Brendan Nyhan writes:
I’d love to see you put some data in here that you know well and evaluate how the site handles it.
The webpage in question says:
Upload a data set, and the automatic statistician will attempt to describe the final column of your data in terms of the rest of the data. After constructing a model of your data, it will then attempt to falsify its claims to see if there is any aspect of the data that has not been well captured by its model.
I can’t imagine this idea could really work with today’s statistical technology. But I’m supportive of the idea. You have to start somewhere, and even a demo project that doesn’t really do much will still give some insight into what can be done, and what are some useful next steps. So I wish them luck.
To try it out, I entered in this dataset of well-switching in Bangladesh, which we used to illustrate logistic regression in chapter 5 of ARM.
In the first version of this post I reported that running the program with this dataset returned an error, but commenter Zbicyclist pointed that the file had some missing data, and the webpage for this program did very clearly say that no missing data are allowed (which is the case in Stan as well). I went back and removed the rows with missing data (yeah, I know, imputing the missing values would’ve been better) and reran, and then I got the following result:

Fair enough. So I waited a few minutes (actually, I typed the above paragraph and loaded in the above image) and then hit refresh on the page.
It then gave me a 6-page report, which didn’t look so bad! It pretty much did what I might do—almost. It fit a model, plotted a bunch of residuals, and computed some numerical summaries.
I’ll give some comments, but first, here’s the report:
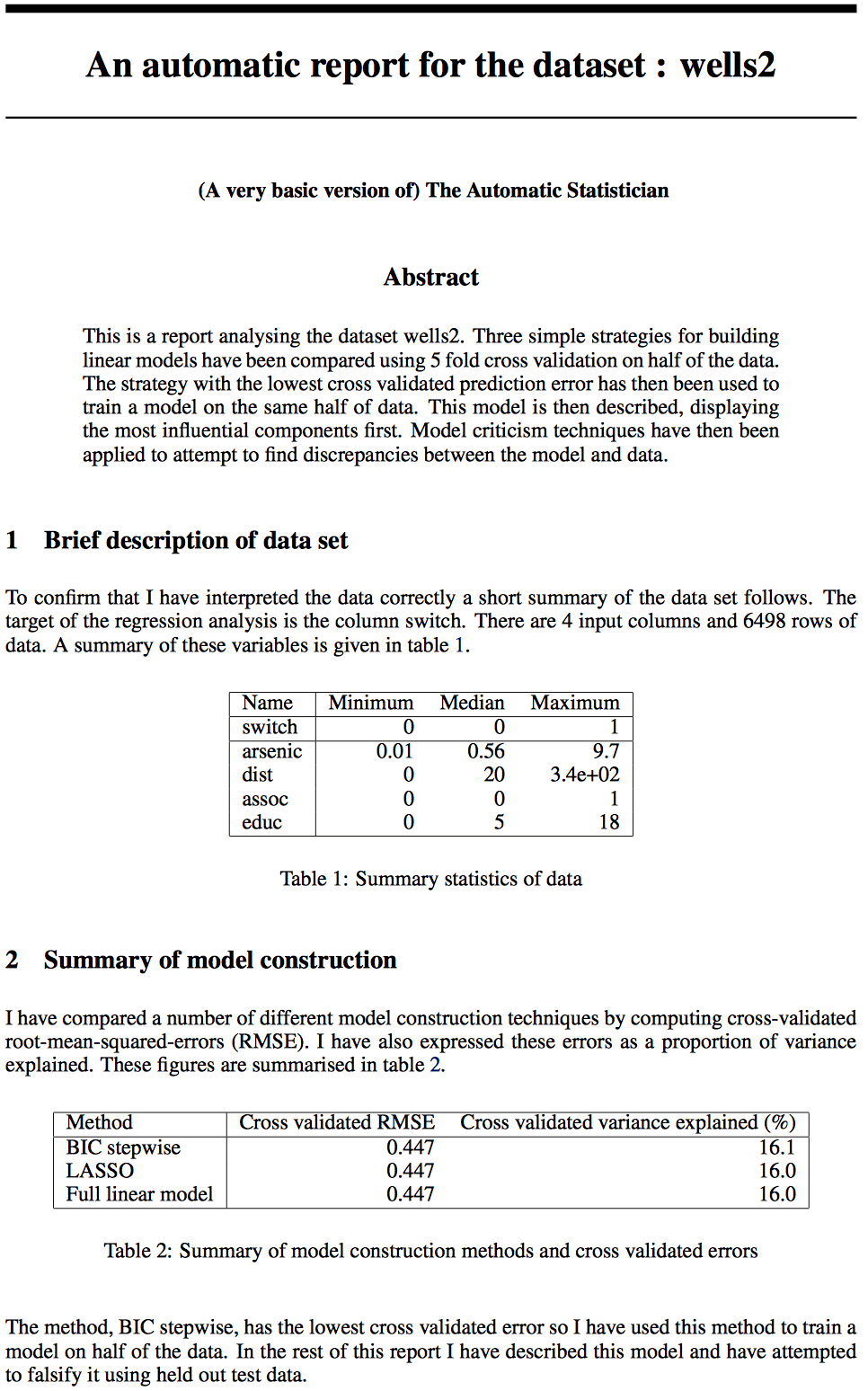

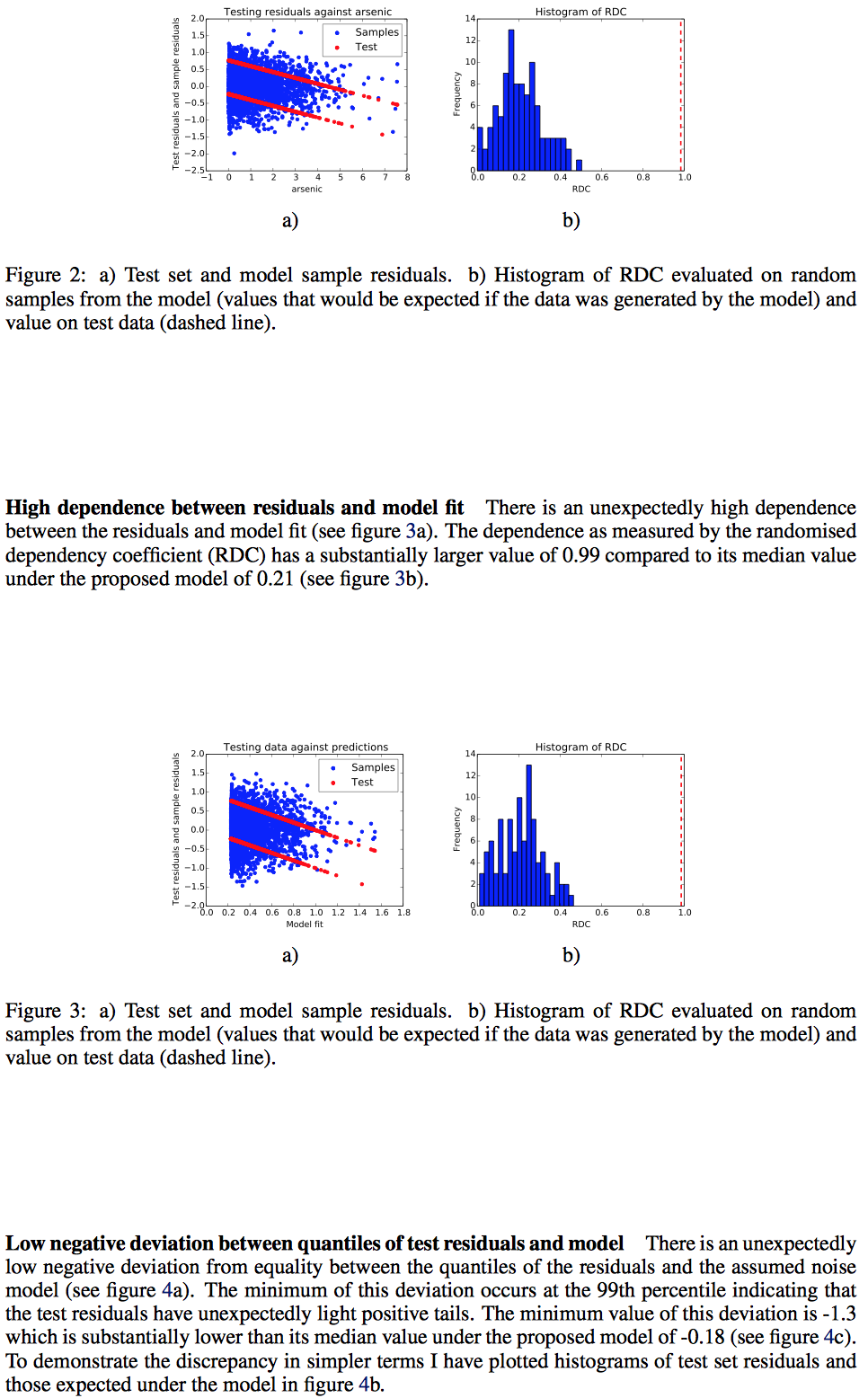
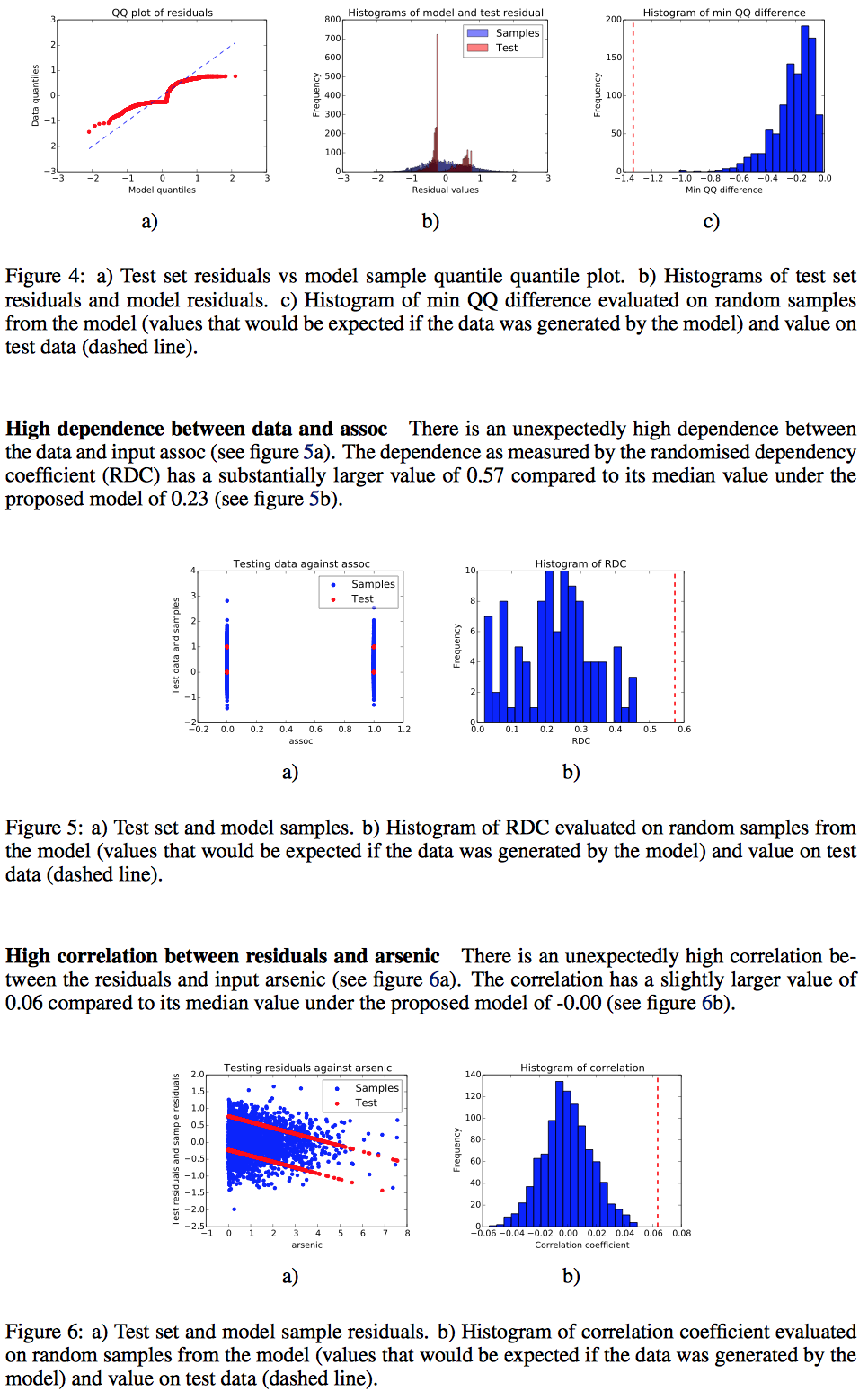
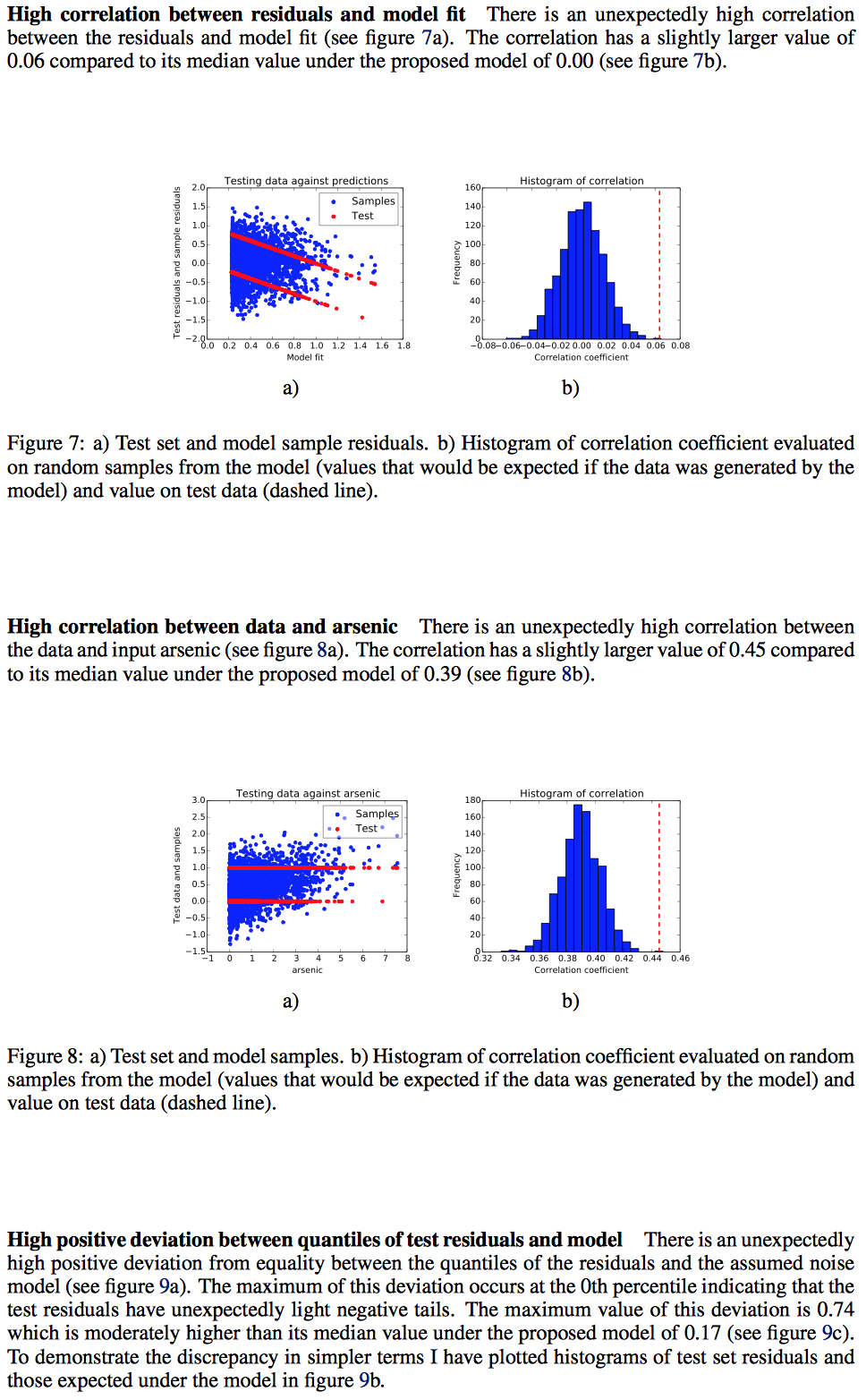
And here are my quick thoughts:
1. As I said before, it looks pretty good. Small crisp graphs, clear captions, clearly-labled sections, and a fairly seamless integration of the canned phrases so that it reads like written English, not like robot-speak.
2. It’s mostly transparent. What I mean here is that, when it has natural-language constructions, it’s typically pretty clear to me what was the underlying computation being done.
3. The report is written in the first person (“I have interpreted the data,” “I have compared,” etc.). I think I understand why they did this—it personalizes the computer program, maybe that’s a good way to get the user involved—but I find it confusing. I’d prefer for “I” to be replaced by “Autostat” (a shorthand to the name of the program, “Automatic Statistician”), thus “Autostat interpreted the data” etc. One big trouble with “I” is that it’s easy to imagine a researcher cutting and pasting chunks of this into a report without ever reading it!
Just imagine if Ed Wegman got his hands on this program.
4. The program fit a linear regression model which of course isn’t ideal for a binary outcome. But that’s fair; the documentation actually said that all it can do is linear right now, as this is still a prototype version of the program.
5. The data came from a survey of people in some villages in Bangladesh where some of the water had high levels of arsenic. The people being surveyed were living in homes that had high arsenic levels in their drinking water. The variable being predicted, “switch,” equals 1 if the person being surveyed expressed willingness to switch to a well of a some neighbor whose drinking water is low in arsenic, and 0 otherwise. The predictors are “arsenic” (the current arsenic level of the person’s well), “dist” (the distance to the neighbor’s well), “assoc” (whether the person is a member of a community association), and “educ” (respondent’s number of years of formal education)
I was surprised to see that Autostat only wanted to include arsenic as a predictor: when I was fitting the model for chapter 5 in ARM, I ended up including arsenic, dist, their interaction, and also educ.
What’s going on is that there’s a lot more information in the logistic than in the linear regression. Here’s a quick linear regression in R:
lm(formula = switch ~ arsenic + dist + assoc + educ)
coef.est coef.se
(Intercept) 0.21 0.01
arsenic 0.19 0.01
dist 0.00 0.00
assoc -0.01 0.01
educ 0.00 0.00
---
n = 6498, k = 5
residual sd = 0.44, R-Squared = 0.18
Umm, let’s rescale distance and education to make this more interpretable:
lm(formula = switch ~ arsenic + I(dist/100) + assoc + I(educ/4))
coef.est coef.se
(Intercept) 0.21 0.01
arsenic 0.19 0.01
I(dist/100) -0.02 0.02
assoc -0.01 0.01
I(educ/4) 0.01 0.01
---
n = 6498, k = 5
residual sd = 0.44, R-Squared = 0.18
OK, so with a linear model there really isn’t room to estimate coefficients for distance and education. Who knew?
Just to check, I better re-run the logistic regression:
glm(formula = switch ~ arsenic + I(dist/100) + assoc + I(educ/4),
family = binomial(link = "logit"))
coef.est coef.se
(Intercept) -1.40 0.06
arsenic 1.06 0.04
I(dist/100) -0.30 0.10
assoc -0.06 0.06
I(educ/4) 0.07 0.03
---
n = 6498, k = 5
residual deviance = 7383.6, null deviance = 8702.4 (difference = 1318.7)
Hmm, this isn’t quite what we got in our book, but there we had only 3020 data points and here we seem to have 6498, so as you can see I don’t have complete control of my dataset. Maybe I did something dumb like write the data into the file twice.
Whatever, no time to worry about this now. My real point is that the Autostat program does seem to have done something reasonable, given that it’s limited to linear models.
So this seems like an excellent start.
I think that for the program to be useful to researchers it should link to the code that fit the models, that way a researcher could play around and fit alternatives. (In the arsenic example, for example, once we’re fitting logistic regressions, we know we want to log the arsenic predictor and we know we want to include interactions.)
Andrew, row 141 in the data set is NA. “All data must be numeric. … There must be no missing data.”
If I can’t sleep tonight, I’ll clean the file up and try to rerun it and post the results.
I omitted cases with missing data from the wells file.
The analysis results are here:
https://docs.google.com/viewer?a=v&pid=sites&srcid=ZGVmYXVsdGRvbWFpbnxrcnVnZXJzaXRlM3xneDoxZDc4MWU4YWI5YmUzOWM4
which should be freely available. The variable “case” was added so I could say that the cases I omitted from the data are these:
case
140 (row 141 in the data, since there is a header row)
1718
1984
2000
2025
2088
2232
3620
4018
4025
5952
6103
which is only a handful.
I don’t know this data set at all, so my comments will be even more superficial than they normally are.
Part 2: Those RMSE values look pretty close to me, since they are all 1.87e+03. I would prefer to verbiage to say they are all pretty much the same, but LASSO is lower so we’re going with that.
I miss some of the standard regression diagnostic stuff.
Part 3: I hope some graphical expert can make some suggestions about the “decrease with assoc”graph, which is the usual mess of graphing a large data set against a dichotomy.
Section 4: This part attempts to “falsify the model”; I’d quibble and say this should be named “weaknesses of the model” but that’s personal semantics. In general, I find these sort of automated checks helpful because otherwise I find analysts skipping them (due to time, and because they can usually only provide negative information).
I look forward to seeing more coherent comments from whose who are more familiar with what this data is supposed to show.
The effort here is somewhat similar to what Lee Wilkinson was trying to do with AdviseStat, although that effort didn’t seem to be commercially successful.
zbicyclist: thanks for making this available
I guess you added the case variable as the last column. The program took the last column as the dependent varaible – which I assume should be the variable ‘switch’. With your input, the resulting model is trying to predict the case number by the other five variables…
Yes; I’m so used to having the dependent variable as the first data column that I skipped right over the documentation of “final column” and my analysis is useless. Consequently, I am REMOVING THE LINKED DOCUMENT referred to above, since it can’t help. My apologies.
How is this different from the sort of symbolic regression that was in packages like Eurequa?
How long before this goes Sokal?
Interesting, it might be best positioned as a expert provision of a second opinion on an analysis already done, which has benefited from being structured by “the creative human mind” as Jaynes put it. Similar idea to zbicyclist wanting some checks of work done by analysts because as he notes “I find analysts skipping them”.
Its is the structuring of the analysis that is creative, its implementation is mostly route, but then the noticing of what’s wrong and how it can be made less wrong that is again creative. So automating the middle part seems very sensible and would provide strong encouragement to statistical analysts to be more careful and thorough (given how easy it might become for collaborators and clients to get an “informed” second opinion about their work.)
And my guess most of the errors in statistical applications are in the implementation as it can be route boring and considered “low level work”.
Im curious as to why it is so difficult to deal with missing data in the input file?
For example in R the one line of code would be something like the following:
dat<-dat[is.finite(dat)]
dat<-dat[complete.cases(dat),]
Missing data cannot be patently ignored in this way since it may lead to a systematic bias in the analysis. Data can be missing for all sorts of non-trivial reasons which must be incorporated into the analysis. By only allowing complete data this program is either 1) limiting its usefulness to increasingly rare situations, or 2) leaving it up to the operator to figure out what to do with those missing cases.
The operator is in the best position to figure out what to do with those missing cases.
This is not new, but is tantalizing. See examples from econometric practice:
PcGets (now, Autometrics in PC-Give/Oxmetrics): http://www.nuffield.ox.ac.uk/users/hendry/Papers/EvaluatingAutomaticModelSelectionJan2013.pdf
RETINA:http://journals.cambridge.org/action/displayFulltext?type=1&fid=281026&jid=ECT&volumeId=21&issueId=01&aid=281024
Others: http://econ.au.dk/fileadmin/site_files/filer_oekonomi/Working_Papers/CREATES/2011/rp11_28.pdf
Pingback: Friday links: everything old is new again, and more | Dynamic Ecology
I hope this works out one day, because searching for phenomenological trends among columns of a table is absolutely the most boring task for an applied statistician, and one of the least efficient uses of our time. It’s akin to asking a brain surgeon to apply a band-aid, but OK because (most) statisticians are relatively cheap. What should the applied statistician be doing? I say we should be planning/reviewing scientific research studies, grokking specific scientific fields with high potentialllll, and tackling the problems that are too difficult or too rare for a computer algorithm.
Pingback: Links diversos: o Estatístico Automático e um pouco de história do R. | Análise Real
Hi Andrew,
Long time reader of this blog. I came across this work a while ago: http://jamesrobertlloyd.com/papers/kernel-model-checking.pdf
It has been on my reading list, but I think it goes at the heart of the model checking question that you post. Is this relevant?