Niala Boodho on the Afternoon Shift will be interviewing Yair and me about our age-period-cohort extravaganza which became widely-known after being featured in this cool interactive graph by Amanda Cox in the New York Times.
And here’s the interview.
The actual paper is called The Great Society, Reagan’s revolution, and generations of presidential voting and was somewhat inspired by this story.
Here’s the set of graphs that got things started:
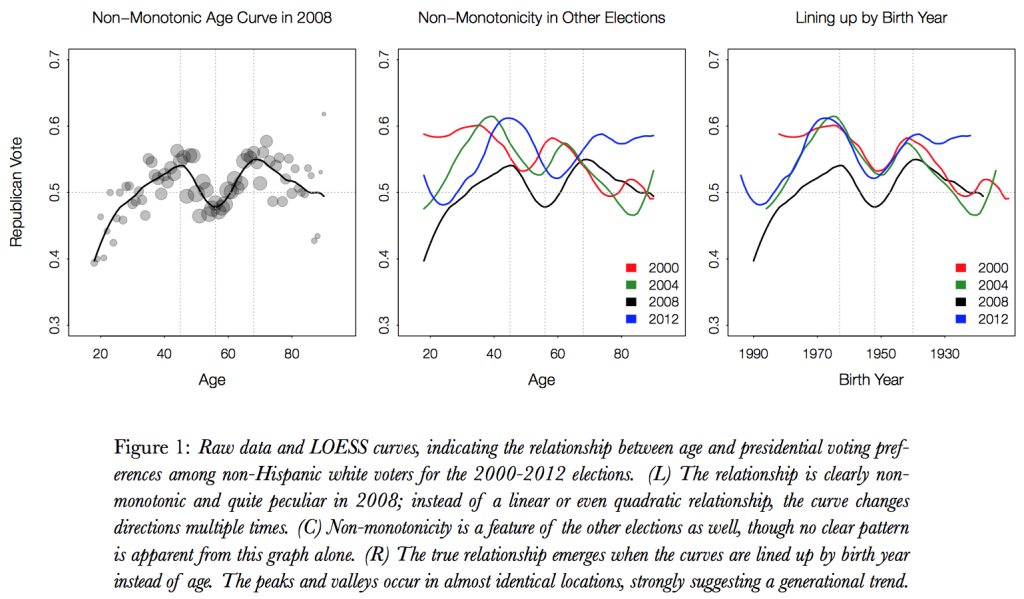
Here’s a bit more of what we found:
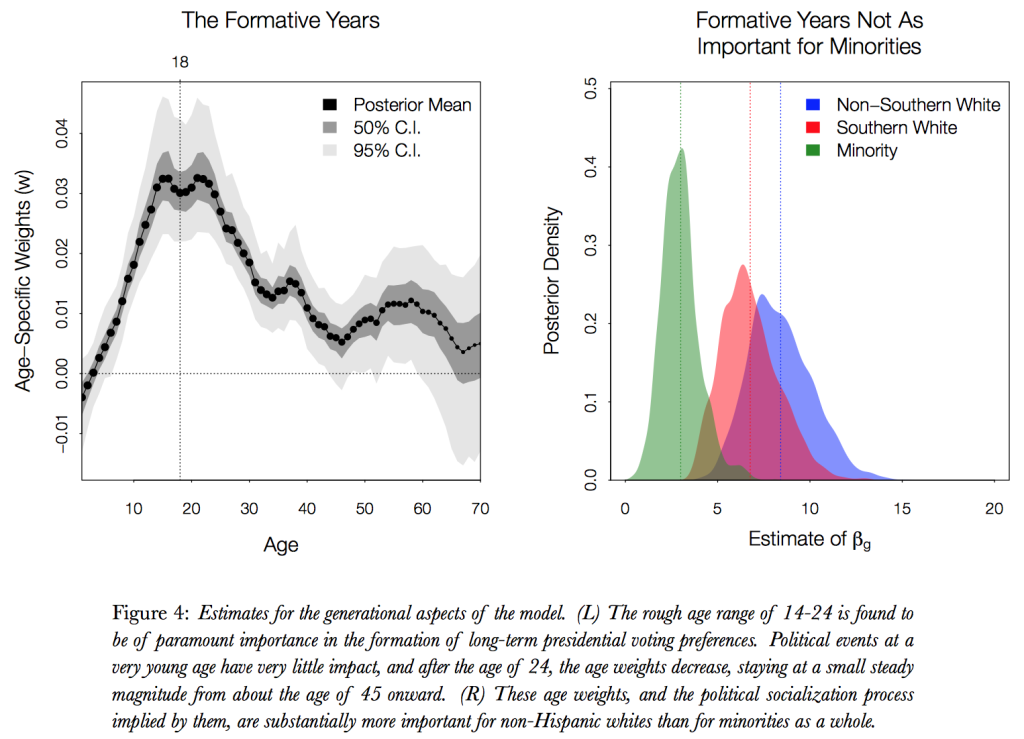
And here’s some more:
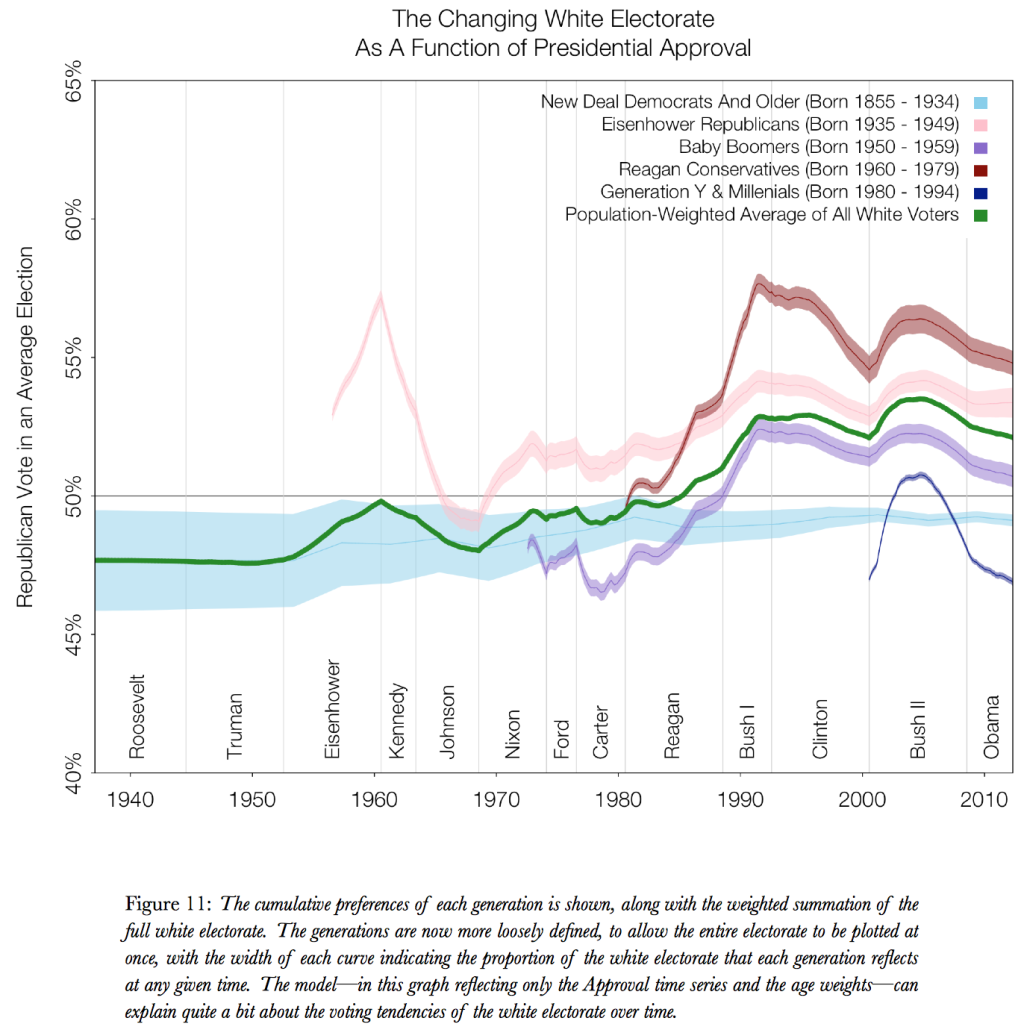
I love this paper, I love Yair’s graphs, and I love how we were able to fit this complicated model that addresses the age-period-cohort problem. Stan’s the greatest.
I loved these graphs too – until I realized you called me a “Reagan Conservative.” What happened to Gen X?
That said – and I re-iterate an earlier point that I made (and regarding which I owe Daniel Gotthardt a response, I think – sorry) – I think there is a ton of progress to be made thinking about the age-period-cohort problem in different contexts with different types of data (and data collection). Sometimes it feels like people just shrug and say “nothing to be done” and… well, I’ll hand back the mic:
….
The discussants of the paper at hand correctly note that there can be no general solution to the age-period-cohort problem: as has been noted by Fienberg and Mason (1979), Holford (1983), and many others,… For any dataset, there is a space of possible estimates, all equally consistent with the data, but with different linear trends in age, period, and cohort, and no way from the data alone to choose among these.
On the other hand, some of the estimates seem to make more sense than others….some methods of constraining the possible space of solutions seem more reasonable.
jrc:
Yep, it was me, but don’t worry about it, you’ve no obligation to do it.
Andrew:
These are probably some of the best graphs I’ve seen so far and I really like how you are trying to disentangle age, period and cohort effects. Maybe I will steal some ideas for my next work on changes in regional mobility. ;-)
I love the graphs too! What did you all make them in?
I’m pretty sure it was Excel, with some awesome Visual Basic
Yes, nice graphs — or perhaps more to the point, nice use of graphs.
But belonging to a cohort called “Eisenhower Republican” is a bit weird. I would have called it “pre-Boomers.”
Also interesting/timely because I have been suspecting that cohort effects could plausibly affect results of the stereotype susceptibility research I’ve been looking at lately — e.g., in my own Eisenhower/Kennedy era formative years, the then-current zeitgeist that women shouldn’t do math (i.e., that it was a male privilege) seemed to outweigh any stereotype there might have been that women were not good at math.
Maybe you should have just used the birth year ranges & refrained from the more colorful names?
They look so nice… but I feel unfulfilled without being able to play with the data myself. Where is it?
Would you be willing to post the Stan model code as a teaching example with a compelling application? (Or the model for the 2012 state-level election analysis … though that may have been pre-Stan.)
@question and @NU: Very good questions. I’m all for reproducible science and would like to see more of it. The papers don’t have the Stan code, and I can’t find Yair’s thesis online (how is that possible these days?).
I’m not sure if Yair has the rights to redistribute the data, but he should be able to share the Stan code.
Stan evolved out of Andrew’s project to fit exactly these models and Yair was our first power user. From what I recall, the only issues were setting weakly informative priors and using a non-centered parameterization (what we originally called “the Matt trick”); but I also recalling it taking some fiddling to get it to fit. Stan’s evolved a bit in terms of adaptation stability and speed since then, so hopefully it’s easier to fit now.
Hi everyone, thanks for the comments!
1) All graphs are made in base R. As Andy has written before, you can make really nice plots when getting away from the default settings.
2) A lot of the data is publicly available, like Gallup data, NES data, and so on. The only non-public data is the survey results from the 2012 election. I’ll see if I can distribute that, and if not I can post the remaining data otherwise.
3) The Stan code is certainly shareable, but I’ll clean it up first.
Sorry I can’t get it all posted right away. I’ll work with Andy to post once I get these things all together.
Pingback: Age/period/cohort voting | Stats Chat