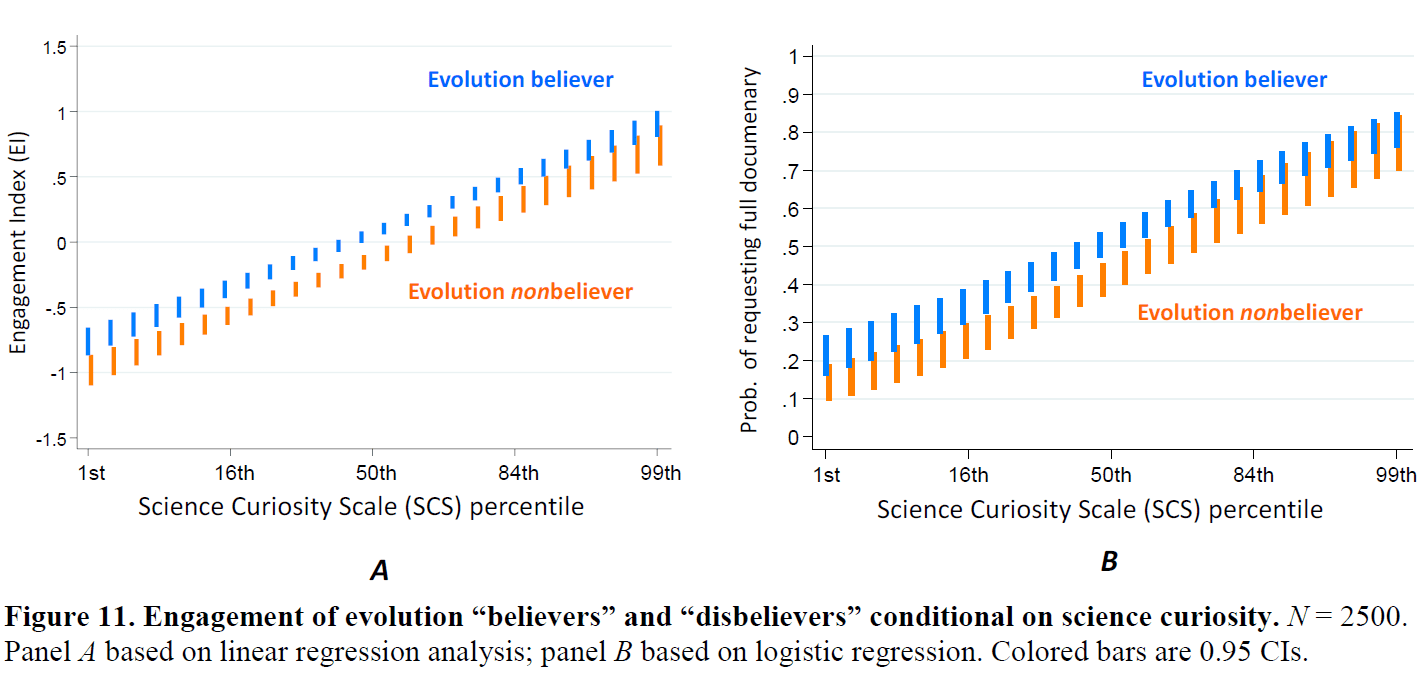
This is not such a wonderful graph—it’s not a graph I would make, and I think all those little bars are misleading in that they make it look like it’s data that are being plotted, not merely a fitted model.
But forget about the details. My point is that if you look at this and other posts by Kahan, you see he’s using graphs as a discovery tool—not as an end in themselves, but as a way to understand what he’s doing. And that’s what it’s all about.
I’m just in the middle of re-reading Cleveland’s “Visualizing Data” – such a wonderful book! He repeatedly emphasizes how important it is to visualize the data (for discovery) before doing a more formal statistical analysis. He has some examples showing how a “rote” analysis has led the investigators to wrong (or probably wrong) conclusions.
It seems to me that graphing data is a great way to implement the garden of forking paths: after looking at enough scatter plots, the best analytic approach will appear obvious, without a single statistical test having been run.
Nick:
In our 2011 paper, Jennifer, Masanao, and I recommend analyzing all comparisons using a hierarchical model. The best way to handle the garden of forking paths is not to pick one path retroactively or even to pick a path ahead of time, but rather to analyze all the paths together.
You are of course correct — was being flippant when describing this as a way to implement the approach. In the context of the pattern-fitting research discussed in other posts (himmicanes etc), it just seems that coming to terms with the data through graphing everything possible would be an effective way to identify the relationships that will later be shown to be ‘statistically significant’, without having to subject the data to formal tests. At the extreme, if one was advising researchers whose general approach was to using conventional methods to test imprecise hypotheses, would it actually be harmful to gain a better understanding of the data before fitting the regression?
Solution: Clear separation of the exploratory from validation. Graphing freestyle is good for exploration.
But during validation one must follow a pre-defined protocol without too much improvisation.
The big problem is that because our main goal became publication-number the distinction between exploration & validation became irrelevant.
This is why it’s so important to have easy ways to make lots of different types of plots and to slice the data in different ways. My impression is that R is much better for this than other widely used tools such as excel or iPython.
Everything can be misused, that’s for sure. Sometimes you can get smarter about it, like withholding data from a training set for later testing with.
Sometimes the examination might be as simple as using logs to see if the log data are nearly normal when the original are not. I don’t see that as leading down the garden; it just lets you use the well-understood machinery of the normal distribution.
Having advanced from “eeew” to “ouch” to “not wonderful,” I’m really quite pleased w/ myself.
But I’d be thrilled to see how Andrew & others would graphically report these data. Or actually not these very data but data that are a tad more interesting to report on & that I used this same technique (logistic regression w/ 0.95 CIs denoted by evenly spaced color-coded bars)
See <a href="this post“>this post for details & for link to the data
You have four categories and once continuous, so plot/compare the four distributions of the continuous. For example, start with histograms:
http://s32.postimg.org/qwmn0398z/Cup.jpg
Well, as you now, the data comprises 2 continuous predictors, and a binary outcome variable. The “categories” — “high” & “low” religiosity — are part of the reporting strategy.
Maybe histograms are better than the strategy I used — a scatterplot w/ lowess lines, followed by logistic regression w/ graphic illustration of predicted probabilities at values of interest.
But I don’t think looking at examples of histograms in general can establish that. Only *using* histograms in the way you are imagining — showing *us* the picture in your mind’s eye– can. You can’t win the “Cup” unless you do that.
So show us! That’s why I posted the data.
And Andrew will show me, I hope, what’s better than the insidious colored bars for representing the precision of the regression model estimates. I can’t tell if he thinks I should do something else to help people visualize the precision of the model estimates (I *hate* shaded confidence bands — they direct attention to big blotches of ink form which inferences can’t be drawn), or thinks I just shouldn’t bother modeling but should be content to present the raw data in a manner that is even better than scatter plot w/ lowess lines superimposed. (If he is just objecting to using the regression-derived graphic w/o raw data to show that the graphic is a fair picture of the raw data– I agree!)
Doh– you did show us! Didn’t see the link. :@ I know what you are going to do to me for missing that — graphic reporting *is* a contact sport, after all, & hence the “Cup.”
Is that better than scatter plot & model? 4 histograms requires reader to do a lot of work to detect the contrats. Isn’t it better to get all the information — if possible — into *1* graphic?
But for sure you are in the lead for the “Cup”! Thanks!
Thanks, I suppose you can make the histogram bars transparent or fit densities instead to get it all on one plot. That one was just supposed to be “for example”. I’m interested to see what approaches others would come up with.
I don’t know how much there is to say about the data. I think it is clear from those histograms that below average religiosity score and disagreement with the AGW statement is associated with right leaning score on the political orientation test. In contrast, *above* average religiosity score and *agreement* with the AGW statement is associated with a left-leaning political orientation score.
Etc/etc (the other two are in between). What more is there to say until I have some model/theory to explain this? Then in that case I would add a second column of histograms showing data simulated from my model.
Maybe not much more to say except—
1. your statment *above* average religiosity score and *agreement* with the AGW statement is associated with a left-leaning political orientation score” made me realize that I incorrectly indicated what the median-split “relig” variable means: 1 is actually below avg. in religiosity, and 0 above… Secular liberals are more convinced of AGW than religous ones. That raw data & regression model show that. YOur histograms too (once relig = 0, = 1 clarified). But secular conservs also slightly more likely to be disbeleivers; the interaction means religiosity just flattens things out. A tiny bit.
2. But then question is whether we can say more than just that there is interaction. Or what reporting strategy helps to make the extent, significance (practical) of ineraction clear. I think the strategy I used shows it is pretty trivial even if “significant’ in statistical terms
BTW, win the cup or not, you are going to be awarded an official “Gelman Graphic Reporting Challenge” *mouthguard* (also very useful) for helping me to fix the median-split variable (I added one that is coded in intuitive way w/ “1” as higher in religiosity, “0” as lower)
That aspect did seem odd, thanks for clarifying. Also, since you haven’t yet offered a prize sufficient to entice me from “anonymity”, would it be ok Andrew accepted it in my honor? He did provide the forum for this after all. Custom labelled mouthguards are available, so you have no excuse there:
“This is where it’s all about you. Make your statement. Get the best protection for your teeth — plus personalization to make your Gladiator unique to you or your team. Think big and we’ll make it happen.”
http://www.gladiatorguards.com/personal-identity
Yeah sure. But don’t count your chickens! Nukey Thompson” just registered for the contest…
I noticed the “continuous” variables are not really continuous. What about this? Where “cup” is what I downloaded earlier from your site, with all rows containing NA removed, using R:
###
RAcat=paste(cup[,2],cup[,3],sep=”_”)
tmp=unname(sapply(RAcat,function(x) which(unique(RAcat)==x)))
tble=table(tmp)
N=sapply(tmp, function(x) tble[which(names(tble)==x)])
plot(cup[,2],cup[,3],col=c(rgb(1,0,0,.5),rgb(0,0,1,.5))[as.factor(cup[,5])],pch=16,
xlab=colnames(cup)[2], ylab=colnames(cup)[3], cex=log(N),
main=c(“Size: # with Relig/Polit Score pair”,”Red: AGW=0; Blue: AGW=1″))
###
http://s32.postimg.org/4zhq5fu1f/Cup2.jpg
Red/Blue are just transparent so the mixed colors roughly indicate the proportion, but you could make the proportions correspond to a precise color scale.
Posted your entry at site & invited reactions. Thanks!
Well, none of us is *really* continuous but all we can do is try! But I think religiosity (143 levels) & left_right (31) can be treated that way for various data reporting/analysis purposes–unless there is beter way.
I’ve posted the new entry; “Nukey” will have work cut out for him.
Feel free to add a comment at site to explain why this is better than “not wonderful” & by how much!
All I can say is that once I looked at that most recent plot posted above, I thought completely differently about this data.
Interesting. But surely you can say more? What had you been thinking before & what do you think now? How was your understanding of the thing n the world that the data represent affected?
BTW, did you ever hear of that guy who got hit really hard in the head & went from being a plain schmoe to a world-class mathematician? If you knew exactly where you had to hit arrange to get hit in the head to achieve this (and it has to be super hard; I mean, I think the guy was in a coma for like 6 mos), would you be tempted to do it? And without the protection of course of the Gelman Graphic Reporting Challenge Cup?
>”Interesting. But surely you can say more?”
Not really, other than I assumed these measures were continuous and not heavily skewed.
>”BTW, did you ever hear of that guy who got hit really hard in the head & went from being a plain schmoe to a world-class mathematician?”
No, but I have heard of people whose cerebral ventricles fill with fluid to the point it begins compressing/destroying the surrounding tissue. After enough years of this they have little cortex left, but apparently without affecting their success/behavior significantly.
>”If you knew exactly where you had to hit arrange to get hit in the head to achieve this (and it has to be super hard; I mean, I think the guy was in a coma for like 6 mos), would you be tempted to do it?”
See above, I’d think a gradual approach to crude neuromodification would be more likely to yield success.
They aren’t normally distributed, but not skewed either, at least in sense of mean & medians being in different place. They are more bimodal–you find more people closer end points on both ; but still lots of people in between (the world is that way, no, w/r/t these latent dispositions?). Here’s religiosity & here’s left_right.
They are not continuous … well, data can’t be literally continuous. But it is odd to think of them as something else — categorical, ordinal? — when they have 144 & 31 levels! I think it is more useful not to figure out if data are “really” one thing or another; given that they are not really *anything*, the only interesting question is what way of thinking of them (for modeling) helps us to make the most useful inferences.
I think your last graphic has the nice feature of showing how outcome varies in relation to all values of both (not literally) continuous variables; my scatterplot reduced religiosity to 2 levels.
But one thing I don’t like about yours is that it the weighted markers gives visually misleading sense that observations are massively concentrated at extremes; that space between is like interior of Australia in terms of population.
I was moved to post a scatter plot of religiosity x left_right in part to create a picture of the data that, by removing the weighting, corrected this impression.
I think a normal person (one who hadn’t been bonked really really really hard in cerebral ventricals or whatnot) would either form very distorted idea of what the data looked like or would be baffled — unless he or she had first seen a scatter plot w/o the weighted markers. Even then I think the person would have a hard time figuring out what was going on, frankly (mouthguard is in, right?).
A genuine transparency would have the nice feature of your graphic w/o the distorting ones, I think.
And if you saw it, then maybe you would actually have an *interpretation* of the data? And maybe mine would change?
Why not comment at my site? I bet no one is reading this besides you & me! Do you mind if I reproduce our colloquy there?
For sure you have been bumped, too, from atop the leader board. By a guy who insists that if he wins the Cup, it be given to you. Apparently I totally misjudged how coveted it would be by the competitors…
Sorry, I got busy. Please make sure that, whoever wins, the cup ends up…you know where