It is not unusual for statisticians to check their model with cross-validation. Last week we have seen that several replications of cross-validation reduce the standard error of mean error estimate, and that cross-validation can also be used to obtain pseudo-posteriors alike those using Bayesian statistics and bootstrap. This posting will demonstrate that the choice of prior depends on the parameters of cross-validation: a “wrong” prior may result in overfitting or underfitting according to the CV criterion. Furthermore, the number of folds in cross-validation affects the choice of the prior.
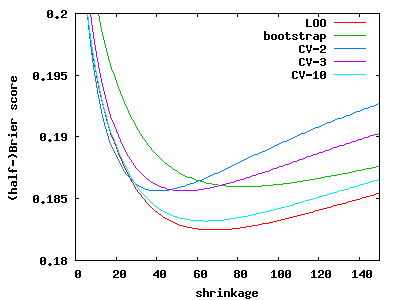
It has been recognized that the results of logistic regression and of the naive Bayes classifier are better if the weights are shrunk towards zero. Naive Bayes is a simple form of logistic regression where the weights for a multivariate logistic regression model are actually estimated in a univariate fashion: if all the variables were conditionally independent given the class, the results would be the same. The meaning of the shrinkage parameter is that we inject m cases into the data that have the same distribution in each variable as the original data, but have no association between any pair of variables – this corresponds to a variant of the usual conjugate Dirichlet prior. The usual recommendation in the context of machine learning is to use cross-validation to determine the “right” value of m, while a Bayesian would assume a prior distribution over m.
The trouble is that cross-validation itself has a parameter: the number of folds. As the graph above illustrates, the optimal value of m is 83 with predictive bootstrap (the cases that were not selected in a particular resample are used to asses the out-of-sample error), 41 with 2-fold CV, 54 with 3-fold CV, 59 with 5-fold CV, 64 with 10-fold CV, and 69 with leave-one-out. Moreover, should we use a different error measure, such as KL-divergence or classification error, the ideal amount of shrinkage would again be affected. A different data set would again imply a different amount of shrinkage.
One cannot escape assumptions. If this is so, what are reasonable assumptions? Data splitting is not an unreasonable assumption (analogous to a prior), and I find the above parameterization of shrinkage quite reasonable. But I personally feel uneasy expressing my prior as some sort of a distribution on weights. Secondly, having a more sophisticated model flunk the cross-validation test might just imply that there is a mismatch between the prior used and the prior that would be preferred by cross-validation.