Susan sent me this paper by Leif Nelson and Joseph Simmons:
In five studies, we [Nelson and Simmons] found that people like their names enough to unconsciously pursue consciously avoided outcomes that resemble their names. Baseball players avoid strikeouts, but players whose names begin with the strikeout-signifying letter K strike out more than others (Study 1). All students want As, but students whose names begin with letters associated with poorer performance (C and D) achieve lower grade point averages (GPAs) than do students whose names begin with A and B (Study 2), especially if they like their initials (Study 3). Because lower GPAs lead to lesser graduate schools, students whose names begin with the letters C and D attend lower-ranked law schools than students whose names begin with A and B (Study 4). Finally, in an experimental study, we manipulated
congruence between participants’ initials and the labels of prizes and found that participants solve fewer anagrams when a consolation prize shares their first initial than when it does not (Study 5). These findings provide striking evidence that unconsciously desiring negative
name-resembling performance outcomes can insidiously undermine the more conscious pursuit of positive outcomes.
I just love this kind of stuff. Here’s the data on grade point averages for students whose names begin with A, B, C, D, or other letters:
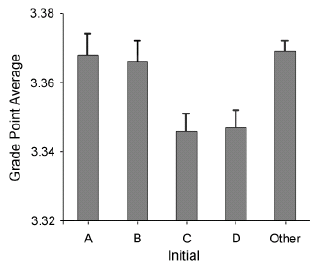
I don’t have anything to add here, beyond my comments on the paper by Pelham, Mirenberg, and Jones on dentists named Dennis (see here, here, and here). On one hand, it seems pretty implausible to me that kids whose names begin with C and D are really sabatoging themselves like this. On the other hand, hey, there are the data. An effect of 0.02 in GPA is pretty tiny, on the other hand if it were much larger I wouldn’t believe it . . . It would be interesting to see the average GPA’s for all 26 letters, also looking at both first and last names.
P.S. In a comment below, Derek posted a hypothetical improved graph with all 26 letters, I had it up, but I removed it since it’s not actually real data!
Here's a question that really ought to be considered: what effect does changing one's name (the typical case would be a woman getting married), say from a name starting with A to one starting with D, have on GPA? But I imagine it would be quite difficult to get a decent-sized sample.
A more likely cause is the relationship between names and socio-economic status of parents. Note that they had other information about gender, race, etc so why didn't they fit a a model to see if these were significant effects.
For occupations, I wonder how many they had to try before finding ones that fitted their theory.
It bothers me that they turned all the other letters into a category caled "Other". What was the reason for that? Is it because they were imprinted on a tradition of not displaying every result because it's too difficult?
I've seen similar things in data graphics: people who grew up when graphs had to be drawn painstakingly now using computers to create graphs that look like the ones they remember, even though that's no longer a limit. Look what they could have shown, in only twice as much pixel space.
(it was also naughty of them to use a bar graph format when the y-axis doesn't start at zero)
How about students whose name begins with 'F'? Surely they should be performing worse than the C's and D's?
Two potential explanations here:
1. Some variable is not included. E.g. it may well be that, I don't know, Asian surnames start with an A or B more often than Anglo-Saxon ones and Anglo-Saxons get worse earlier education or preferential access to college.
2. There is, of course, an infinite number of hypotheses (and a finite but very large number of potential datasets). In other words, datamining.
How about students whose surnames start with 'F'? Shouldn't they be performing much worse than the C's and D's?
Two potential explanations here:
1. Some relevant variable is not included in the analysis. For example, I don't know, say that Asian names start with C and D way less often compared to Anglo-Saxon surnames, and Asians get better early education and are discriminated against when it comes to college admission, perhaps due to uncertainty about the quality of the schools they attend – that way, the Asians that do end up in college will be performing better.
2. There are an infinite number of hypotheses, and a finite but very large number of original datasets. In other words, these results could be down to good old datamining.
I wonder whether they looked at year to year persistence in the baseball example. It seems to me that their small p-values may be due to aggregating 90 years of data. I'd be more convinced if this effect exists for most years.
They look at first or last initial 'K' but while first initial is a choice, for most people, last initial isn't. So I don't see the point. I actually think last initial hurts rather than helps the case.
What is interesting to me is that the editors are willing to print articles that deal with correlation and say nothing about causation. I actually think it's a good thing, a pleasant surprise.
Oops! No, sorry, I *made the data up*. All I was doing was illustrating how such a graph would look. There's no information there that you don't already have in the original graph.
I should have been clearer about that. My apologies. Of course, if anyone does actually have the data, I'd be delighted to do it for real.
Further to my last comment, the authors write in their paper:
"To test this hypothesis, we acquired a data set containing 15 years (1990–2004) of grade point averages (GPAs) for M.B.A. students graduating from a large private American university. The data set provided the students’ first initials, last initials, gender, ethnicity (coded using six categories: African American, Caucasian, East Asian, Hispanic, Indian, and other), and graduation year, and also indicated whether or not each student was a U.S. citizen."
I don't think that actual data set would be easy to acquire, unless the authors themselves are kind enough to make it available.
(it was also naughty of them to use a bar graph format when the y-axis doesn't start at zero)
Posted by: derek at November 27, 2007 3:23 PM.
That doesn't seem right. If the y-axis began at 0, we wouldn't be able to detect any variation without dramatically increasing the height of the figure. Nothing would seem special about C and D.
Noting that Fowler spent his live on grammar, I wonder if a player might be well served to changes his name to Homer Fouled.
The grading example suggests an interesting experiment where in you tell the teacher the student name is Albert Nobel; while is actual name is David Lazionne.
Come on man, see the violence inherent in the system. :)
Just a comment on the little "serifs" on the confidence intervals in the graph: I think they are visually helpful. Likely they are more helpful in situations where the graph is smaller, or imagine getting a photocopy of a copy of such a graph: the lines thin out and the additional lines that make it look like an I serve a serif-like function. The figures in many books and journals are often shrunk a bit more than is wise.
(As an aside, Chess Life magazine did a redesign a year or two ago and they took off the outside borders of the chess board in the diagrams. They aren't needed, but they got more complaint letters about this, if I recall correctly, than anything in the magazine's past.)
When I look at the graph, I keep wondering to myself what is the chance that the largest difference between any two initials is 0.02 assuming that everything is random? Is it a coincidence that A,B had the highest GPAs and C,D had the lowest?
If the y-axis began at 0, we wouldn't be able to detect any variation without dramatically increasing the height of the figure.
John, that's right, but the answer is to abandon the bar graph format. The value of a bar graph is critically dependent on the areas of the bars meaning something, which means that the ratio between two bars must be significant. If it is not, then you shouldn't use bars. In the example shown above, the authors would appear to have us believe there is something important about the ratio (3.36-3.32)/(3.34-3.32).
The proper display format for small differences in large quantities is points, not bars. Then it's okay to abandon the zero point on the axis.
You know the old Berber saying, "Every man thinks of his own fleas as gazelles."
Considering that the average GPA is 3.34 in the D group, are grades of "D" really that common? If not, than is 0.02 deviation from the all others really meaningful?
Many classrooms assign seating by alphabet. What about a correlation between sitting in the front – whether in their MBA programs or in previous schooling – and getting good grades?
What about the admissions officers at law schools who read their applications in alphabetical order? Do they get tired and less impressed as they get to their 40th application at "C" goes on? Is their pool of potential slots half size because of all the A and B names they've already accepted?