With some upgrades from a previous post.
And with a hopefully clear 40+ page draft paper (see page 16).
Drawing Inference – Literally and by Individual
Contribution.pdf
Comments are welcome, though my reponses may be delayed.
(Working on how to best render the graphs.)
K?
p.s. Plot was modified so that it might be better interpreted without reading any of the paper – though I would not suggest that – reading at least pages 1 to 17 is recomended.
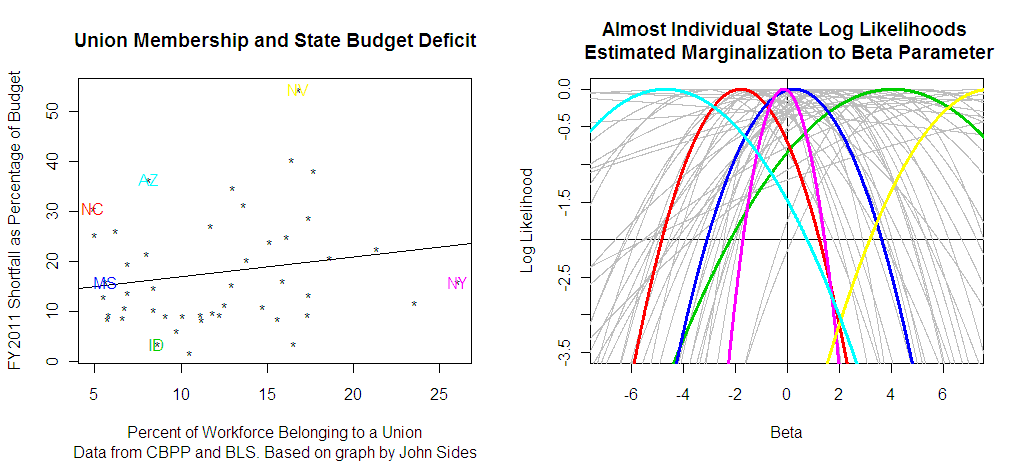
I'm still not sure what I'm looking at, but at least I start to get the idea. Correct me if I'm wrong, K? You're fitting a model (presumably a Bayesian hierarchical model) in which the shortfall as a percentage of the budget is a function of the percent of the (state government?) workforce that belongs to a union, plus perhaps some other parameters, plus a "state effect." The parameter "beta" is the state effect. The states labeled in color on the left-hand plot correspond to the state effects (and uncertainties) summarized on the right-hand plot. So far, so good.
But I am nevertheless slightly confused. The main problem (for me) is that Id falls far below the (loess?) line shown on the left-most plot, while Ne falls far above it, but both have almost all of their "beta" probability above 0. Hmm, in fact, "No" (I'm guessing that's NOrth Dakota or perhaps NOrth Carolina?), Ar, and Ne all have high budget shortfall, but two of them have negative beta estimates and the other has a positive estimate. Perhaps there are other parameters in your model, such that No and Ar are predicted to have even higher budget shortfalls than they do, so they get a negative beta estimate?
I am interested in the answer, but not so interested that I am willing to read a 40-page paper. How about a 1-paragraph summary?
Also, assuming the points in the leftmost plot represent states, it would be nice to have them labeled with standard notation. For most of us, "Ha" does not conjure up "Hawaii" — although, hey, how many other states start with Ha, or even H? — and No and So have obvious problems. And it took me at least 30 seconds to figure out Di, although perhaps I should be embarrassed by that.
Overall, thank you and I at least see what you're getting at, but you're still making it unnecessarily hard for us readers.
Phil: See page 16?
As for Di – just the first two letters from the names in the file I downloaded – perhaps works better in Canada ;-)
K?
Sigh. Well, I tried.
1. Why are only some points and lines color coded? Are those the ones of interest? If so why don't we get rid of the mass of gray curves on the right hand plot. Doubt that they contribute much?
2. What exactly is the curve on the left hand plot? Is that some sort of best-fit or….?
Rahul: At least until I write that one paragraph summary Phil suggests – you will likely have to read some of the paper. I have also modified the plot given Phil's comments (the labeling of just the states I am drawing attention to seemed a less wrong idea).
There is one curve for each state, in words they represent what each state "says" about the beta coefficient and this "adds" up to the beta coefficient.
In paraphrasing a quote of Tukey's given by Horward Wainer, they force one to see whats going on in the inference for beta. (Maybe here, I should say hear).
The paper is about a fully Bayes approach, I thought this example might attract interest – but it does seem to be doing the opposite.
K?
K?, I think you have trouble putting yourself in the mindset of your readers. There are approximately a zillion things on the internet; the probability that someone will look at a couple of unexplained, uncaptioned plots that convey no obvious message, and decide on that basis to read someone's 40-page paper to figure out what the plots are trying to say, is very very close to zero. If you look at blogs or blog entries that people actually read (and discuss), you will find that almost all of them are written so that the typical reader of the blog can understand the main point within a few seconds, to maybe a few minutes at most.
I'm not sure what prompts the mismatch between your hopes and reality. Do you credit the blog's readers with being able to understand your point without any explanation? Or do you know that we can't, but you assume we'll be willing to take it on faith that we should read your 40-page anyway? (If you feel this, do you feel that we should read _every_ 40-page write-up everywhere on the web, or just yours, and if the answer is "just yours", why is that?)
I've tried several times to be helpful, and I'm trying again. If you want people to take an interest in your work — and why else would you be posting? — then you really need to write a simple description. And when I say "simple" I mean a description that an average reader of this blog will be able to follow in outline without reading supplementary material ( including previous blog entries). If supplementary material would be helpful you could make it optional.
I realize that Andrew sometimes violates this with a post like "Oh, boy, here's another one", where "here" is a link to something else…but many of us find that irritating and some of us don't actually follow those links, so please don't model your posts on that! But at least those links are often to simple things like news articles or maps or pictures that are themselves easy to follow, unlike your recent posts. It's one thing to link to a NY Times article or something; another to link to a 40-page academic paper.
I know you disagree with my advice here, since it's basically what I've said before and you haven't changed your ways. But I'm trying again. I'm beginning to question my own judgment about why I put in the time, though: Essentially I am criticizing you for trying the same failed approach again and again, but here I am using the same failed approach again!
What we've got here is… failure to communicate. Some men you just can't reach.
I gave up on K?'s posts and comments a long time ago. It's the best way, really.
I'll add (sorry if I am blunt):
1. Horrible choice of colors. The yellow is barely readable.
2. I am extremely skeptical that the mass of grey parabolas on the right hand plot convey any information to the reader. The colored ones are the only ones discernible. Things can still be chartjunk even if you used math to draw them.
3. "hopefully clear" for the text is a stretch of imagination.
4. "better interpreted without reading any of the paper" A straight line passing through a mass of scattered points? Sorry.
Agreed this is a draft. But you don't have to go out of the way to make it hard for readers to read it. e.g. changing the colors would take 10 minutes of your time but save, say, 20 readers a net 200 wasted minutes.
Keith, thank you for working to make this clearer – but as Phil suggests, there is way to go.
Part of my confusion is that I don't see that each data point on its own 'says' much that's useful about beta.
Beta is a slope parameter, we know it can be expressed as the (weighted) average of the slopes of straight lines that connect pairs of data points. (See various old posts on this blog.) Sets of more than one data point certainly tell us about beta, and it's reasonable that information from non-overlapping sets of data points could be added up, in the way you seem to suggest – although e.g. forest plots already do this.
But… in isolation, single data points on a scatter plot do not tell us about slopes. Sure, with enough assumptions maybe we can deconstruct the information about beta into contributions from single data points, but I don't see that this can be done without relying (heavily) on those assumptions. Your plots don't seem to show those assumptions, and so are not intuitive, to me.
If I've missed something important, I look forward to your brief description of how the methodology all fits together.
Phil: As is the custom to put it in Oxford – I am not ignoring your advice, I am chosing to disregard it. It simply does not fit in with my current priorities, objectives and constraints.
I felt obligated to post something given my earlier overly hasty post which drew comments that even with a lot of effort – it did not make sense.
I do agree mostly with your take on blogs. I checked my past emails for the reason I gave for wanting to comment and post to the blog – in the context of constraints on academic activities – a way to keep my "applying statistics in research" knowledge "current" and blogging seems to be good for that.
But I have discovered it irritates some and likley is a poor venue for what I want to do.
It also takes much much more of my time than I anticipated (without meaning to imply my time is worth more than others – its just "scarce").
K?
Rahul 1. I should also look at the color blind stuff that was posted some where on this blog earlier.
2. I have always thought that there should be one plot that shows all the data no matter how apparently uninformative – at least for the investigators to look at.
K?
Anon: Yes "e.g. forest plots already do this" that is the dual plot under strong assumptions (approx Normality and standard errors (scale) taken as known).
But they often do get the picture not too wrong.
This is explained (or at least mentioned in the paper). If you _whish_ you could search for "forrest".
The required assumption is that its OK to somehow pool over the other unknown parameters (e.g. intercept and sigma) – then the likelihood has a single unknown parameter (assuming the other parameters have now been adequately dealt with) and a single observation.
K?
I disagree about strong assumptions. Under mild conditions, modest sample sizes give effect estimates that are very close to Normal, and can be used to estimate standard errors with negligible error, compared to everything else that's going on.
I don't think you mean us to "pool" over other parameters. But, like others, I don't know what you do mean. When you have time, maybe you could explain, briefly.
Anon: If you are game for some "risky reading"
open my thesis http://www.stat.columbia.edu/~cook/movabletype/ml…
And just search for "batman" and just skim read about that and then read the reference about multi-modality in Normal-Normal random effects models.
This is more widely written about now and last summer at SAMSI, David Dunson was bringing attention to this to explain why non-parametric random effects models can be more efficient than parametric Normal random effects models.
But it is at your risk.
K?
p.s. for the realy nasty ugly fact about likelihoods read Stigler's the Epic story of likelihood (a really good read)
Sorry, I don't understand the relevance to this discussion of Normal-Normal models, multi-modality, batman, SAMSI, efficiency, or super-efficiency. I can't even find the reference to which you allude. So I give up.
In words of one syllable…
Please tell us how your plot works. Do it in a way that will make sense to us, and not just in the first words that cross your mind. That is all.