What makes an observation interesting? Through the example of devious quizzes that ask you to distinguish ape art from modern art, we will investigate the fundamental idea of support vector machines: a SVM is a classifier specified in terms of weights assigned to interesting observations. This is different from most regression models in statistics, which are specified in terms of weights assigned to variables or interactions.
Building predictive models from data is a frequent pursuit of statisticians and even more frequent for machine learners and data miners. The main property of a predictive model is that we do not care much about what the model is like: we primarily care about the ability to predict the desired property of a case (instance). On the other hand, for most statistical applications of regression, the actual structure of the model is of primary interest.
Predictive models are not just an object of rigorous analysis. We have predictive models in our heads. For example, we may believe
that we can distinguish good art from bad art. Mikhail Simkin has been entertaining the public with devious quizzes. A recent example is An
artist or an ape?, where one has to classify a picture based on whether it was painted by an abstractionist or by an ape. Another
quiz is Sokal & Bricmont or Lenin?, where you have to decide if a quote is from
Fashionable Nonsense or from Lenin. There are also tests that check your ability to discern famous painters, authors and musicians from
less famous ones. The primary message of the quizzes is that the boundaries between categories are often vague. If you are interested
in how well test takers perform, Mikhail did an analysis of the True art or fake? quiz.
These quizzes bring us to another notion, which has rocked the machine learning community over the past decade: the notion of a support vector machine. The most visible originator of the methodology is Vladimir Vapnik. There are also close links to the methodology of Gaussian processes, and the work of Grace Wahba.
A SVM is nothing but a hyperplane in some space defined by the features. The hyperplane separates the cases of one class (ape pictures) from the cases of another class (painter pictures). Since there can be many hyperplanes that do separate one from the other, the optimal one is thought to be equidistant from the best ape picture and the worst painter picture. Using the `kernel trick’ we can conjure another space where individual dimensions may correspond to interactions of features, polynomial terms, or even individual instances.
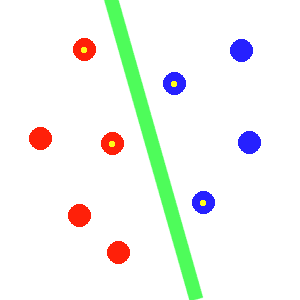
In the above image, we can see the separating green hyperplane halfway between the blue and red points. Some of the points are marked with yellow dots: those points are sufficient to define the position of the hyperplane. Also, they are the ones that constrain the position of the hyperplane. And this is the key idea of support vector machines: the model is not parameterized in terms of the weights assigned to features but in terms of weights associated with each case.
The heavily-weighted cases, the support vectors, are also interesting to look at, because of pure human curiosity. An objective of experimental design would be to do experiments that would result in new support vectors: otherwise the experiments would not be interesting – this flavor of experimental design is referred to as `active learning’ in the machine learning community. The support vectors are the cases that seem the trickiest to predict. My guess is that Mikhail intentionally selects suchcases in his quiz as to make it fun.