Details matter (at least, they do for me), but we don’t yet have a systematic way of going back and forth between the structure of a graph, its details, and the underlying questions that motivate our visualizations. (Cleveland, Wilkinson, and others have written a bit on how to formalize these connections, and I’ve thought about it too, but we have a ways to go.)
I was thinking about this difficulty after reading an article on graphics by some computer scientists that was well-written but to me lacked a feeling for the linkages between substantive/statistical goals and graphical details. I have problems with these issues too, and my point here is not to criticize but to move the discussion forward.
When thinking about visualization, how important are the details?
Aleks pointed me to this article by Jeffrey Heer, Michael Bostock, and Vadim Ogievetsky, “A Tour through the Visualization Zoo: A survey of powerful visualization techniques, from the obvious to the obscure.” They make some reasonable points, but a big problem I have with the article is in the details of the actual visualizations they show. Briefly:
Figure 1A looks like it should be on a log scale, also it has an unclear y-axis (I don’t think “Gain/Loss Factor” is a standard term) and a time axis that is not fully labeled (you have to reconstruct it from the title of the graph).
Figure 1B has that notorious alphabetical order, also some weird visual artifacts that get created by stacking curves, and a x-axis that is not fully labeled. (What is the point labeled “2001”? Is it Jan 1, July 1, or some other date?) Yes, I realize that one purpose of the article is to criticize such graphs (“While such charts have proven popular in recent years, they do have some notable limitations. . . . stacking may make it difficult to accurately interpret trends that lie atop other curves.). Still, it doesn’t help to list the industries in alphabetical order.
Figure 1C (see below) seems just wrong. If you look at the graphs, unemployment seems to have gone up by something like a factor of 10 in almost every sector! Something went terribly wrong here; perhaps each graph was rescaled to its own range, which wouldn’t make much sense in a small multiples plot. (For unemployment rates, I’d think you’d want zero as a baseline, or maybe some conventional “natural rate” such as 3%.) On a more minor note, it would help to put the labels on the upper left of each series rather than below the axes. Also, the colors don’t seem to add any information, and it’s a bit odd to list “Other” as the second or third category of industries–I still can’t figure out how that happened!
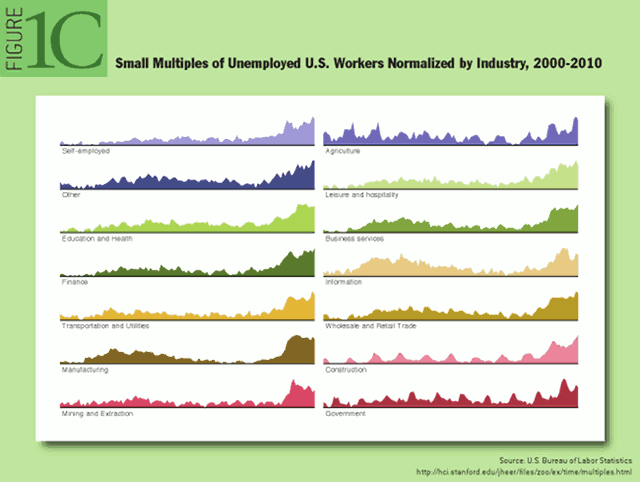
I could keep going here through all the other graphs in the article But maybe these criticisms are irrelevant. On one hand, they don’t matter because the writers of the article are simply trying to give an example of each sort of graph. On the other hand, I worry that people will see this sort of authoritatively-written article and take the graphs as models for their own work.
Is it important to get the details “right”?
What harm is done, if any, by having ambiguous labels, uninformative orderings of variables, inconsistent scaling of axes, and all the rest? From a psychological or graphical perception perspective, maybe these create no problem at all. Perhaps such glitches (from my perspective) are either irrelevant to the general message of the graph or, from the other direction, force the reader to look at the graph and read the surrounding text more clearly to figure out what’s going on. After all, a graph isn’t a TV show, readers aren’t passive, so maybe it’s actually good to make them work to figure out what’s going on.
At a statistical level, though, I think the details are very important, because they connect the data being graphed with the underlying questions being studied. For example, if you want to compare unemployment rates for different industries, you want them on the same scale. If you’re not interested in an alphabetical ordering, you don’t want to put it on a graph. If you want to convey something beyond simply that big cars get worse gas mileage, you’ll want to invert the axes on your parallel coordinate plot. And so forth. When I make a graph, I typically need to go back and forth between the form of the plot, its details, and the questions I’m studying.
If you wanted to say I’m wrong, you could perhaps invoke an opportunity cost argument, that the time I spend worrying about where to label the lines on a graph (not to mention the time I spend blogging about it!) is time I could be spending doing statistical modeling and data analysis. For me, the details of the graphing are absolutely necessary to the statistical analysis–decades ago, before I did everything on the computer, I spent lots and lots of time making graphs by hand, using colored pens and all the rest–but for others, maybe not.
Dot plots, line plots, and scatterplots
My biggest complaint about the Heer et al. article is that it doesn’t mention what are perhaps the three most important kinds of graphs: dot plots, line plots, and scatterplots. See here here for a dotplot (from Jeff and Justin), and here for some line plots and scatterplots. (I just picked these for convenience; there are dozens more in Red State, Blue State and all over the place in the statistical literature.) Perhaps the authors felt that readers would be already familiar with these ideas and didn’t need to see them again. But I think, No, the readers do need to see these again! A clearer understanding of line plots would’ve been a big help in making Figure 1C, for example. And some dot plotting principles would’ve helped with Figure 4C (coming up with an ordering more sensible than alphabetical, and displaying the “KB” numbers as dots on a scale; as is, you can pretty much only read the size of each number, which really means we’re seeing the numbers on a very crude logarithmic scale).
Do I have anything constructive to say here?
OK, OK, I’m not trying to be a grump. Different people have different perspectives, and that’s fine. My point, I think, is that there’s something missing in many discussions–even well-informed discussions–of visualization. What’s missing is the link from the substantive questions (what are the reasons for making the graph in the first place?) and the details of the graph. It’s a weakness of our software, and of our conceptual frameworks for thinking about graphs, that we don’t usually have a systematic way of making that link. Instead we go through menus of possibilities (actual forced options on computer packages, or mental menus in which we make choices based on what we’ve seen before) and then have to go back and fix things.
We should be able to do better. I’m not faulting Heer et al. for not doing better, since I don’t have my own general solution either. Rather, I’m using their article as an opportunity to push for further thinking on all of this.
P.S. I wrote this in my standard blog style, which was to start with something I’d seen and go from there. Once it was done, I changed the title, “When thinking about visualization, how important are the details?” to the grabbier “A data visualization manifesto” (snappier than “A statistical graphics manifesto,” perhaps?) and appended the very first two paragraphs above as an intro. This should be better, right? Readers should be more interested in my point than in how I got there. I didn’t feel like revising the whole piece, but I guess I will if I want to rewrite the article for publication somewhere, which maybe I’ll do if I find the right coauthor.
Great analysis! I've been a proponent of visualization criticism for a while: we need a lot more reflection in visualization, and criticizing each other's work is a great way to do that. It also brings other perspectives into the field, like yours, which is underrepresented (visualization goes beyond statistical graphics, but we're ignoring that field at our peril, afaik).
To address your points: I think that article was meant both as a showcase for Protovis and as a way to show people that there's more than line and bar charts. The audience here are not statisticians, but people who would not otherwise venture beyond their defaults in Excel. That doesn't excuse bad designs, but I think it does mean that a slightly sub-optimal layout is secondary to introducing people to small multiples.
I agree that the choice of scaling in the employment chart is odd. It is explained if you click through to the full version, though: Total counts of unemployed persons, normalized per industry. This made more sense in the original chart (the flash graphic about 2/3 down the page), where you can see a lot of interesting seasonal patterns. A common problem in small multiples is that when your data ranges vary wildly between the small charts, you end up losing a lot of value from creating the chart in the first place. But yes, I agree, the scaling is strange.
Regarding the stock prices chart: a log scale may be the obvious choice for a statistician, but the general public does not understand that concept at all. So to properly communicate changes relative to an reference, you need to use a linear scale or risk most people misreading the chart (as an aside, I recently saw an article somewhere that explained negative numbers because many people apparently "do not recall them from school").
This may sound like I'm making excuses, but I'm just trying to put things in perspective. Your points are well taken though, and I wish we'd get more informed, precise criticism from statisticians. We sure can use it. And this kind of discussion beats "it's no longer just art" any day ;)
Andrew, I know this is not exactly what you are referring to, but our group at Duke is working on a computational ontology that links a limited subset of structured research questions (from clinical and translational research) to analytical tests (statistics, data mining, bioinformatics) and their graphical ways to represent them. very briefly, two main use cases are: (1) given a research question, which tests and graphical representation can I use? and (2) give a certain test, which research questions (out of a bank) and graphics can i use to graphically represent them. ontology re-uses portions of the grammar of graphics http://goo.gl/Z9oq and pmml http://goo.gl/TbqS . Collaborators most definitely welcome
Isn't this the sort of thing that Hadley Wickham's implementation of the grammar of graphics is attempting to address? His ggplot2 package seems to be a good way making graphics from data via statistical methods. There is always a lot of back and forth from the plot to method that got you there but the syntax and presets in ggplot2 are set up so that trying different visualization techniques is relatively painless. This means that you can concentrate on actually answering a question with your plot rather than plotting whatever is easiest to plot.
The ACM paper is definitely just a way to showcase Protovis – which if your readers are not aware is a javascript library that uses the capabilities of (very) modern browsers to draw scalable vector graphics.
Creating interactive visualizations outside of Flash was challenge prior to the arrival of this (and a few other) Javascript libraries. Now with some simple editing of the code and data it's almost trivial to create web-based viz's.
Your points about ensuring that the resulting charts are meaningful, accurate, and not just an abuse of color/interactivity because you can, still stand of course – as we know, there's plenty of room for improvement almost everywhere we see information graphics. Just because we have tools that can create interactivity like this, it doesn't mean that we must now use them in every case.
A disclaimer: I have nothing to do with the Protovis team, but I have dabbled with the software, more to see what it can do, rather then creating something particularly meaningful: http://www.datadrivenconsulting.com/2010/05/dorli…
David: I bought the ggplot2 book but haven't gone through it yet.
Alex: Thanks for the info. I took another look at the article and it only mentions Protovis once, and not until the fifth paragraph. So they must be doing something more than simply showcasing that software.
Are there well established best practices when dealing with scales and multiple graphs when discussing absolutes and not rates?
I'd used inconsistent scale mini-bar graphs as part of a table in a 2-page piece on Iraq/Afghanistan contract spending ( http://csis.org/files/publication/091105_DIIG_Cur… ). Going with the varying scale was the default given my production method, but I didn't switch it to a constant one because I was dealing with varying sizes and the smaller categories just wouldn't have been visible at all with a consistent scale. (I noted this in the caption, but doing something the wrong way and then noting it only goes so far.)
On the other hand, maybe that means I should have just switched to using the rate of change instead, then I could have gone with a consistent scale. I'm thinking I'll do that in the future.
For the clojure inclined, the incanter project looks quite promising http://data-sorcery.org/ !! One advantage is that the data can be much larger than R can handle because incanter is based on clojure, the LISP like language that targets the jvm. -A
As the authors of the aforementioned article we read this post with great interest. We would echo Robert Kosara's points, and also add a few of our own:
1. The goal of the article was to showcase more "exotic" visualizations (elephants, not mice). This was done partly to expand readers' appreciation and vocabulary for visualization and partly at the behest of our editors. We agree that the "basics" are often more appropriate and compelling, and we made sure to say so in our introduction. We hope others might also continue to point to their favorite examples online, as you have done.
2. Some of our examples could have had more explicit labels, such as the dates in Fig. 1A. Though, this visualization is intended to be used interactively, with the exact dates readable on mouseover. Similarly in Fig. 1B, we assumed most readers would interpret years as January 1, 12:00 AM. Indeed the onus is on the visualization designer to provide sufficient context to allow accurate interpretation of data; some visualization toolkits (e.g., ggplot2) do this automatically, at the expense of reduced flexibility.
3. We could have done a better job articulating the intent of each design through prose. For example, the indented tree supports interactive exploration of the hierarchy; it is more of a visual interface (a recreation of the standard file system explorer) than a visualization of file sizes. Alphabetical ordering is necessary to allow rapid scanning of file names, and the inclusion of file sizes was merely intended to serve as an example of annotating the interface with multivariate data. Similarly Fig. 1C is intended to show relative change; given the range of the data across categories, normalization is necessary to do meaningful comparison of trends.
4. Perhaps most importantly, we wholeheartedly agree that graphs should be designed with specific substantive questions in mind. Though it is rare that one enjoys being a target of criticism, a healthy and open debate around visualization designs and their context of use is surely needed. Our primary goal with the article was neither to be comprehensive nor provide the "last word", but rather to jumpstart interest in these issues and provide some additional starting points (including Wilkinson's excellent book) for interested readers to continue the journey.
— Mike, Jeff & Vadim
Mike:
I guess that just about any article is best understood in the context of its readership. To the extent that readers are already familiar with dotplots, lineplots, and scatterplots, then it would be redundant to talk about them in your article. For non-expert readers, it might be good to at least reference these basic graphs. The humble dotplot, for example (discussed at length in Cleveland's classic book) is way way underused, in my opinion. Dotplots can typically give you all the benefits of a table (easy to read, ordered categories) while conveying numerical information much more clearly.
I see your point about the tree. I still think a bit of dotplot-like display would help, but now I understand the alphabetical order. More generally, I was stuck in old-fashioned static-graphics thinking. I guess i should think of that tree as dynamic and clickable, as in my Windows explorer display.
The only thing I completely disagree with you on is Figure 1C. It would be easy to normalize while keeping compatibility: simply present unemployment rates for each group. Also, you definitely should've had these graphs go down to zero. I don't know the maximum unemployment rate of all of those industries in all those time series, but suppose it was 17%. Then you could just present all of these on a 0-20% scale. This would allow much more meaningful comparisons, I think.
P.S. I like Wilkinson's book a lot, but I'd still recommend that readers start with the basics, that is, with Cleveland. Once you get a sense of what basic graphics can do, then you're ready for more.
P.P.S. I'm glad you appreciated the criticism. As I think I made clear in my blog above, I'm glad you wrote the article and I certainly want to maintain communication between three groups that I don't think communicate enough: (a) statistical modelers, (b) statistical graphics people, (c) computer scientists. It's hard enough to get (a) and (b) to communicate–there aren't so many of us who live in both these categories, as I discuss here, but I really want do reach out to group (c).
Oops, the baseline was intended to be zero in Fig. 1C. That is a bug. I know that sounds like a cop-out at this point, but I point you to the earlier example on which this example was derived. Sorry!
I also agree that the small multiples in Fig. 1C could easily share the same scale, provided that the difference in range between the multiples is not too great. The original example (see link) compared the total number of people employed in different sectors, which varies wildly; it would be impossible to compare the trend in Animal Aquaculture (max employment: 39) with Administrative and Waste services (max employment: ~140,000).
Let this serve as a lesson in repurposing an existing visualization design without sufficiently considering the motivating question!
To (a) statistical modelers, (b) statistical graphics people, (c) computer scientists might well be added (d) graphic design people (e) cartographers (f) psychologists — and so on.
Dot plots in Cleveland's sense were introduced as dot charts. I guess no one cares much about the small terminological difference, but dot plots or dotplots have another sense in several areas of statistical science as a pointillist variation on histograms. The recipe starts with a one-dimensional scatter plot or strip plot and often continues with binning and stacking.
Many Cleveland fans are here, to an extent that his research program seems like orthodox wisdom. But graphical perception results are silent on what makes a graph more or less appealing. I'm not aware at least of a study that addresses both galvanic response and accurate perception of visualization jointly. Although, if there are such studies, I'd love to hear about them.
If a graph doesn't show untruth, its design might aim for a highest galvanic response, so long as graphical perception accuracy exceeds a low standard. A criticism could then propose graphs whose graphical perception accuracy is greater. But the critique in such a case wouldn't share in the same goals as the designer.