In a discussion of yesterday’s post on studies that don’t replicate, Nick Brown did me the time-wasting disservice of pointing out a recent press release from Psychological Science which, as you might have heard, is “the highest ranked empirical journal in psychology.”
The press release is called “Blue and Seeing Blue: Sadness May Impair Color Perception” and it describes a recently published article by Christopher Thorstenson, Adam Pazda, Andrew Elliot, which reports that “sadness impaired color perception along the blue-yellow color axis but not along the red-green color axis.”
Unfortunately the claim of interest is extremely difficult to interpret, as the authors do not seem to be aware of the principle that the difference between “significant” and “not significant” is not itself statistically significant:
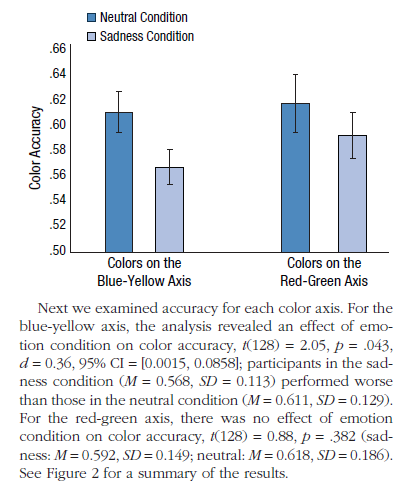
The paper also features other characteristic features of Psychological Science-style papers, including small samples of college students, lots of juicy researcher degrees of freedom in data-exclusion rules and in the choice of outcomes to analyze, and weak or vague theoretical support for the reported effects.
The theoretical claim was “maybe a reason these metaphors emerge was because there really was a connection between mood and perceiving colors in a different way,” which could be consistent with almost any connection between color perception and mood. And then once the results came out, we get this: “‘We were surprised by how specific the effect was, that color was only impaired along the blue-yellow axis,’ says Thorstenson. ‘We did not predict this specific finding, although it might give us a clue to the reason for the effect in neurotransmitter functioning.'” This is of course completely consistent with a noise-mining exercise, in that just about any pattern can fit the theory, and then the details of whatever random thing that comes up is likely to be a surprise.
It’s funny: it’s my impression that, when a scientist reports that his findings were a surprise, that’s supposed to be a positive thing. It’s not just turning the crank, it’s scientific discovery! A surprise! Like penicillin! Really, though, if something was a surprise, maybe you should take more seriously the possibility that you’re just capitalizing on chance, that you’re seeing something in one experiment (and then are motivated to find in another). It’s the scientific surprise two-step, a dance discussed by sociologist Jeremy Freese.
As usual in such settings, I’m not saying that Thorstenson et al. are wrong in their theorizing, or that their results would not show up in a more thorough study on a larger sample. I’m just saying that they haven’t really made a convincing case, as the patterns they find could well be explainable by chance alone. Their data offer essentially no evidence in support of their theory, but the theory could still be correct, just unresolvable amid the experimental noise. And, as usual, I’ll say that I’d have no problem with this sort of result being published, just without the misplaced certainty. And, if the editors of Psychological Science think this sort of theorizing is worth publishing, I think they should also be willing to publish the same thing, even if the comparisons of interest are not statistically significant.
The contest!
OK, on to the main event. After Nick alerted me to this paper, I thought I should post something on it. But my post needed a title. Here were the titles I came up with:
“Feeling Blue and Seeing Blue: Desire for a Research Breakthrough May Impair Statistics Perception”
Or,
“Stop me before I blog again”
Or,
“The difference between ‘significant’ and ‘not significant’ is enough to get published in the #1 journal in psychology”
Or,
“They keep telling me not to use ‘Psychological Science’ as a punch line but then this sort of thing comes along”
Or simply,
“This week in Psychological Science.”
But maybe you have a better suggestion?
Winner gets a free Stan sticker.
P.S. We had another one just like this a few months ago.
P.P.S. I have nothing against Christopher Thorstenson, Adam Pazda, or Andrew Elliot. I expect they’re doing their best. It’s not their fault that (a) statistical methods are what they are, (b) statistical training is what is is, and (c) the editors of Psychological Science don’t know any better. It’s all too bad, but it’s not their fault. I laugh at these studies because I’m too exhausted to cry, that’s all. And, before you feel too sorry for these guys or for the editors of Psychological Science or think I’m picking on them, remember: if they didn’t want the attention, they didn’t need to publish this work in the highest-profile journal of their field. If you put your ideas out there, you have to expect (ideally, hope) that people will point out what you did wrong.
I’m honestly surprised that Psychological Science is still publishing this sort of thing. They’re really living up to their rep, and not in a good way. PPNAS I can expect will publish just about anything, as it’s not peer-reviewed in the usual way. But Psych Science is supposed to be a real journal, and I’d expect, or at least hope, better from them.
P.P.P.S. Lots of great suggestions in the comments, but my favorite is “Psychological Science publishes another Psychological Science-type paper.”
P.P.P.P.S. I feel bad that the whole field of psychology gets tainted by this sort of thing. The trouble is that Psychological Science is the flagship journal of the Association for Psychological Science, which I think is the main society for psychology research. The problem is not haters like me that draw attention to these papers; the problem is that this sort of work is regularly endorsed and publicized by the leading journal in the field. When the Association for Psychological Science regularly releases press releases touting this kind of noise study, it does tell us something bad about the field of psychology. Not all the work in the field, not most of the work in the field, not the most important work in the field. Psychology is important and I have a huge respect for many psychology researchers. Indeed I have a huge respect for much of the research within statistics that has been conducted by psychologists. And I say, with deep respect for the field, that it’s bad news that its leading society publicizes work that is not serious and has huge, obvious flaws. Flaws that might not have been obvious 10 or even 5 years ago, when most of us were not so aware of the problems associated with the garden of forking paths, but flaws which for the past couple of years have been widely known. They should know better; indeed I’d somehow thought they’d cleaned up their act so I was surprised to see this new paper, front and center in their leading journal.
My attempt:
“Science and Seeing Science: Publication Incentives May Impair Effect Perception”
BTW I think my favorite part is the word “may” in the title. It “may” affect – but then again, it may not! The authors are more honest than you give credit for, haha.
Once in a blue moon
Psychology paper on perception of the color blue has me seeing red
Blue state of mind, red state of mind
next we’ll find out that jealous people have trace amounts of additional green pigment in their skin
“Seeing Red: Psychology Papers May Prime Homicidal Impulses in Statistically Savvy Readers”
Prime Time Blues
Psych Street Blues.
I have no entry for the competition, but I seriously wonder whether they also had an “anger condition” that they don’t tell us about, because: “Red and seeing red: Anger may impair color perception”.
I was wondering this also — as well as jealous peoples’ perception of green — but then realized that it would be silly for the authors to put all this into one paper, when they could milk three terrible, noise-fitting papers from this rich vein of inquiry.
No, they find that green is related to creativity, Lichtenfeld, Elliot, Maier & Pekrun (2012) Fertile green: Green facilitates creative performance.
http://psp.sagepub.com/content/38/6/784.long
The opening paragraph is delightful, “…until quite recently, the research conducted in this area has lacked conceptual depth … and methodological rigor”
I don’t think there should be any surprise that Psych Science continues to publish these kinds of manuscripts. Andrew Elliot is a consulting editor for the journal. Psych Science does have a new editor-in-chief, though, so maybe things will be different in the future.
Greg:
Somehow I thought I’d heard during the past year or so that Psych Science was going to clean up its act.
In the meantime, I’m hoping that a steady stream of this sort of post will encourage journalists to think twice when they see a headline-worthy claim from Psych Science or from a social science paper in the tabloids (Science, Nature, PPNAS).
The previous editor did introduce several changes. Psych Science now encourages reporting confidence intervals of standardized effect sizes and assigns badges for papers that share data or involve studies that were pre-registerd. While well-intentioned (and sometimes useful), I don’t think these efforts are going to (or did) do very much because the deeper problems involve measurement and relating data to theory. I will send a note to the interim editor-in-chief advising him to take a look at the discussion here.
They’ve been encouraging (sometimes requiring) CIs and other effect size measures for decades, but I see CIs used as dichotomous tests, in or out, plausible or not, with the confidence level fixed. Of course there’s a duality between test and CIs. Moreover, the only justification ever given is long-term coverage. Severity indications, which I prefer, lead to essentially several intervals and with an evidential interpretation.
Only if they manage to find something significant.
Another day, another scientific breakthrough in Psych Science.
OR
Uncovering the meaning of life, one p-value at a time.
+1
“Feeling significant and seeing significance: Why embodiment researchers are great fellas”
The other “feature” of surprise is that it seems to rule out bias (in the usual, not statistical, sense). There’s a (quite reasonable) idea in the world that a scientists will inevitably find evidence for his pet theory as long as he looks hard enough. When scientists express surprise, then, it means that they weren’t just confirming what they already believed, so the results are evidence, not bias. I actually think there’s something to this, but only in the case where scientist who has a history of claiming A presents evidence against A.
But the more common type of researcher bias is in favor not of a theory per se but in favor of publication. And here you’re totally right–surprise points towards researchers’ bias, not against it.
Adam:
Yes, in some ways this is the worst of all possible worlds. They have a bias to find support of some version of their scientific model, but not this particular incarnation. Hence the usual story of a lottery in which just about any ticket is a winner, if interpreted creatively.
I am a psychologist and can tell you that Psychological Science is widely ridiculed in my specific field for its tendency to publish “sexy” fluff pieces like this that sometimes seem designed to get published in Psychological Science rather than to explore some important phenomenon. They still publish some great stuff from time to time but when I teach my research methods and stats classes and need to find some questionable paper to dissect I never need to go much further than the most recent issue of Psych Science. Something to be thankful for I guess.
+1
I don’t think we cam read so much into this surprise aspect. Look up “astronomer baffled”, there is an endless stream of press releases regarding space fits this theme of the surprised scientist. Yet the underlying theories never seem to be questioned. Right or wrong, there is always some adhoc explanation that can be devised.
Significanciness
There are huge chunks of psychological research that live in a self-affirming cluster of methods, measures, psychological tests along with an associated literature which, if put to scientific scrutiny, would all come tumbling down. Andrew says “It’s all too bad, but it’s not their fault”, well if you go into a field where the standards are so lacking in self-criticism, and nearly everyone is papering over it, it means something. The critique may have to come from outside, but it would also be directed at the current reliance on psych student experiments as in the replications. I updated my discussion of the Italian evolutionary theory yesterday in section 4. http://errorstatistics.com/2015/08/31/the-paradox-of-replication-and-the-vindication-of-the-p-value-but-she-can-go-deeper-i/
A lot of people seem to think that this is primarily a Psychology and/or Social Sciences thing. People recommend here that psych majors spend a little time in a “hard sciences” lab.
I don’t think that’s entirely the case. My personal experience is that the hard sciences have all kinds of similar issues perhaps ones that rely less on the p value, but still, lots of fields tend to concentrate onto hot topics that are sexy, and where there’s no real way to make any hard conclusions, and over-flexible models get “confirmed” even when the data shows they’re wrong (just requires a minor “theory induced” adjustment or whatever)
At least in areas I know about:
Climate models as enormous computational dynamical systems with billions of parameters
Ocean circulation models (as above)
“Smart cities” (dense networks of sensors at every street corner etc)
Solid mechanics “constitutive modeling” for specialty materials
In grad school my advisor reported going to an Air Force presentation where they said they expected to eventually outfit expensive aircraft with thousands of sensors and have a real-time exascale computer do solid mechanics calculations continuously on telemetry data to determine exactly which parts had been over-stressed or required service.
I suggested they consider the possibility that in the future their aircraft would all be cheap drones which might sometimes be cheaper to crash into the enemy after a few uses than provide in-the-field servicing.
tunnel vision, over-flexible models, and sexy funding-go-round career-making retraction-bait papers abound. Just look at the recent mass retractions where people were sending in fake contact info for the reviewers they were suggesting to the editor, and then intercepting the reviews and reviewing their own papers….
Sure, there’s a difference between outright fraud and just bad science, but increasingly I think the toxic culture of academia, funding, tenure, judging on “selectivity” of the publication venue, non-accountable anonymous review, etc etc is all pushing hard and social sciences in the same bad direction.
My experience with biology and engineering is consistent with Daniel’s opinions. They might not be as bad as psychology in general, but there is a lot of literature with lack of rigor comparable to what seems typical in psychology. That being said, these fields typically take collecting data seriously, but are often hampered by difficulty in obtaining good data despite going to a lot of trouble to get what they can.
Andrew — don’t miss this op-ed in the NYTimes that defends the field of Psychology while completely and utterly missing the point of all the criticisms. http://www.nytimes.com/2015/09/01/opinion/psychology-is-not-in-crisis.html
Alex:
See here: http://statmodeling.stat.columbia.edu/2015/09/02/to-understand-the-replication-crisis-imagine-a-world-in-which-everything-was-published/
Aha! Missed that. Well, at least I feel validated in thinking you’d have interesting comments on the article. :)
According to several Bonferroni correction variations that I know of, with two tests the 0.043 p-value (the yellow-blue mood difference p-value) is not, in fact, significant at the 0.05 level.
So frustrating – generally psychology reviewers spot these errors when they involve means. The 2×2 ANOVA is essentially the basic workhorse of experimental psychology so it surprises me that this gets past review in any psychology journal. Mind you, the same error gets through very often if the claim is about two correlations (e.g., significant r = .52 for males and non-significant r = .34 for females).
Also a shame because there are definite signs of improvement in Psychological Science.
Can you elaborate on these signs of improvement?
“What color is your p?”
Feel free to suggest subtitles–maybe something including “blue.”
This is definitely the best one!
Simply a blue p – more fantasy than science.
“He confirmed that the Bloop [blue p] really was just an icequake — and it turns out that’s kind of what they always thought it was. The theory of a giant animal making noises loud enough to be heard across the Pacific was more fantasy than science.”
http://www.wired.co.uk/news/archive/2012-11/29/bloop-mystery-not-solved-sort-of
(Yes, I’ll get back to work now.)
Just for fun, I calculated the p-value for the condition X color interaction; it is p = .62. Here lies the conceptual source of the error: The effect size for blue-yellow is reported as d = 0.36 (in the paragraph quoted by Andrew), and the effect size for red-green is … not reported! (It’s actually about 0.15) Implicitly, non-significant means “no effect” means zero effect size, so nothing to report!
This is all understandable, though — I know when I’m blue I avoid interactions.
Blue about blue BLUEs of blue
“I believe virtually everything I read, and I think that is what makes me more of a selective human than someone who doesn’t believe anything.” – David St. Hubbins, This is Spinal Tap (1984).
This week in Psychological Science: Red and blue look different, and I dont know what an interaction is.
How about something Ritzy — “If you’re blue and you don’t know where to publish to, why don’t you publish in Psych Science?”
Perhaps this is an elaborate job posting for someone to teach introductory stats in the Department of Psychology at the University of Rochester. First one to spot the error gets the position?
Even NPR is now profiling this “finding”. Very sad.
http://www.npr.org/sections/health-shots/2015/09/05/437477612/when-youve-got-the-blues-you-have-a-hard-time-seeing-blue?utm_source=facebook.com&utm_medium=social&utm_campaign=npr&utm_term=nprnews&utm_content=20150905
Yeah, next step is a This American Life segment, produced by Michael LaCour.
I may have to steal one of these contributions for an as-yet-unnamed blogpost.
http://eusa-riddled.blogspot.com/2015/09/no-title-yet-hah.html
The paper has now (finally) been retracted.
http://pss.sagepub.com/content/26/11/1822
Kudos to the journal and authors for at least correcting the obvious error.
Authors and Journal Commit Publication Bias, Blog Endorses It