That's a gigantic effect. Is there some sort of award for finding the largest effect "in plain sight" that (to my knowledge) nobody has noticed before?
I would bet quite a bit there is a data quality error here. The top names from 2006 (when the plot was made):
Not that it is impossible for the plot to be true given this information, but it defies plausibility.
I got curious (or I'm procrastinating; take your pick). The data are readily available at the social security administration site http://www.ssa.gov/cgi-bin/popularnames.cgi
and 2006 does indeed look like this.
Interestingly, of the top 10 names only Ethan (#4) has the final n. But lower down we get to long strings in the rankings:
19 John
20 Logan
21 Christian
22 Jonathan
23 Nathan
24 Benjamin
25 (Samuel)
26 Dylan
27 Brandon
…
35 Jackson
36 (Jack)
37 Kevin
38 Gavin
39 Mason
40 (Isaiah)
41 Austin
42 Evan
43 (Luke)
44 Aidan
45 Justin
46 Jordan
47 (Robert)
48 (Isaac)
49 Jayden
50 Landon
The effect isn't concentrated: "n" names are 35% of the people with the top 1000 names and 34% of the names themselves.
We need to know the actual name frequencies to do it correctly though, not just the ranks.
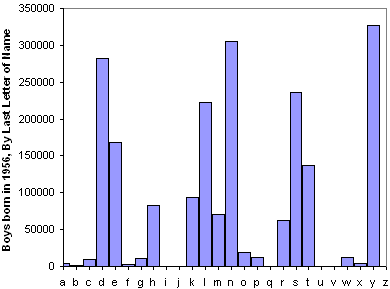
It has a lot to do with the fact that boys names aren't clumping at the top as much as they used to. Here's a comparison of the top 50 names from 1956 and 2006:
great plots, guys. I guess I would lose the bet I made above! Seems to be a valid effect. It's amazing – only 2 Ns in the top 18 and then 19 out of the next 32!!!
Also, it's not just the frequencies of various names; the makeup of the top 1000 names has also changed. Here's what happens if I say one boy had each name:
That can't be right. It seems like every other boy name starts with J—Jason, Jeremy, John, etc.—but here there are no Js and a bajillion Ns?
yolio: this is about the last letter, not the first. Basically no names end in J.
It's absolutely real. I created those graphs two years ago based on the then-most-recent 2006 data. The movement toward -n is unabated; in 2008, over 36% of American boys with a top-1000 name received an -n name.
It's reasonable to suppose that the concentration is at least as high outside the top 1000, given that few of the names at the very top of the chart end in -n. Also, the contemporary -n names lend themselves to creative respellings which tend to scatter them across the lower rankings.
Extra bonus data point: 40 of the top 1000 boys' names this year rhyme with Aidan.
how about – this is all a load of c*#@
just how many boys do you know with names beginning with 'y'…..please look at ALL the the data before cherrypicking the bits that interest you…..
oh damn my bad – last letter not first sorry
Wow is right.
Laura, I was just noticing that last little "Aiden" observation with some astonishment! There are eight in the top 100:
Amazingly (well, amazing to me), there are only five different-sounding names on that list.
Born in 57, when Bryan was only 115th. In the past 50 years, it's been in the top 100.
I see the alternate spelling has been in the top 10. And the past three years, my spelling has actually gotten more popular.
You could do a similar histograms for English words in general, and you'd find similar variation in distribution for reasons having to do with phonology, spelling conventions, and the history of the language. For instance, I'm betting there are relatively few words ending in j, u or z. This makes the small number of -z names less unusual, and the small number of -p names and -g names more unusual. It would be interesting to normalize the baby name data against the all-words distribution, and see what that shows.
I have noticed, at least in my area, that girls names tend to end in "a". I wonder if a study of their names would show a similar pattern.
Could it possibly be a consequence of the fact that the overwhelming majority of patronymics (name-son) end in "n", and that patronymics as given names have become more popular?
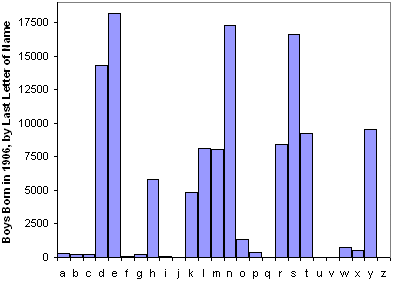
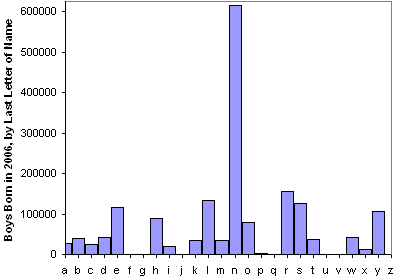
That's a gigantic effect. Is there some sort of award for finding the largest effect "in plain sight" that (to my knowledge) nobody has noticed before?
I would bet quite a bit there is a data quality error here. The top names from 2006 (when the plot was made):
1Jacob
2Michael
3Joshua
4Ethan
5Matthew
6Daniel
7Christopher
8Andrew
9Anthony
10William
11Joseph
12Alexander
13David
14Ryan
15Noah
16James
17Nicholas
18Tyler
19Logan
20John
(list copied from comments on the blog).
Only 1 N in the top 10 and 4 in the top 20.
Not that it is impossible for the plot to be true given this information, but it defies plausibility.
I got curious (or I'm procrastinating; take your pick). The data are readily available at the social security administration site
http://www.ssa.gov/cgi-bin/popularnames.cgi
and 2006 does indeed look like this.
Interestingly, of the top 10 names only Ethan (#4) has the final n. But lower down we get to long strings in the rankings:
19 John
20 Logan
21 Christian
22 Jonathan
23 Nathan
24 Benjamin
25 (Samuel)
26 Dylan
27 Brandon
…
35 Jackson
36 (Jack)
37 Kevin
38 Gavin
39 Mason
40 (Isaiah)
41 Austin
42 Evan
43 (Luke)
44 Aidan
45 Justin
46 Jordan
47 (Robert)
48 (Isaac)
49 Jayden
50 Landon
The effect isn't concentrated: "n" names are 35% of the people with the top 1000 names and 34% of the names themselves.
We need to know the actual name frequencies to do it correctly though, not just the ranks.
It has a lot to do with the fact that boys names aren't clumping at the top as much as they used to. Here's a comparison of the top 50 names from 1956 and 2006:
http://img61.imageshack.us/img61/2006/namecount.p…
Here are the top 1000 normalized (on the left) so you can compare the fatness of the tails.
http://img208.imageshack.us/img208/2575/namecount…
great plots, guys. I guess I would lose the bet I made above! Seems to be a valid effect. It's amazing – only 2 Ns in the top 18 and then 19 out of the next 32!!!
Also, it's not just the frequencies of various names; the makeup of the top 1000 names has also changed. Here's what happens if I say one boy had each name:
http://img254.imageshack.us/img254/3188/namecount…
That can't be right. It seems like every other boy name starts with J—Jason, Jeremy, John, etc.—but here there are no Js and a bajillion Ns?
yolio: this is about the last letter, not the first. Basically no names end in J.
It's absolutely real. I created those graphs two years ago based on the then-most-recent 2006 data. The movement toward -n is unabated; in 2008, over 36% of American boys with a top-1000 name received an -n name.
It's reasonable to suppose that the concentration is at least as high outside the top 1000, given that few of the names at the very top of the chart end in -n. Also, the contemporary -n names lend themselves to creative respellings which tend to scatter them across the lower rankings.
Extra bonus data point: 40 of the top 1000 boys' names this year rhyme with Aidan.
how about – this is all a load of c*#@
just how many boys do you know with names beginning with 'y'…..please look at ALL the the data before cherrypicking the bits that interest you…..
oh damn my bad – last letter not first sorry
Wow is right.
Laura, I was just noticing that last little "Aiden" observation with some astonishment! There are eight in the top 100:
11 Jayden
16 Aiden
51 Brayden
76 Hayden
88 Jaden
91 Ayden
95 Caden
99 Kaden
Amazingly (well, amazing to me), there are only five different-sounding names on that list.
Born in 57, when Bryan was only 115th. In the past 50 years, it's been in the top 100.
I see the alternate spelling has been in the top 10. And the past three years, my spelling has actually gotten more popular.
You could do a similar histograms for English words in general, and you'd find similar variation in distribution for reasons having to do with phonology, spelling conventions, and the history of the language. For instance, I'm betting there are relatively few words ending in j, u or z. This makes the small number of -z names less unusual, and the small number of -p names and -g names more unusual. It would be interesting to normalize the baby name data against the all-words distribution, and see what that shows.
I have noticed, at least in my area, that girls names tend to end in "a". I wonder if a study of their names would show a similar pattern.
Could it possibly be a consequence of the fact that the overwhelming majority of patronymics (name-son) end in "n", and that patronymics as given names have become more popular?