In the spirit of Christian Robert, I’d like to link to my own adaptive Metropolis paper (with Cristian Pasarica):
A good choice of the proposal distribution is crucial for the rapid convergence of the Metropolis algorithm. In this paper, given a family of parametric Markovian kernels, we develop an adaptive algorithm for selecting the best kernel that maximizes the expected squared jumped distance, an objective function that characterizes the Markov chain. We demonstrate the effectiveness of our method in several examples.
The key idea is to use an importance-weighted calculation to home in on a jumping kernel that maximizes expected squared jumped distance (and thus minimizes first-order correlations). We have a bunch of examples to show how it works and to show how it outperforms the more traditional approach of tuning the acceptance rate:
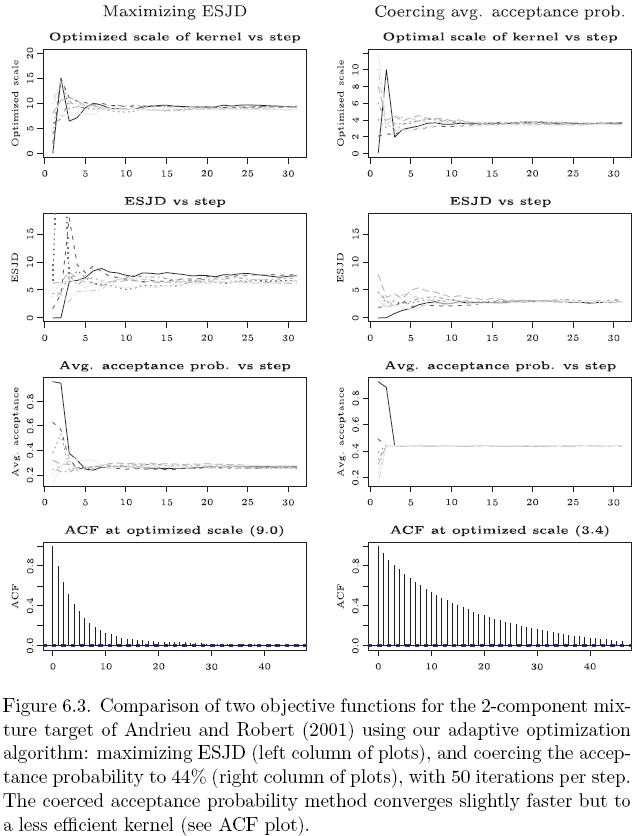
Regarding the adaptivity issue, our tack is to recognize that the adaptation will be done in stages, along with convergence monitoring. We stop adapting once approximate convergence has been reached and consider the earlier iterations as burn-in. Given what is standard practice here anyway, I don’t think we’re really losing anything in efficiency by doing things this way.
Completely adaptive algorithms are cool too, but you can do a lot of useful adaptation in this semi-static way, adapting every 100 iterations or so and then stopping the adaptation when you’ve reached a stable point.
The article will appear in Statistica Sinica.